 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausalTAD: Causal Implicit Generative Model for Debiased Online Trajectory Anomaly Detection
Dec 25, 2024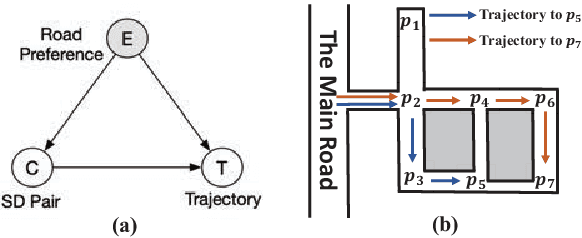
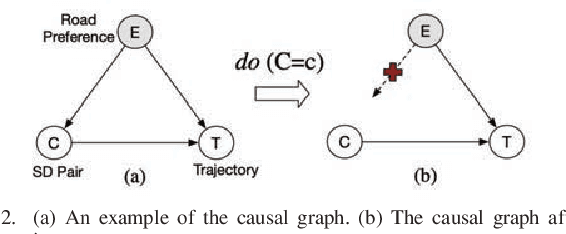
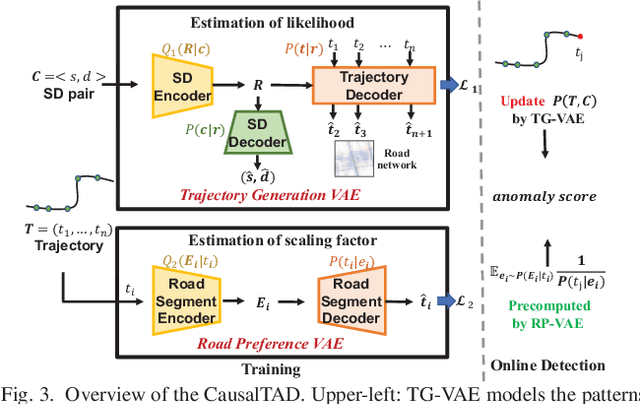
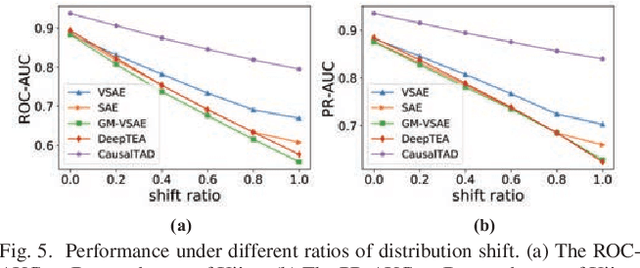
Trajectory anomaly detection, aiming to estimate the anomaly risk of trajectories given the Source-Destination (SD) pairs, has become a critical problem for many real-world applications. Existing solutions directly train a generative model for observed trajectories and calculate the conditional generative probability $P({T}|{C})$ as the anomaly risk, where ${T}$ and ${C}$ represent the trajectory and SD pair respectively. However, we argue that the observed trajectories are confounded by road network preference which is a common cause of both SD distribution and trajectories. Existing methods ignore this issue limiting their generalization ability on out-of-distribution trajectories. In this paper, we define the debiased trajectory anomaly detection problem and propose a causal implicit generative model, namely CausalTAD, to solve it. CausalTAD adopts do-calculus to eliminate the confounding bias of road network preference and estimates $P({T}|do({C}))$ as the anomaly criterion. Extensive experiments show that CausalTAD can not only achieve superior performance on trained trajectories but also generally improve the performance of out-of-distribution data, with improvements of $2.1\% \sim 5.7\%$ and $10.6\% \sim 32.7\%$ respectively.
Whole Page Unbiased Learning to Rank
Oct 19, 2022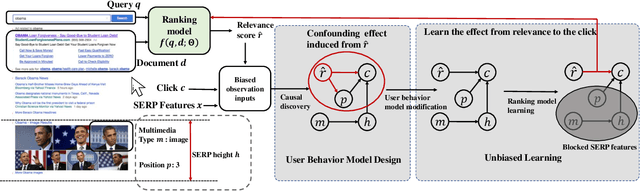
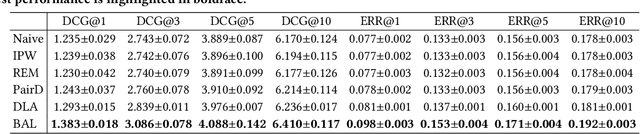
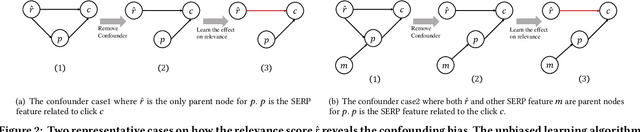
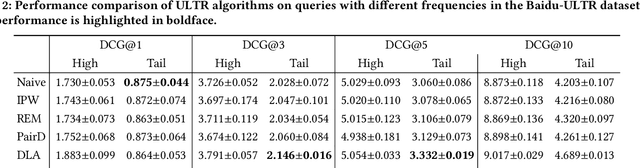
The page presentation biases in the information retrieval system, especially on the click behavior, is a well-known challenge that hinders improving ranking models' performance with implicit user feedback. Unbiased Learning to Rank~(ULTR) algorithms are then proposed to learn an unbiased ranking model with biased click data. However, most existing algorithms are specifically designed to mitigate position-related bias, e.g., trust bias, without considering biases induced by other features in search result page presentation(SERP). For example, the multimedia type may generate attractive bias. Unfortunately, those biases widely exist in industrial systems and may lead to an unsatisfactory search experience. Therefore, we introduce a new problem, i.e., whole-page Unbiased Learning to Rank(WP-ULTR), aiming to handle biases induced by whole-page SERP features simultaneously. It presents tremendous challenges. For example, a suitable user behavior model (user behavior hypothesis) can be hard to find; and complex biases cannot be handled by existing algorithms. To address the above challenges, we propose a Bias Agnostic whole-page unbiased Learning to rank algorithm, BAL, to automatically discover and mitigate the biases from multiple SERP features with no specific design. Experimental results on a real-world dataset verify the effectiveness of the BAL.
A Large Scale Search Dataset for Unbiased Learning to Rank
Jul 07, 2022

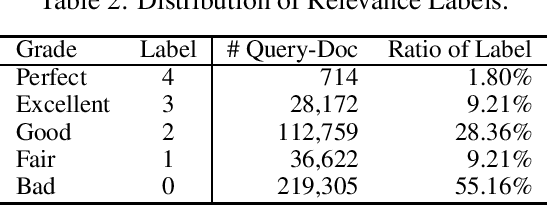

The unbiased learning to rank (ULTR) problem has been greatly advanced by recent deep learning techniques and well-designed debias algorithms. However, promising results on the existing benchmark datasets may not be extended to the practical scenario due to the following disadvantages observed from those popular benchmark datasets: (1) outdated semantic feature extraction where state-of-the-art large scale pre-trained language models like BERT cannot be exploited due to the missing of the original text;(2) incomplete display features for in-depth study of ULTR, e.g., missing the displayed abstract of documents for analyzing the click necessary bias; (3) lacking real-world user feedback, leading to the prevalence of synthetic datasets in the empirical study. To overcome the above disadvantages, we introduce the Baidu-ULTR dataset. It involves randomly sampled 1.2 billion searching sessions and 7,008 expert annotated queries, which is orders of magnitude larger than the existing ones. Baidu-ULTR provides:(1) the original semantic feature and a pre-trained language model for easy usage; (2) sufficient display information such as position, displayed height, and displayed abstract, enabling the comprehensive study of different biases with advanced techniques such as causal discovery and meta-learning; and (3) rich user feedback on search result pages (SERPs) like dwelling time, allowing for user engagement optimization and promoting the exploration of multi-task learning in ULTR. In this paper, we present the design principle of Baidu-ULTR and the performance of benchmark ULTR algorithms on this new data resource, favoring the exploration of ranking for long-tail queries and pre-training tasks for ranking. The Baidu-ULTR dataset and corresponding baseline implementation are available at https://github.com/ChuXiaokai/baidu_ultr_dataset.