 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneral Self-Prediction Enhancement for Spiking Neurons
Jan 29, 2026Spiking Neural Networks (SNNs) are highly energy-efficient due to event-driven, sparse computation, but their training is challenged by spike non-differentiability and trade-offs among performance, efficiency, and biological plausibility. Crucially, mainstream SNNs ignore predictive coding, a core cortical mechanism where the brain predicts inputs and encodes errors for efficient perception. Inspired by this, we propose a self-prediction enhanced spiking neuron method that generates an internal prediction current from its input-output history to modulate membrane potential. This design offers dual advantages, it creates a continuous gradient path that alleviates vanishing gradients and boosts training stability and accuracy, while also aligning with biological principles, which resembles distal dendritic modulation and error-driven synaptic plasticity. Experiments show consistent performance gains across diverse architectures, neuron types, time steps, and tasks demonstrating broad applicability for enhancing SNNs.
Proxy Target: Bridging the Gap Between Discrete Spiking Neural Networks and Continuous Control
May 30, 2025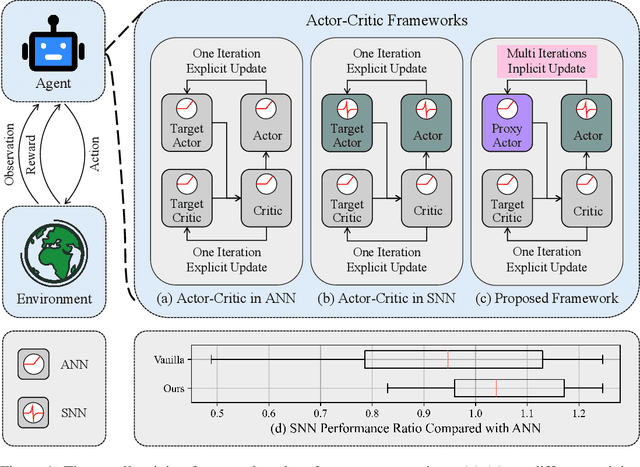
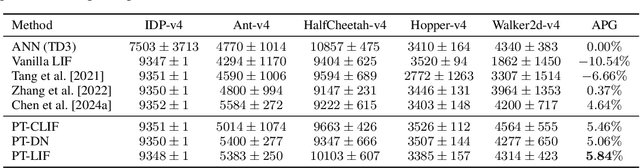
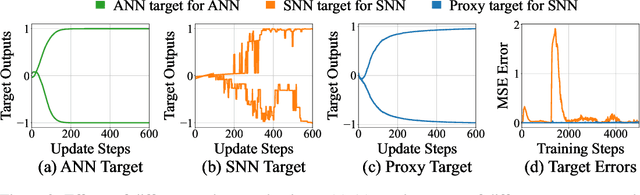

Spiking Neural Networks (SNNs) offer low-latency and energy-efficient decision making through neuromorphic hardware, making them compelling for Reinforcement Learning (RL) in resource-constrained edge devices. Recent studies in this field directly replace Artificial Neural Networks (ANNs) by SNNs in existing RL frameworks, overlooking whether the RL algorithm is suitable for SNNs. However, most RL algorithms in continuous control are designed tailored to ANNs, including the target network soft updates mechanism, which conflict with the discrete, non-differentiable dynamics of SNN spikes. We identify that this mismatch destabilizes SNN training in continuous control tasks. To bridge this gap between discrete SNN and continuous control, we propose a novel proxy target framework. The continuous and differentiable dynamics of the proxy target enable smooth updates, bypassing the incompatibility of SNN spikes, stabilizing the RL algorithms. Since the proxy network operates only during training, the SNN retains its energy efficiency during deployment without inference overhead. Extensive experiments on continuous control benchmarks demonstrate that compared to vanilla SNNs, the proxy target framework enables SNNs to achieve up to 32% higher performance across different spiking neurons. Notably, we are the first to surpass ANN performance in continuous control with simple Leaky-Integrate-and-Fire (LIF) neurons. This work motivates a new class of SNN-friendly RL algorithms tailored to SNN's characteristics, paving the way for neuromorphic agents that combine high performance with low power consumption.
Towards High-performance Spiking Transformers from ANN to SNN Conversion
Feb 28, 2025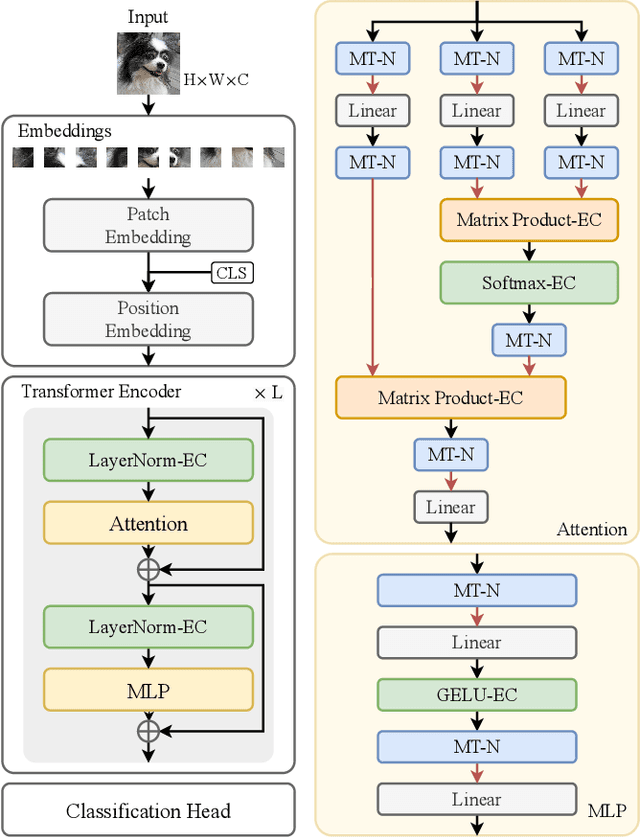
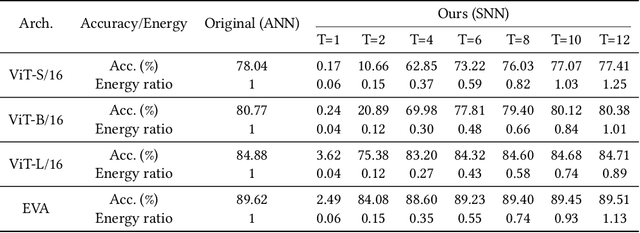
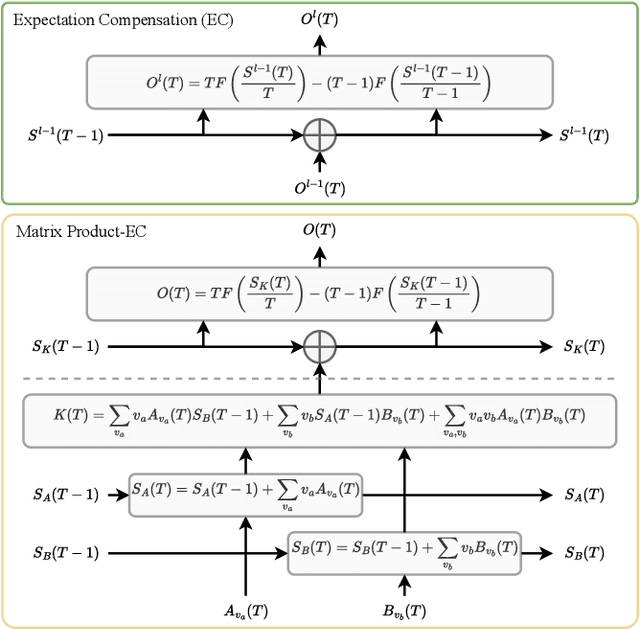
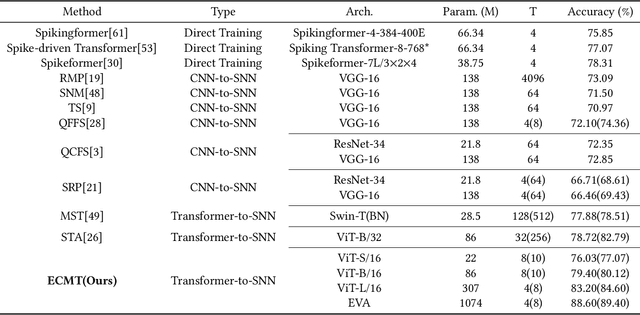
Spiking neural networks (SNNs) show great potential due to their energy efficiency, fast processing capabilities, and robustness. There are two main approaches to constructing SNNs. Direct training methods require much memory, while conversion methods offer a simpler and more efficient option. However, current conversion methods mainly focus on converting convolutional neural networks (CNNs) to SNNs. Converting Transformers to SNN is challenging because of the presence of non-linear modules. In this paper, we propose an Expectation Compensation Module to preserve the accuracy of the conversion. The core idea is to use information from the previous T time-steps to calculate the expected output at time-step T. We also propose a Multi-Threshold Neuron and the corresponding Parallel Parameter normalization to address the challenge of large time steps needed for high accuracy, aiming to reduce network latency and power consumption. Our experimental results demonstrate that our approach achieves state-of-the-art performance. For example, we achieve a top-1 accuracy of 88.60\% with only a 1\% loss in accuracy using 4 time steps while consuming only 35\% of the original power of the Transformer. To our knowledge, this is the first successful Artificial Neural Network (ANN) to SNN conversion for Spiking Transformers that achieves high accuracy, low latency, and low power consumption on complex datasets. The source codes of the proposed method are available at https://github.com/h-z-h-cell/Transformer-to-SNN-ECMT.
Training-free Conversion of Pretrained ANNs to SNNs for Low-Power and High-Performance Applications
Sep 05, 2024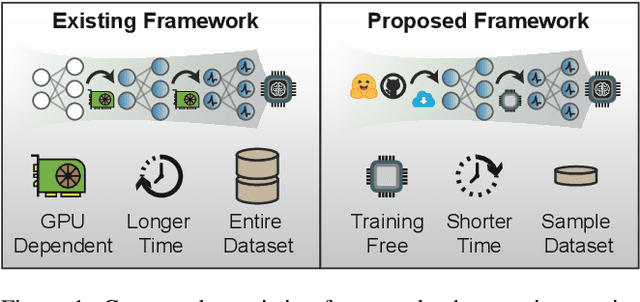
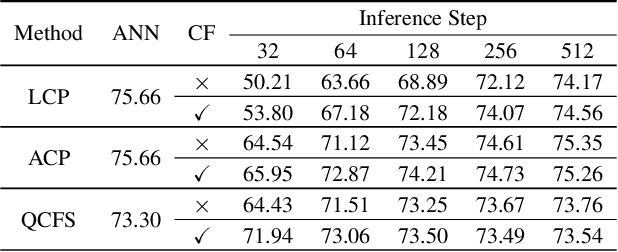
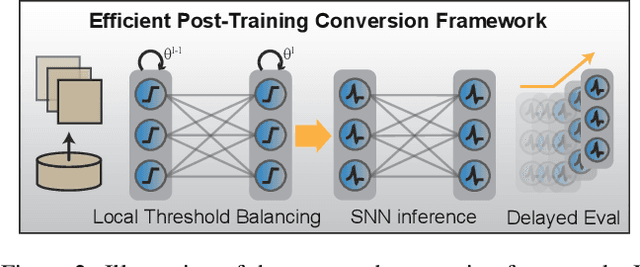
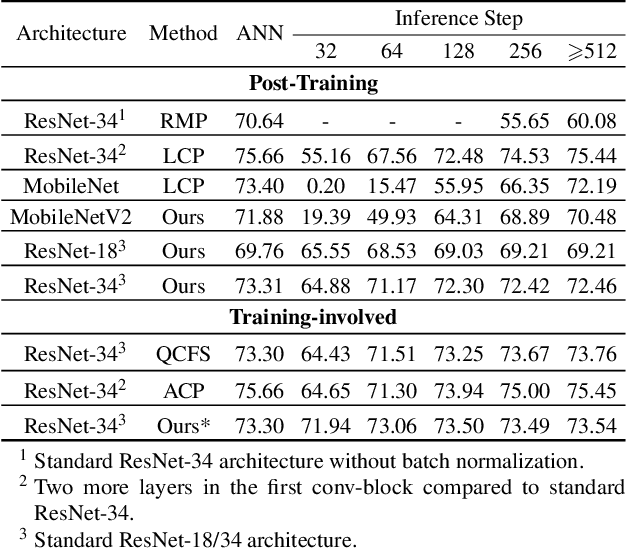
Spiking Neural Networks (SNNs) have emerged as a promising substitute for Artificial Neural Networks (ANNs) due to their advantages of fast inference and low power consumption. However, the lack of efficient training algorithms has hindered their widespread adoption. Existing supervised learning algorithms for SNNs require significantly more memory and time than their ANN counterparts. Even commonly used ANN-SNN conversion methods necessitate re-training of ANNs to enhance conversion efficiency, incurring additional computational costs. To address these challenges, we propose a novel training-free ANN-SNN conversion pipeline. Our approach directly converts pre-trained ANN models into high-performance SNNs without additional training. The conversion pipeline includes a local-learning-based threshold balancing algorithm, which enables efficient calculation of the optimal thresholds and fine-grained adjustment of threshold value by channel-wise scaling. We demonstrate the scalability of our framework across three typical computer vision tasks: image classification, semantic segmentation, and object detection. This showcases its applicability to both classification and regression tasks. Moreover, we have evaluated the energy consumption of the converted SNNs, demonstrating their superior low-power advantage compared to conventional ANNs. Our training-free algorithm outperforms existing methods, highlighting its practical applicability and efficiency. This approach simplifies the deployment of SNNs by leveraging open-source pre-trained ANN models and neuromorphic hardware, enabling fast, low-power inference with negligible performance reduction.
Enhancing Adversarial Robustness in SNNs with Sparse Gradients
May 30, 2024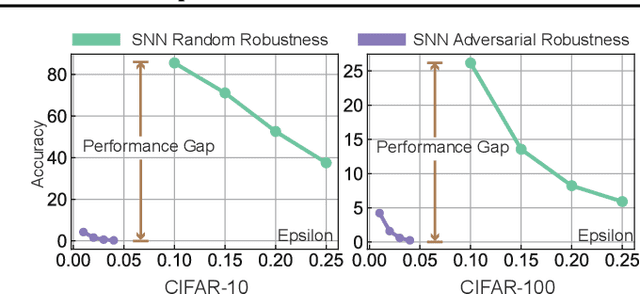
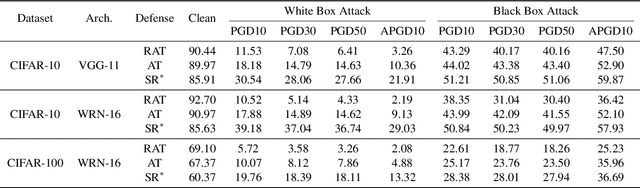
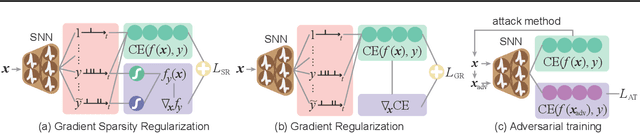
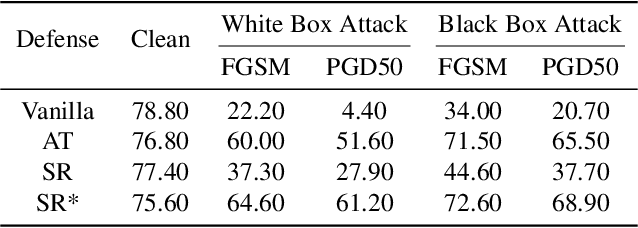
Spiking Neural Networks (SNNs) have attracted great attention for their energy-efficient operations and biologically inspired structures, offering potential advantages over Artificial Neural Networks (ANNs) in terms of energy efficiency and interpretability. Nonetheless, similar to ANNs, the robustness of SNNs remains a challenge, especially when facing adversarial attacks. Existing techniques, whether adapted from ANNs or specifically designed for SNNs, exhibit limitations in training SNNs or defending against strong attacks. In this paper, we propose a novel approach to enhance the robustness of SNNs through gradient sparsity regularization. We observe that SNNs exhibit greater resilience to random perturbations compared to adversarial perturbations, even at larger scales. Motivated by this, we aim to narrow the gap between SNNs under adversarial and random perturbations, thereby improving their overall robustness. To achieve this, we theoretically prove that this performance gap is upper bounded by the gradient sparsity of the probability associated with the true label concerning the input image, laying the groundwork for a practical strategy to train robust SNNs by regularizing the gradient sparsity. We validate the effectiveness of our approach through extensive experiments on both image-based and event-based datasets. The results demonstrate notable improvements in the robustness of SNNs. Our work highlights the importance of gradient sparsity in SNNs and its role in enhancing robustness.
Optimal ANN-SNN Conversion for High-accuracy and Ultra-low-latency Spiking Neural Networks
Mar 08, 2023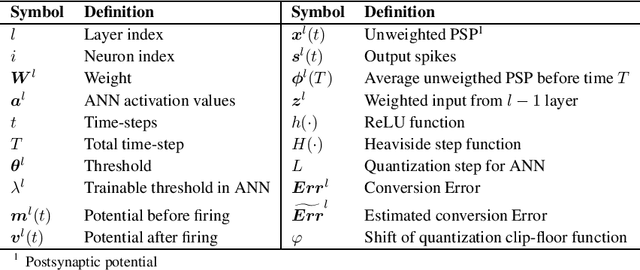
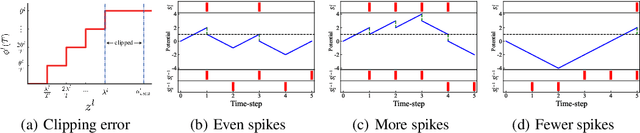
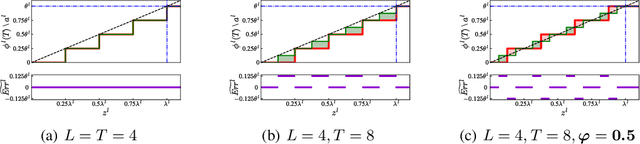
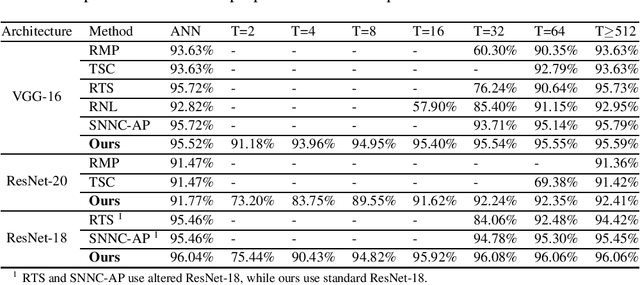
Spiking Neural Networks (SNNs) have gained great attraction due to their distinctive properties of low power consumption and fast inference on neuromorphic hardware. As the most effective method to get deep SNNs, ANN-SNN conversion has achieved comparable performance as ANNs on large-scale datasets. Despite this, it requires long time-steps to match the firing rates of SNNs to the activation of ANNs. As a result, the converted SNN suffers severe performance degradation problems with short time-steps, which hamper the practical application of SNNs. In this paper, we theoretically analyze ANN-SNN conversion error and derive the estimated activation function of SNNs. Then we propose the quantization clip-floor-shift activation function to replace the ReLU activation function in source ANNs, which can better approximate the activation function of SNNs. We prove that the expected conversion error between SNNs and ANNs is zero, enabling us to achieve high-accuracy and ultra-low-latency SNNs. We evaluate our method on CIFAR-10/100 and ImageNet datasets, and show that it outperforms the state-of-the-art ANN-SNN and directly trained SNNs in both accuracy and time-steps. To the best of our knowledge, this is the first time to explore high-performance ANN-SNN conversion with ultra-low latency (4 time-steps). Code is available at https://github.com/putshua/SNN\_conversion\_QCFS
Bridging the Gap between ANNs and SNNs by Calibrating Offset Spikes
Feb 21, 2023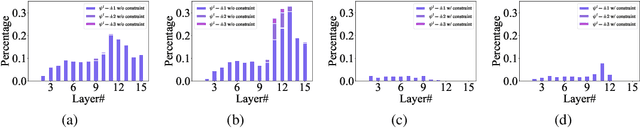
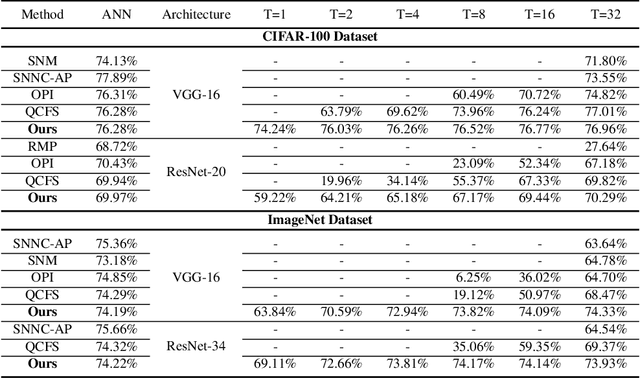

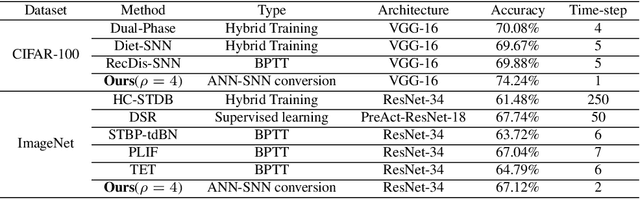
Spiking Neural Networks (SNNs) have attracted great attention due to their distinctive characteristics of low power consumption and temporal information processing. ANN-SNN conversion, as the most commonly used training method for applying SNNs, can ensure that converted SNNs achieve comparable performance to ANNs on large-scale datasets. However, the performance degrades severely under low quantities of time-steps, which hampers the practical applications of SNNs to neuromorphic chips. In this paper, instead of evaluating different conversion errors and then eliminating these errors, we define an offset spike to measure the degree of deviation between actual and desired SNN firing rates. We perform a detailed analysis of offset spike and note that the firing of one additional (or one less) spike is the main cause of conversion errors. Based on this, we propose an optimization strategy based on shifting the initial membrane potential and we theoretically prove the corresponding optimal shifting distance for calibrating the spike. In addition, we also note that our method has a unique iterative property that enables further reduction of conversion errors. The experimental results show that our proposed method achieves state-of-the-art performance on CIFAR-10, CIFAR-100, and ImageNet datasets. For example, we reach a top-1 accuracy of 67.12% on ImageNet when using 6 time-steps. To the best of our knowledge, this is the first time an ANN-SNN conversion has been shown to simultaneously achieve high accuracy and ultralow latency on complex datasets. Code is available at https://github.com/hzc1208/ANN2SNN_COS.
Benchmarking Interpretability Tools for Deep Neural Networks
Feb 08, 2023Interpreting deep neural networks is the topic of much current research in AI. However, few interpretability techniques have shown to be competitive tools in practical applications. Inspired by how benchmarks tend to guide progress in AI, we make three contributions. First, we propose trojan rediscovery as a benchmarking task to evaluate how useful interpretability tools are for generating engineering-relevant insights. Second, we design two such approaches for benchmarking: one for feature attribution methods and one for feature synthesis methods. Third, we apply our benchmarks to evaluate 16 feature attribution/saliency methods and 9 feature synthesis methods. This approach finds large differences in the capabilities of these existing tools and shows significant room for improvement. Finally, we propose several directions for future work. Resources are available at https://github.com/thestephencasper/benchmarking_interpretability
Reducing ANN-SNN Conversion Error through Residual Membrane Potential
Feb 04, 2023Spiking Neural Networks (SNNs) have received extensive academic attention due to the unique properties of low power consumption and high-speed computing on neuromorphic chips. Among various training methods of SNNs, ANN-SNN conversion has shown the equivalent level of performance as ANNs on large-scale datasets. However, unevenness error, which refers to the deviation caused by different temporal sequences of spike arrival on activation layers, has not been effectively resolved and seriously suffers the performance of SNNs under the condition of short time-steps. In this paper, we make a detailed analysis of unevenness error and divide it into four categories. We point out that the case of the ANN output being zero while the SNN output being larger than zero accounts for the largest percentage. Based on this, we theoretically prove the sufficient and necessary conditions of this case and propose an optimization strategy based on residual membrane potential to reduce unevenness error. The experimental results show that the proposed method achieves state-of-the-art performance on CIFAR-10, CIFAR-100, and ImageNet datasets. For example, we reach top-1 accuracy of 64.32\% on ImageNet with 10-steps. To the best of our knowledge, this is the first time ANN-SNN conversion can simultaneously achieve high accuracy and ultra-low-latency on the complex dataset. Code is available at https://github.com/hzc1208/ANN2SNN\_SRP.
Optimized Potential Initialization for Low-latency Spiking Neural Networks
Feb 03, 2022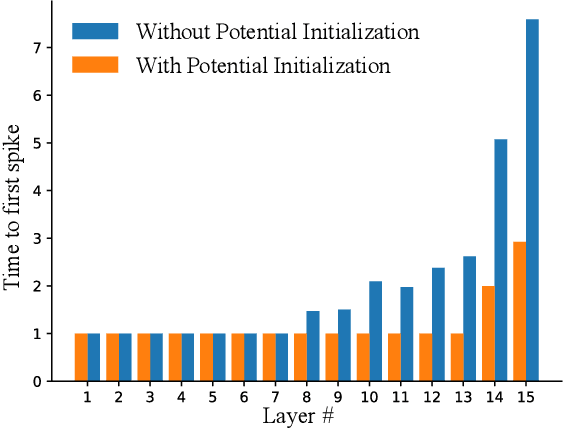
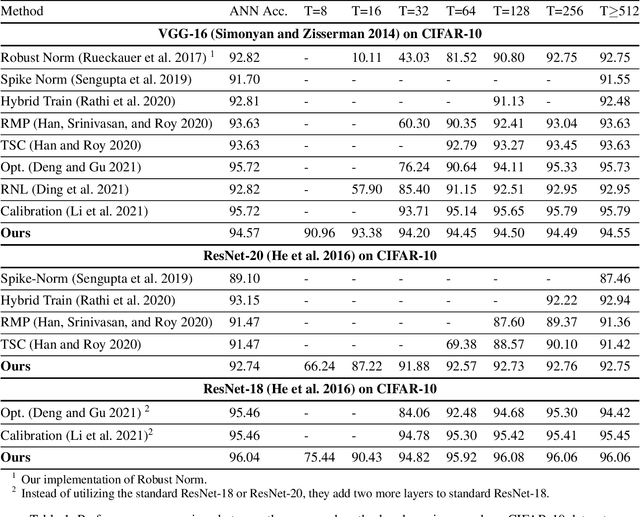
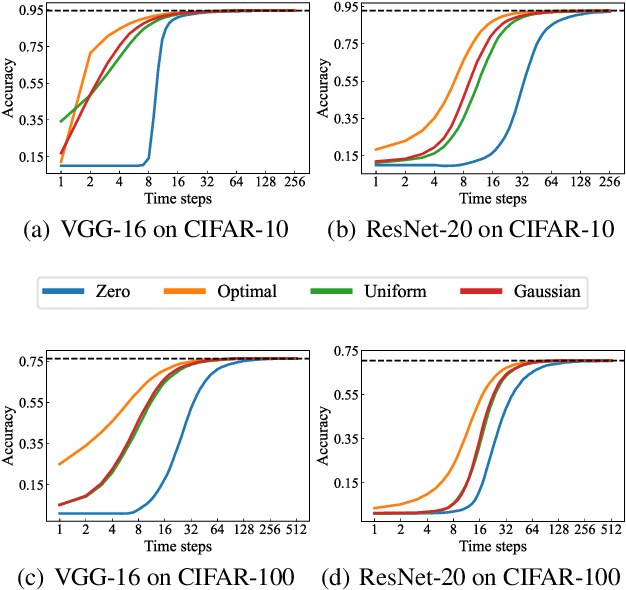
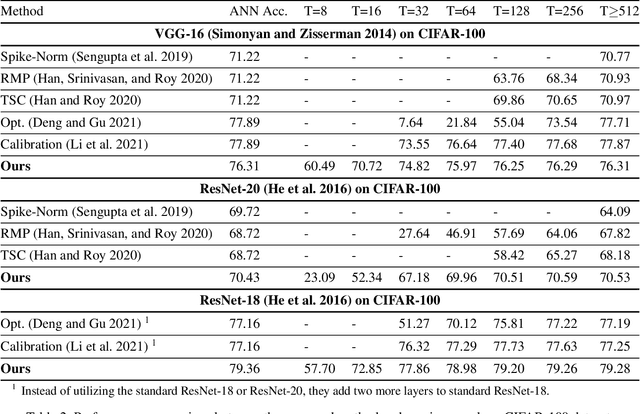
Spiking Neural Networks (SNNs) have been attached great importance due to the distinctive properties of low power consumption, biological plausibility, and adversarial robustness. The most effective way to train deep SNNs is through ANN-to-SNN conversion, which have yielded the best performance in deep network structure and large-scale datasets. However, there is a trade-off between accuracy and latency. In order to achieve high precision as original ANNs, a long simulation time is needed to match the firing rate of a spiking neuron with the activation value of an analog neuron, which impedes the practical application of SNN. In this paper, we aim to achieve high-performance converted SNNs with extremely low latency (fewer than 32 time-steps). We start by theoretically analyzing ANN-to-SNN conversion and show that scaling the thresholds does play a similar role as weight normalization. Instead of introducing constraints that facilitate ANN-to-SNN conversion at the cost of model capacity, we applied a more direct way by optimizing the initial membrane potential to reduce the conversion loss in each layer. Besides, we demonstrate that optimal initialization of membrane potentials can implement expected error-free ANN-to-SNN conversion. We evaluate our algorithm on the CIFAR-10, CIFAR-100 and ImageNet datasets and achieve state-of-the-art accuracy, using fewer time-steps. For example, we reach top-1 accuracy of 93.38\% on CIFAR-10 with 16 time-steps. Moreover, our method can be applied to other ANN-SNN conversion methodologies and remarkably promote performance when the time-steps is small.