 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGe$^\text{2}$mS-T: Multi-Dimensional Grouping for Ultra-High Energy Efficiency in Spiking Transformer
Apr 10, 2026Spiking Neural Networks (SNNs) offer superior energy efficiency over Artificial Neural Networks (ANNs). However, they encounter significant deficiencies in training and inference metrics when applied to Spiking Vision Transformers (S-ViTs). Existing paradigms including ANN-SNN Conversion and Spatial-Temporal Backpropagation (STBP) suffer from inherent limitations, precluding concurrent optimization of memory, accuracy and energy consumption. To address these issues, we propose Ge$^\text{2}$mS-T, a novel architecture implementing grouped computation across temporal, spatial and network structure dimensions. Specifically, we introduce the Grouped-Exponential-Coding-based IF (ExpG-IF) model, enabling lossless conversion with constant training overhead and precise regulation for spike patterns. Additionally, we develop Group-wise Spiking Self-Attention (GW-SSA) to reduce computational complexity via multi-scale token grouping and multiplication-free operations within a hybrid attention-convolution framework. Experiments confirm that our method can achieve superior performance with ultra-high energy efficiency on challenging benchmarks. To our best knowledge, this is the first work to systematically establish multi-dimensional grouped computation for resolving the triad of memory overhead, learning capability and energy budget in S-ViTs.
Emu3.5: Native Multimodal Models are World Learners
Oct 30, 2025We introduce Emu3.5, a large-scale multimodal world model that natively predicts the next state across vision and language. Emu3.5 is pre-trained end-to-end with a unified next-token prediction objective on a corpus of vision-language interleaved data containing over 10 trillion tokens, primarily derived from sequential frames and transcripts of internet videos. The model naturally accepts interleaved vision-language inputs and generates interleaved vision-language outputs. Emu3.5 is further post-trained with large-scale reinforcement learning to enhance multimodal reasoning and generation. To improve inference efficiency, we propose Discrete Diffusion Adaptation (DiDA), which converts token-by-token decoding into bidirectional parallel prediction, accelerating per-image inference by about 20x without sacrificing performance. Emu3.5 exhibits strong native multimodal capabilities, including long-horizon vision-language generation, any-to-image (X2I) generation, and complex text-rich image generation. It also exhibits generalizable world-modeling abilities, enabling spatiotemporally consistent world exploration and open-world embodied manipulation across diverse scenarios and tasks. For comparison, Emu3.5 achieves performance comparable to Gemini 2.5 Flash Image (Nano Banana) on image generation and editing tasks and demonstrates superior results on a suite of interleaved generation tasks. We open-source Emu3.5 at https://github.com/baaivision/Emu3.5 to support community research.
Proxy Target: Bridging the Gap Between Discrete Spiking Neural Networks and Continuous Control
May 30, 2025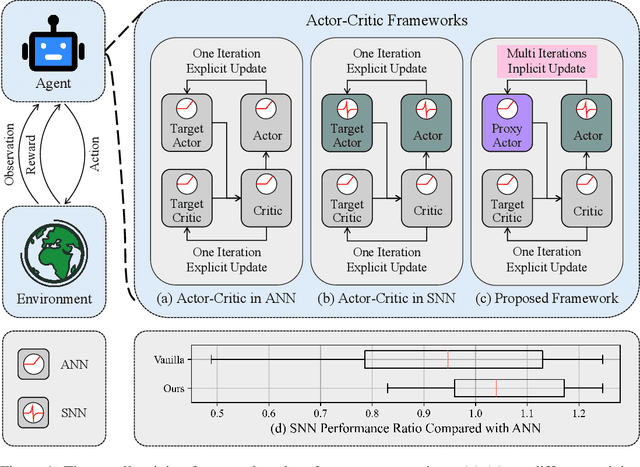
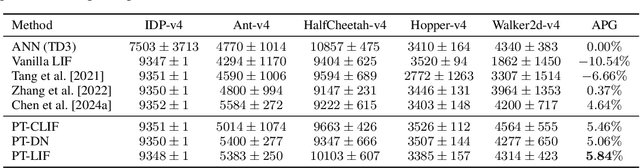
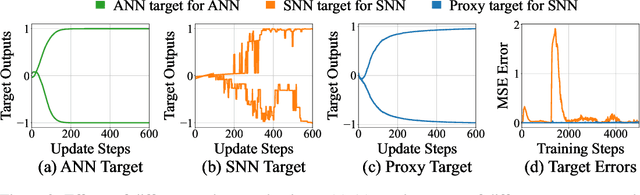

Spiking Neural Networks (SNNs) offer low-latency and energy-efficient decision making through neuromorphic hardware, making them compelling for Reinforcement Learning (RL) in resource-constrained edge devices. Recent studies in this field directly replace Artificial Neural Networks (ANNs) by SNNs in existing RL frameworks, overlooking whether the RL algorithm is suitable for SNNs. However, most RL algorithms in continuous control are designed tailored to ANNs, including the target network soft updates mechanism, which conflict with the discrete, non-differentiable dynamics of SNN spikes. We identify that this mismatch destabilizes SNN training in continuous control tasks. To bridge this gap between discrete SNN and continuous control, we propose a novel proxy target framework. The continuous and differentiable dynamics of the proxy target enable smooth updates, bypassing the incompatibility of SNN spikes, stabilizing the RL algorithms. Since the proxy network operates only during training, the SNN retains its energy efficiency during deployment without inference overhead. Extensive experiments on continuous control benchmarks demonstrate that compared to vanilla SNNs, the proxy target framework enables SNNs to achieve up to 32% higher performance across different spiking neurons. Notably, we are the first to surpass ANN performance in continuous control with simple Leaky-Integrate-and-Fire (LIF) neurons. This work motivates a new class of SNN-friendly RL algorithms tailored to SNN's characteristics, paving the way for neuromorphic agents that combine high performance with low power consumption.
Towards High-performance Spiking Transformers from ANN to SNN Conversion
Feb 28, 2025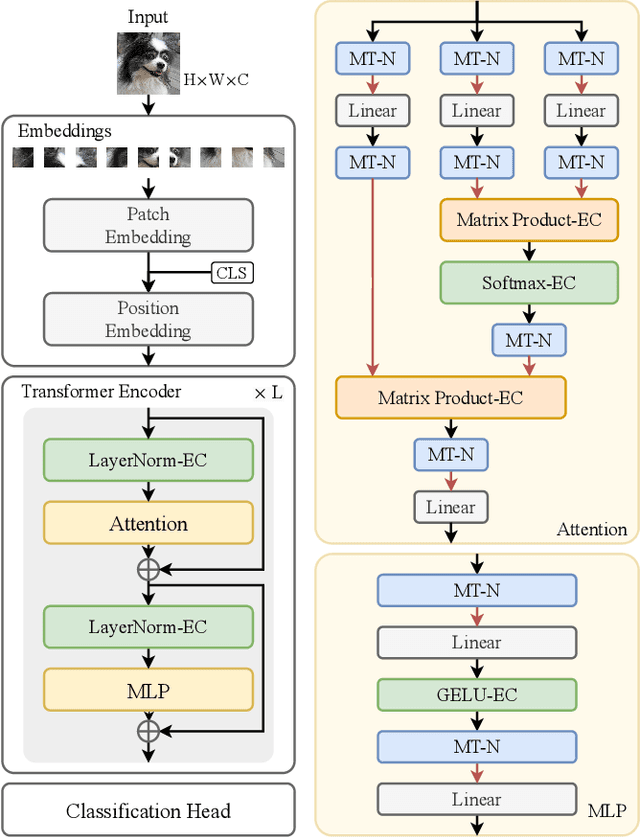
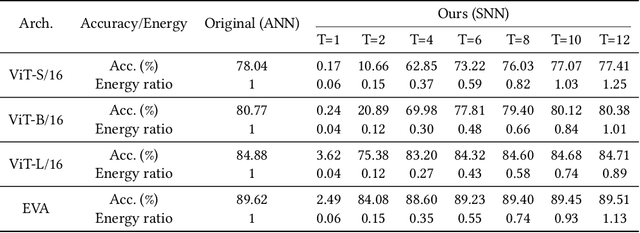
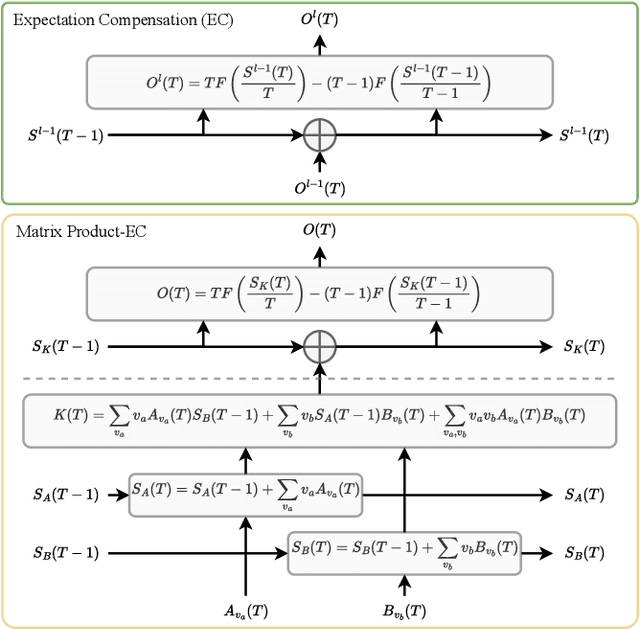
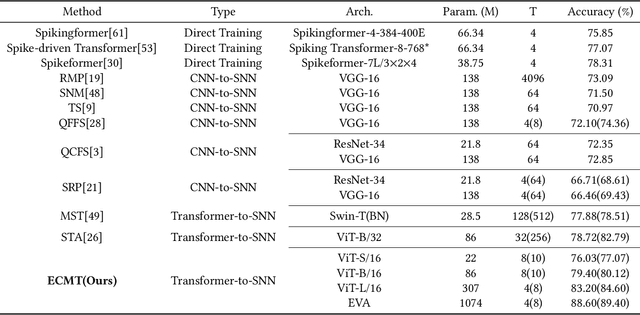
Spiking neural networks (SNNs) show great potential due to their energy efficiency, fast processing capabilities, and robustness. There are two main approaches to constructing SNNs. Direct training methods require much memory, while conversion methods offer a simpler and more efficient option. However, current conversion methods mainly focus on converting convolutional neural networks (CNNs) to SNNs. Converting Transformers to SNN is challenging because of the presence of non-linear modules. In this paper, we propose an Expectation Compensation Module to preserve the accuracy of the conversion. The core idea is to use information from the previous T time-steps to calculate the expected output at time-step T. We also propose a Multi-Threshold Neuron and the corresponding Parallel Parameter normalization to address the challenge of large time steps needed for high accuracy, aiming to reduce network latency and power consumption. Our experimental results demonstrate that our approach achieves state-of-the-art performance. For example, we achieve a top-1 accuracy of 88.60\% with only a 1\% loss in accuracy using 4 time steps while consuming only 35\% of the original power of the Transformer. To our knowledge, this is the first successful Artificial Neural Network (ANN) to SNN conversion for Spiking Transformers that achieves high accuracy, low latency, and low power consumption on complex datasets. The source codes of the proposed method are available at https://github.com/h-z-h-cell/Transformer-to-SNN-ECMT.
Faster and Stronger: When ANN-SNN Conversion Meets Parallel Spiking Calculation
Dec 18, 2024



Spiking Neural Network (SNN), as a brain-inspired and energy-efficient network, is currently facing the pivotal challenge of exploring a suitable and efficient learning framework. The predominant training methodologies, namely Spatial-Temporal Back-propagation (STBP) and ANN-SNN Conversion, are encumbered by substantial training overhead or pronounced inference latency, which impedes the advancement of SNNs in scaling to larger networks and navigating intricate application domains. In this work, we propose a novel parallel conversion learning framework, which establishes a mathematical mapping relationship between each time-step of the parallel spiking neurons and the cumulative spike firing rate. We theoretically validate the lossless and sorting properties of the conversion process, as well as pointing out the optimal shifting distance for each step. Furthermore, by integrating the above framework with the distribution-aware error calibration technique, we can achieve efficient conversion towards more general activation functions or training-free circumstance. Extensive experiments have confirmed the significant performance advantages of our method for various conversion cases under ultra-low time latency. To our best knowledge, this is the first work which jointly utilizes parallel spiking calculation and ANN-SNN Conversion, providing a highly promising approach for SNN supervised training.
USP-Gaussian: Unifying Spike-based Image Reconstruction, Pose Correction and Gaussian Splatting
Nov 15, 2024



Spike cameras, as an innovative neuromorphic camera that captures scenes with the 0-1 bit stream at 40 kHz, are increasingly employed for the 3D reconstruction task via Neural Radiance Fields (NeRF) or 3D Gaussian Splatting (3DGS). Previous spike-based 3D reconstruction approaches often employ a casecased pipeline: starting with high-quality image reconstruction from spike streams based on established spike-to-image reconstruction algorithms, then progressing to camera pose estimation and 3D reconstruction. However, this cascaded approach suffers from substantial cumulative errors, where quality limitations of initial image reconstructions negatively impact pose estimation, ultimately degrading the fidelity of the 3D reconstruction. To address these issues, we propose a synergistic optimization framework, \textbf{USP-Gaussian}, that unifies spike-based image reconstruction, pose correction, and Gaussian splatting into an end-to-end framework. Leveraging the multi-view consistency afforded by 3DGS and the motion capture capability of the spike camera, our framework enables a joint iterative optimization that seamlessly integrates information between the spike-to-image network and 3DGS. Experiments on synthetic datasets with accurate poses demonstrate that our method surpasses previous approaches by effectively eliminating cascading errors. Moreover, we integrate pose optimization to achieve robust 3D reconstruction in real-world scenarios with inaccurate initial poses, outperforming alternative methods by effectively reducing noise and preserving fine texture details. Our code, data and trained models will be available at \url{https://github.com/chenkang455/USP-Gaussian}.
Comprehensive Online Training and Deployment for Spiking Neural Networks
Oct 10, 2024Spiking Neural Networks (SNNs) are considered to have enormous potential in the future development of Artificial Intelligence (AI) due to their brain-inspired and energy-efficient properties. In the current supervised learning domain of SNNs, compared to vanilla Spatial-Temporal Back-propagation (STBP) training, online training can effectively overcome the risk of GPU memory explosion and has received widespread academic attention. However, the current proposed online training methods cannot tackle the inseparability problem of temporal dependent gradients and merely aim to optimize the training memory, resulting in no performance advantages compared to the STBP training models in the inference phase. To address the aforementioned challenges, we propose Efficient Multi-Precision Firing (EM-PF) model, which is a family of advanced spiking models based on floating-point spikes and binary synaptic weights. We point out that EM-PF model can effectively separate temporal gradients and achieve full-stage optimization towards computation speed and memory footprint. Experimental results have demonstrated that EM-PF model can be flexibly combined with various techniques including random back-propagation, parallel computation and channel attention mechanism, to achieve state-of-the-art performance with extremely low computational overhead in the field of online learning.
UP-Diff: Latent Diffusion Model for Remote Sensing Urban Prediction
Jul 16, 2024This study introduces a novel Remote Sensing (RS) Urban Prediction (UP) task focused on future urban planning, which aims to forecast urban layouts by utilizing information from existing urban layouts and planned change maps. To address the proposed RS UP task, we propose UP-Diff, which leverages a Latent Diffusion Model (LDM) to capture positionaware embeddings of pre-change urban layouts and planned change maps. In specific, the trainable cross-attention layers within UP-Diff's iterative diffusion modules enable the model to dynamically highlight crucial regions for targeted modifications. By utilizing our UP-Diff, designers can effectively refine and adjust future urban city plans by making modifications to the change maps in a dynamic and adaptive manner. Compared with conventional RS Change Detection (CD) methods, the proposed UP-Diff for the RS UP task avoids the requirement of paired prechange and post-change images, which enhances the practical usage in city development. Experimental results on LEVIRCD and SYSU-CD datasets show UP-Diff's ability to accurately predict future urban layouts with high fidelity, demonstrating its potential for urban planning. Code and model weights will be available upon the acceptance of the work.
Enhancing Adversarial Robustness in SNNs with Sparse Gradients
May 30, 2024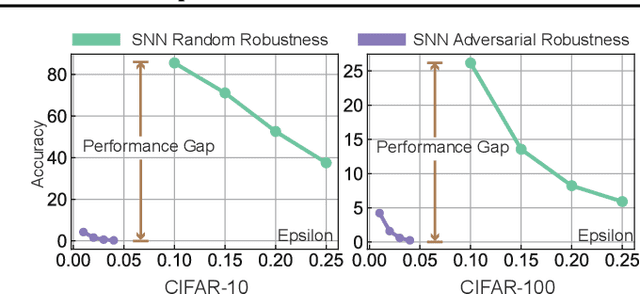
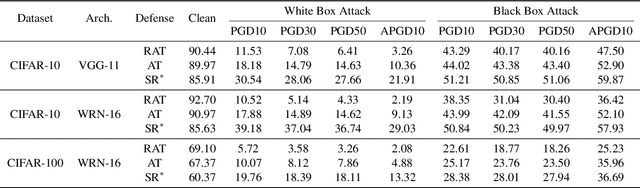
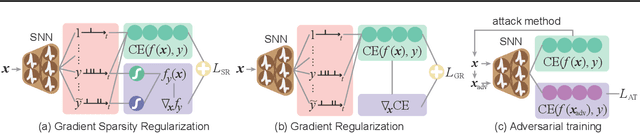
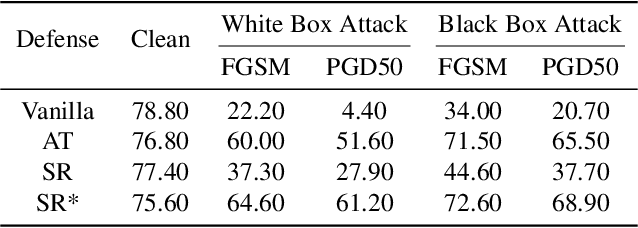
Spiking Neural Networks (SNNs) have attracted great attention for their energy-efficient operations and biologically inspired structures, offering potential advantages over Artificial Neural Networks (ANNs) in terms of energy efficiency and interpretability. Nonetheless, similar to ANNs, the robustness of SNNs remains a challenge, especially when facing adversarial attacks. Existing techniques, whether adapted from ANNs or specifically designed for SNNs, exhibit limitations in training SNNs or defending against strong attacks. In this paper, we propose a novel approach to enhance the robustness of SNNs through gradient sparsity regularization. We observe that SNNs exhibit greater resilience to random perturbations compared to adversarial perturbations, even at larger scales. Motivated by this, we aim to narrow the gap between SNNs under adversarial and random perturbations, thereby improving their overall robustness. To achieve this, we theoretically prove that this performance gap is upper bounded by the gradient sparsity of the probability associated with the true label concerning the input image, laying the groundwork for a practical strategy to train robust SNNs by regularizing the gradient sparsity. We validate the effectiveness of our approach through extensive experiments on both image-based and event-based datasets. The results demonstrate notable improvements in the robustness of SNNs. Our work highlights the importance of gradient sparsity in SNNs and its role in enhancing robustness.
SpikingResformer: Bridging ResNet and Vision Transformer in Spiking Neural Networks
Mar 28, 2024The remarkable success of Vision Transformers in Artificial Neural Networks (ANNs) has led to a growing interest in incorporating the self-attention mechanism and transformer-based architecture into Spiking Neural Networks (SNNs). While existing methods propose spiking self-attention mechanisms that are compatible with SNNs, they lack reasonable scaling methods, and the overall architectures proposed by these methods suffer from a bottleneck in effectively extracting local features. To address these challenges, we propose a novel spiking self-attention mechanism named Dual Spike Self-Attention (DSSA) with a reasonable scaling method. Based on DSSA, we propose a novel spiking Vision Transformer architecture called SpikingResformer, which combines the ResNet-based multi-stage architecture with our proposed DSSA to improve both performance and energy efficiency while reducing parameters. Experimental results show that SpikingResformer achieves higher accuracy with fewer parameters and lower energy consumption than other spiking Vision Transformer counterparts. Notably, our SpikingResformer-L achieves 79.40% top-1 accuracy on ImageNet with 4 time-steps, which is the state-of-the-art result in the SNN field.