 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA THz Video SAR Imaging Algorithm Based on Chirp Scaling
Sep 19, 2022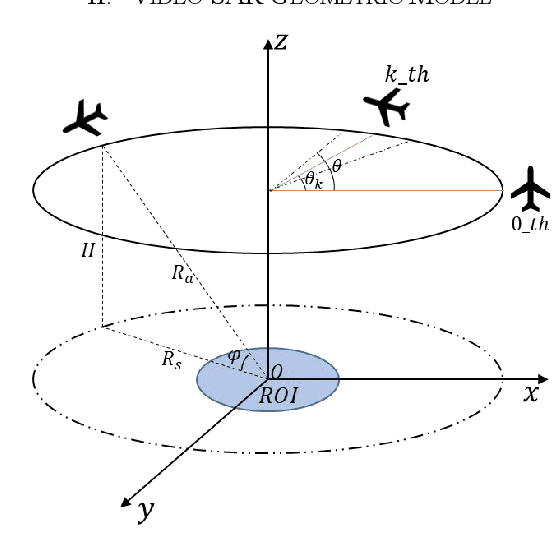
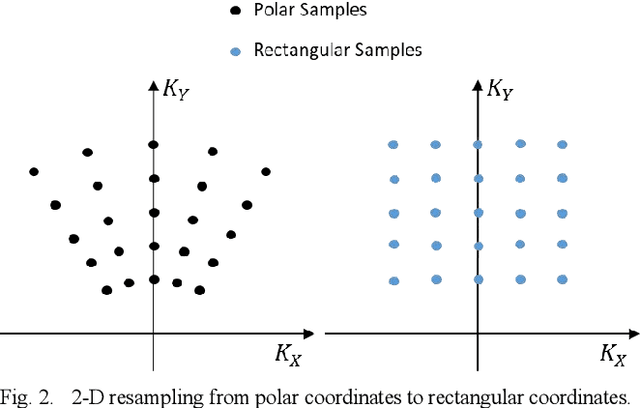
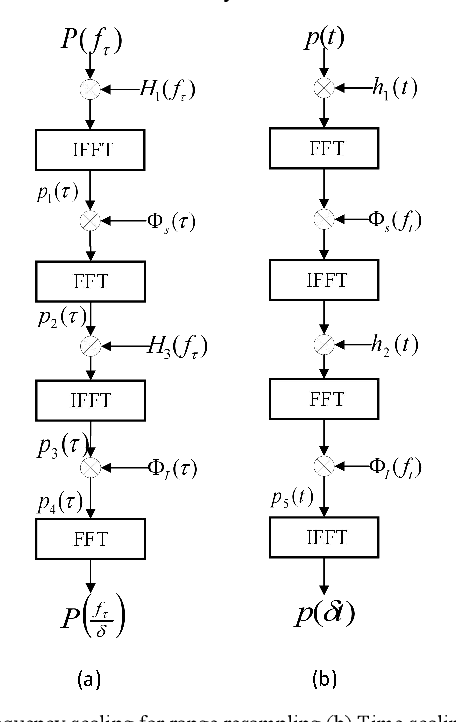
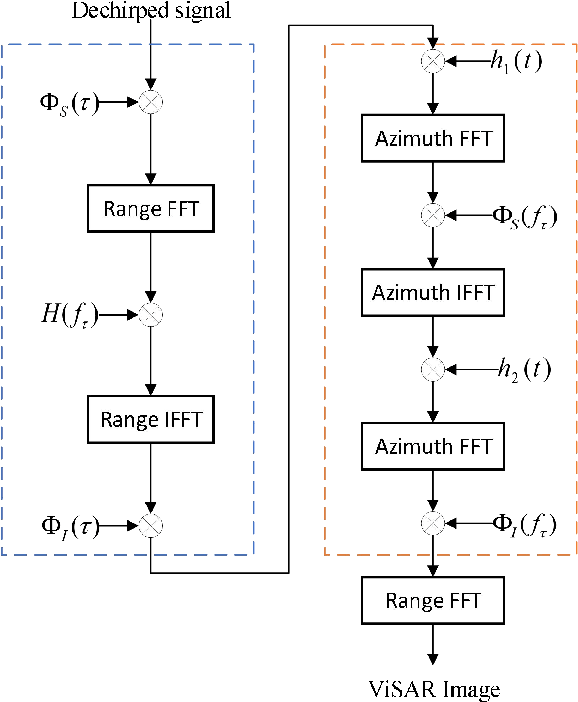
In video synthetic aperture radar (SAR) imaging mode, the polar format algorithm (PFA) is more computational effective than the backprojection algorithm (BPA). However, the two-dimensional (2-D) interpolation in PFA greatly affects its computational speed, which is detrimental to the real-time imaging of video SAR. In this paper, a terahertz (THz) video SAR imaging algorithm based on chirp scaling is proposed, which utilizes the small synthetic angular feature of THz SAR and the inherent property of linear frequency modulation. Then, two-step chirp scaling is used to replace the 2-D interpolation in the PFA to obtain a similar focusing effect, but with a faster operation. Point target simulation is used to verify the effectiveness of the proposed method.
Multiple Domain Cyberspace Attack and Defense Game Based on Reward Randomization Reinforcement Learning
May 23, 2022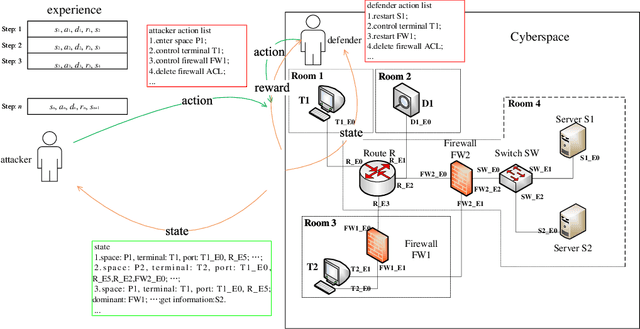

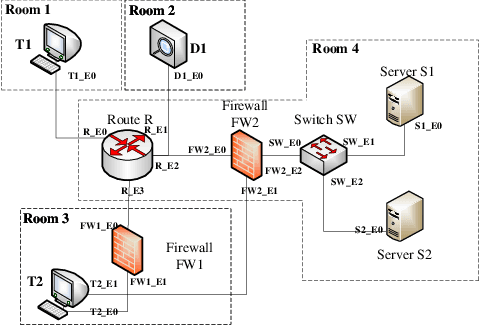
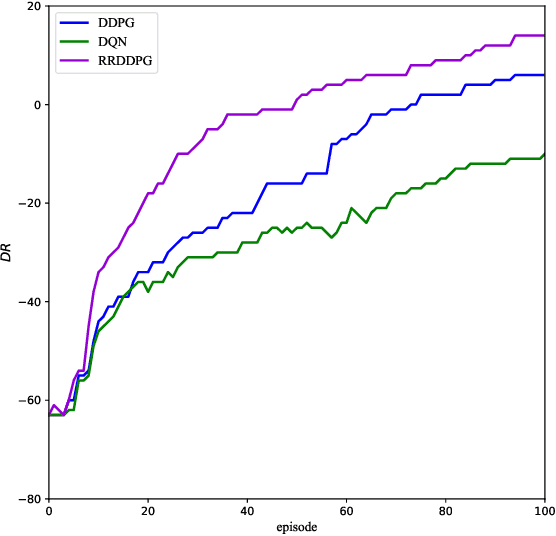
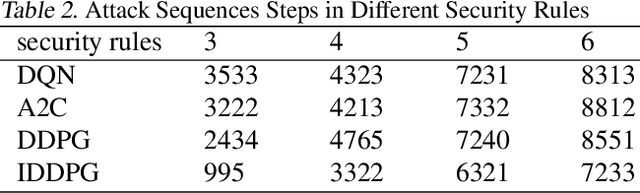
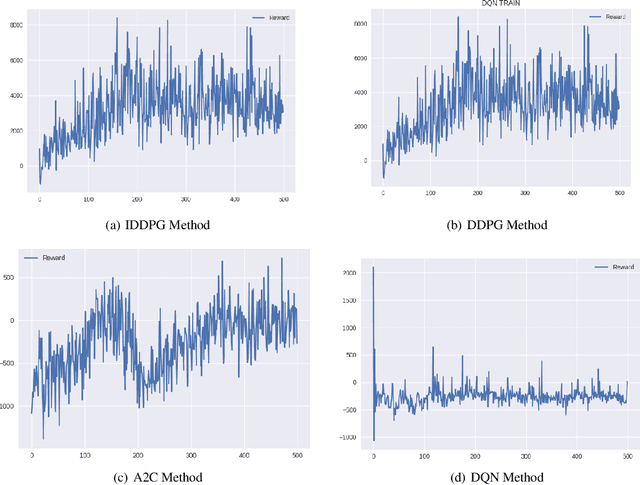
The existing network attack and defense method can be regarded as game, but most of the game only involves network domain, not multiple domain cyberspace. To address this challenge, this paper proposed a multiple domain cyberspace attack and defense game model based on reinforcement learning. We define the multiple domain cyberspace include physical domain, network domain and digital domain. By establishing two agents, representing the attacker and the defender respectively, defender will select the multiple domain actions in the multiple domain cyberspace to obtain defender's optimal reward by reinforcement learning. In order to improve the defense ability of defender, a game model based on reward randomization reinforcement learning is proposed. When the defender takes the multiple domain defense action, the reward is randomly given and subject to linear distribution, so as to find the better defense policy and improve defense success rate. The experimental results show that the game model can effectively simulate the attack and defense state of multiple domain cyberspace, and the proposed method has a higher defense success rate than DDPG and DQN.
KGRGRL: A User's Permission Reasoning Method Based on Knowledge Graph Reward Guidance Reinforcement Learning
May 16, 2022
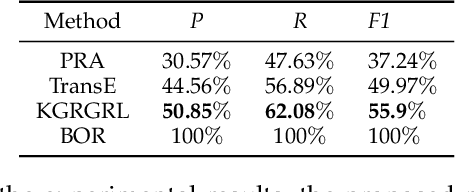
In general, multiple domain cyberspace security assessments can be implemented by reasoning user's permissions. However, while existing methods include some information from the physical and social domains, they do not provide a comprehensive representation of cyberspace. Existing reasoning methods are also based on expert-given rules, resulting in inefficiency and a low degree of intelligence. To address this challenge, we create a Knowledge Graph (KG) of multiple domain cyberspace in order to provide a standard semantic description of the multiple domain cyberspace. Following that, we proposed a user's permissions reasoning method based on reinforcement learning. All permissions in cyberspace are represented as nodes, and an agent is trained to find all permissions that user can have according to user's initial permissions and cyberspace KG. We set 10 reward setting rules based on the features of cyberspace KG in the reinforcement learning of reward information setting, so that the agent can better locate user's all permissions and avoid blindly finding user's permissions. The results of the experiments showed that the proposed method can successfully reason about user's permissions and increase the intelligence level of the user's permissions reasoning method. At the same time, the F1 value of the proposed method is 6% greater than that of the Translating Embedding (TransE) method.
Discover the Hidden Attack Path in Multi-domain Cyberspace Based on Reinforcement Learning
Apr 15, 2021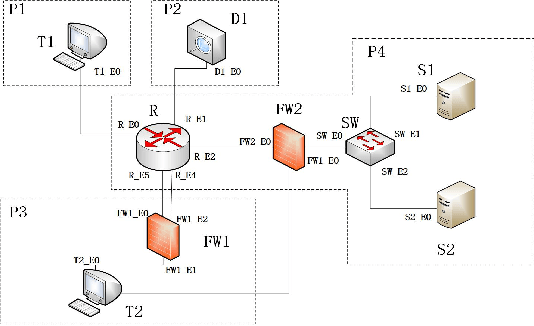

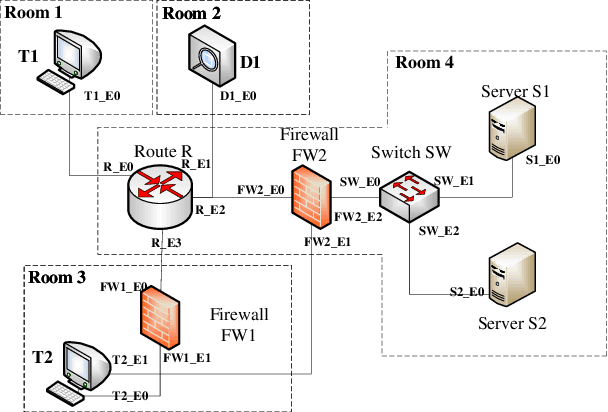
In this work, we present a learning-based approach to analysis cyberspace security configuration. Unlike prior methods, our approach has the ability to learn from past experience and improve over time. In particular, as we train over a greater number of agents as attackers, our method becomes better at discovering hidden attack paths for previously methods, especially in multi-domain cyberspace. To achieve these results, we pose discovering attack paths as a Reinforcement Learning (RL) problem and train an agent to discover multi-domain cyberspace attack paths. To enable our RL policy to discover more hidden attack paths and shorter attack paths, we ground representation introduction an multi-domain action select module in RL. Our objective is to discover more hidden attack paths and shorter attack paths by our proposed method, to analysis the weakness of cyberspace security configuration. At last, we designed a simulated cyberspace experimental environment to verify our proposed method, the experimental results show that our method can discover more hidden multi-domain attack paths and shorter attack paths than existing baseline methods.
Multi-Modal Coreference Resolution with the Correlation between Space Structures
Sep 01, 2018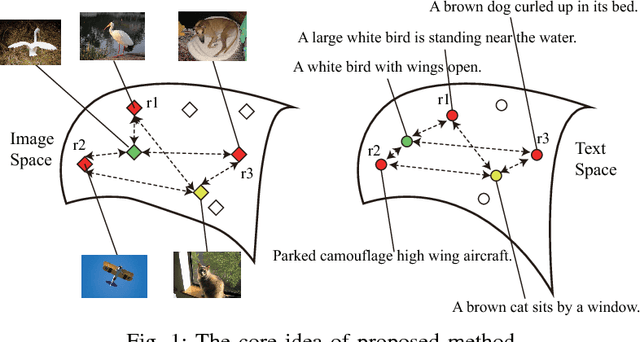
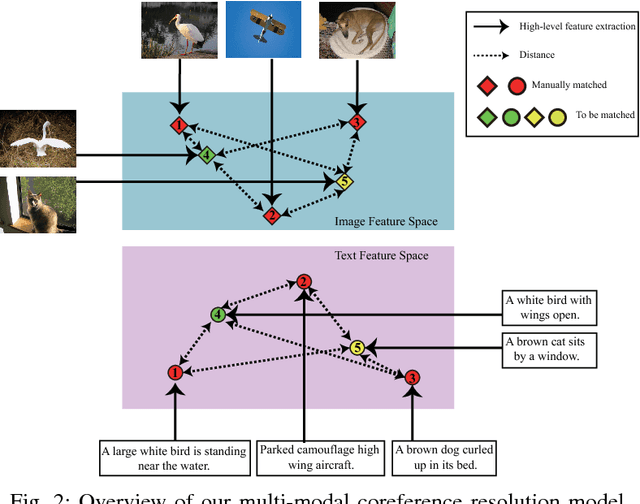
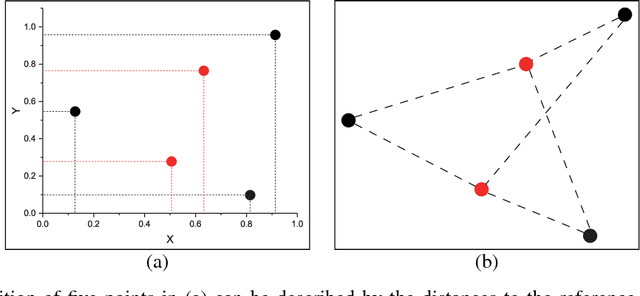
Multi-modal data is becoming more common in big data background. Finding the semantically similar objects from different modality is one of the heart problems of multi-modal learning. Most of the current methods try to learn the inter-modal correlation with extrinsic supervised information, while intrinsic structural information of each modality is neglected. The performance of these methods heavily depends on the richness of training samples. However, obtaining the multi-modal training samples is still a labor and cost intensive work. In this paper, we bring a extrinsic correlation between the space structures of each modalities in coreference resolution. With this correlation, a semi-supervised learning model for multi-modal coreference resolution is proposed. We firstly extract high-level features of images and text, then compute the distances of each object from some reference points to build the space structure of each modality. With a shared reference point set, the space structures of each modality are correlated. We employ the correlation to build a commonly shared space that the semantic distance between multi-modal objects can be computed directly. The experiments on two multi-modal datasets show that our model performs better than the existing methods with insufficient training data.