 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangled Graph Representation Based on Substructure-Aware Graph Optimal Matching Kernel Convolutional Networks
Apr 23, 2025



Graphs effectively characterize relational data, driving graph representation learning methods that uncover underlying predictive information. As state-of-the-art approaches, Graph Neural Networks (GNNs) enable end-to-end learning for diverse tasks. Recent disentangled graph representation learning enhances interpretability by decoupling independent factors in graph data. However, existing methods often implicitly and coarsely characterize graph structures, limiting structural pattern analysis within the graph. This paper proposes the Graph Optimal Matching Kernel Convolutional Network (GOMKCN) to address this limitation. We view graphs as node-centric subgraphs, where each subgraph acts as a structural factor encoding position-specific information. This transforms graph prediction into structural pattern recognition. Inspired by CNNs, GOMKCN introduces the Graph Optimal Matching Kernel (GOMK) as a convolutional operator, computing similarities between subgraphs and learnable graph filters. Mathematically, GOMK maps subgraphs and filters into a Hilbert space, representing graphs as point sets. Disentangled representations emerge from projecting subgraphs onto task-optimized filters, which adaptively capture relevant structural patterns via gradient descent. Crucially, GOMK incorporates local correspondences in similarity measurement, resolving the trade-off between differentiability and accuracy in graph kernels. Experiments validate that GOMKCN achieves superior accuracy and interpretability in graph pattern mining and prediction. The framework advances the theoretical foundation for disentangled graph representation learning.
EventSum: A Large-Scale Event-Centric Summarization Dataset for Chinese Multi-News Documents
Dec 16, 2024



In real life, many dynamic events, such as major disasters and large-scale sports events, evolve continuously over time. Obtaining an overview of these events can help people quickly understand the situation and respond more effectively. This is challenging because the key information of the event is often scattered across multiple documents, involving complex event knowledge understanding and reasoning, which is under-explored in previous work. Therefore, we proposed the Event-Centric Multi-Document Summarization (ECS) task, which aims to generate concise and comprehensive summaries of a given event based on multiple related news documents. Based on this, we constructed the EventSum dataset, which was constructed using Baidu Baike entries and underwent extensive human annotation, to facilitate relevant research. It is the first large scale Chinese multi-document summarization dataset, containing 5,100 events and a total of 57,984 news documents, with an average of 11.4 input news documents and 13,471 characters per event. To ensure data quality and mitigate potential data leakage, we adopted a multi-stage annotation approach for manually labeling the test set. Given the complexity of event-related information, existing metrics struggle to comprehensively assess the quality of generated summaries. We designed specific metrics including Event Recall, Argument Recall, Causal Recall, and Temporal Recall along with corresponding calculation methods for evaluation. We conducted comprehensive experiments on EventSum to evaluate the performance of advanced long-context Large Language Models (LLMs) on this task. Our experimental results indicate that: 1) The event-centric multi-document summarization task remains challenging for existing long-context LLMs; 2) The recall metrics we designed are crucial for evaluating the comprehensiveness of the summary information.
ViViD: Video Virtual Try-on using Diffusion Models
May 20, 2024
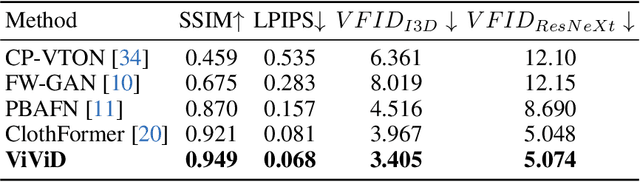


Video virtual try-on aims to transfer a clothing item onto the video of a target person. Directly applying the technique of image-based try-on to the video domain in a frame-wise manner will cause temporal-inconsistent outcomes while previous video-based try-on solutions can only generate low visual quality and blurring results. In this work, we present ViViD, a novel framework employing powerful diffusion models to tackle the task of video virtual try-on. Specifically, we design the Garment Encoder to extract fine-grained clothing semantic features, guiding the model to capture garment details and inject them into the target video through the proposed attention feature fusion mechanism. To ensure spatial-temporal consistency, we introduce a lightweight Pose Encoder to encode pose signals, enabling the model to learn the interactions between clothing and human posture and insert hierarchical Temporal Modules into the text-to-image stable diffusion model for more coherent and lifelike video synthesis. Furthermore, we collect a new dataset, which is the largest, with the most diverse types of garments and the highest resolution for the task of video virtual try-on to date. Extensive experiments demonstrate that our approach is able to yield satisfactory video try-on results. The dataset, codes, and weights will be publicly available. Project page: https://becauseimbatman0.github.io/ViViD.
CMNEE: A Large-Scale Document-Level Event Extraction Dataset based on Open-Source Chinese Military News
Apr 18, 2024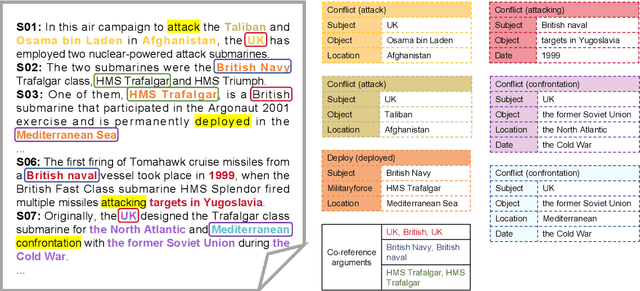
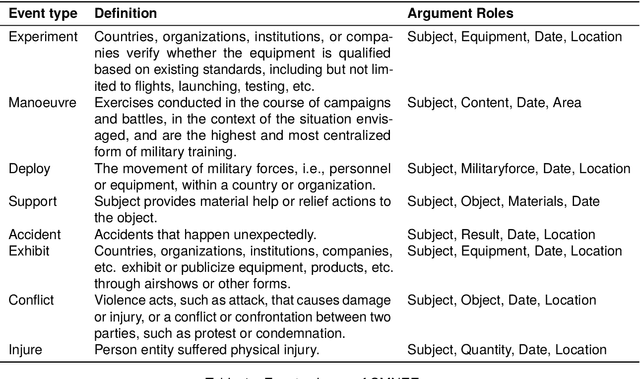
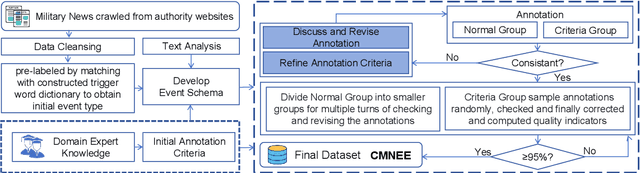

Extracting structured event knowledge, including event triggers and corresponding arguments, from military texts is fundamental to many applications, such as intelligence analysis and decision assistance. However, event extraction in the military field faces the data scarcity problem, which impedes the research of event extraction models in this domain. To alleviate this problem, we propose CMNEE, a large-scale, document-level open-source Chinese Military News Event Extraction dataset. It contains 17,000 documents and 29,223 events, which are all manually annotated based on a pre-defined schema for the military domain including 8 event types and 11 argument role types. We designed a two-stage, multi-turns annotation strategy to ensure the quality of CMNEE and reproduced several state-of-the-art event extraction models with a systematic evaluation. The experimental results on CMNEE fall shorter than those on other domain datasets obviously, which demonstrates that event extraction for military domain poses unique challenges and requires further research efforts. Our code and data can be obtained from https://github.com/Mzzzhu/CMNEE.