 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoLRM: Geometry-Aware Large Reconstruction Model for High-Quality 3D Gaussian Generation
Jun 21, 2024



In this work, we introduce the Geometry-Aware Large Reconstruction Model (GeoLRM), an approach which can predict high-quality assets with 512k Gaussians and 21 input images in only 11 GB GPU memory. Previous works neglect the inherent sparsity of 3D structure and do not utilize explicit geometric relationships between 3D and 2D images. This limits these methods to a low-resolution representation and makes it difficult to scale up to the dense views for better quality. GeoLRM tackles these issues by incorporating a novel 3D-aware transformer structure that directly processes 3D points and uses deformable cross-attention mechanisms to effectively integrate image features into 3D representations. We implement this solution through a two-stage pipeline: initially, a lightweight proposal network generates a sparse set of 3D anchor points from the posed image inputs; subsequently, a specialized reconstruction transformer refines the geometry and retrieves textural details. Extensive experimental results demonstrate that GeoLRM significantly outperforms existing models, especially for dense view inputs. We also demonstrate the practical applicability of our model with 3D generation tasks, showcasing its versatility and potential for broader adoption in real-world applications.
ViViD: Video Virtual Try-on using Diffusion Models
May 20, 2024
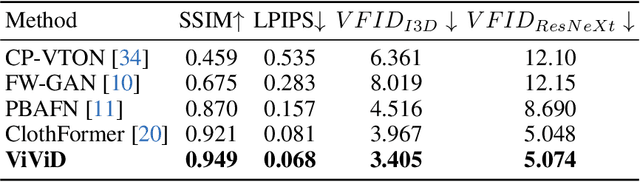


Video virtual try-on aims to transfer a clothing item onto the video of a target person. Directly applying the technique of image-based try-on to the video domain in a frame-wise manner will cause temporal-inconsistent outcomes while previous video-based try-on solutions can only generate low visual quality and blurring results. In this work, we present ViViD, a novel framework employing powerful diffusion models to tackle the task of video virtual try-on. Specifically, we design the Garment Encoder to extract fine-grained clothing semantic features, guiding the model to capture garment details and inject them into the target video through the proposed attention feature fusion mechanism. To ensure spatial-temporal consistency, we introduce a lightweight Pose Encoder to encode pose signals, enabling the model to learn the interactions between clothing and human posture and insert hierarchical Temporal Modules into the text-to-image stable diffusion model for more coherent and lifelike video synthesis. Furthermore, we collect a new dataset, which is the largest, with the most diverse types of garments and the highest resolution for the task of video virtual try-on to date. Extensive experiments demonstrate that our approach is able to yield satisfactory video try-on results. The dataset, codes, and weights will be publicly available. Project page: https://becauseimbatman0.github.io/ViViD.