 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Transformer-based Decoder for Varshamov-Tenengolts Codes
Feb 28, 2025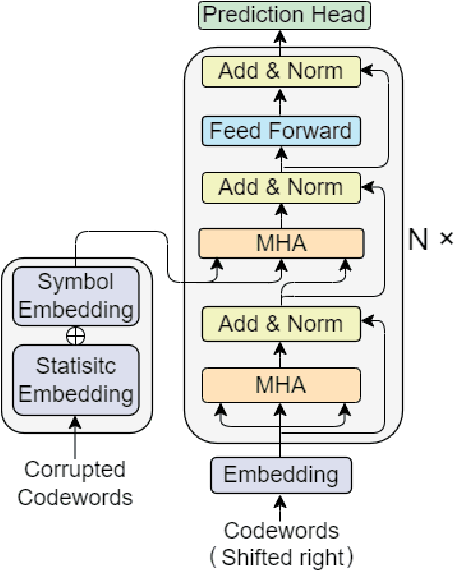
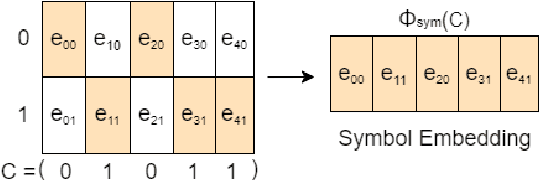
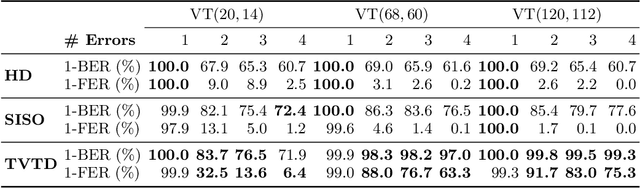

In recent years, the rise of DNA data storage technology has brought significant attention to the challenge of correcting insertion, deletion, and substitution (IDS) errors. Among various coding methods for IDS correction, Varshamov-Tenengolts (VT) codes, primarily designed for single-error correction, have emerged as a central research focus. While existing decoding methods achieve high accuracy in correcting a single error, they often fail to correct multiple IDS errors. In this work, we observe that VT codes retain some capability for addressing multiple errors by introducing a transformer-based VT decoder (TVTD) along with symbol- and statistic-based codeword embedding. Experimental results demonstrate that the proposed TVTD achieves perfect correction of a single error. Furthermore, when decoding multiple errors across various codeword lengths, the bit error rate and frame error rate are significantly improved compared to existing hard decision and soft-in soft-out algorithms. Additionally, through model architecture optimization, the proposed method reduces time consumption by an order of magnitude compared to other soft decoders.
A Unified Framework for Generative Data Augmentation: A Comprehensive Survey
Sep 30, 2023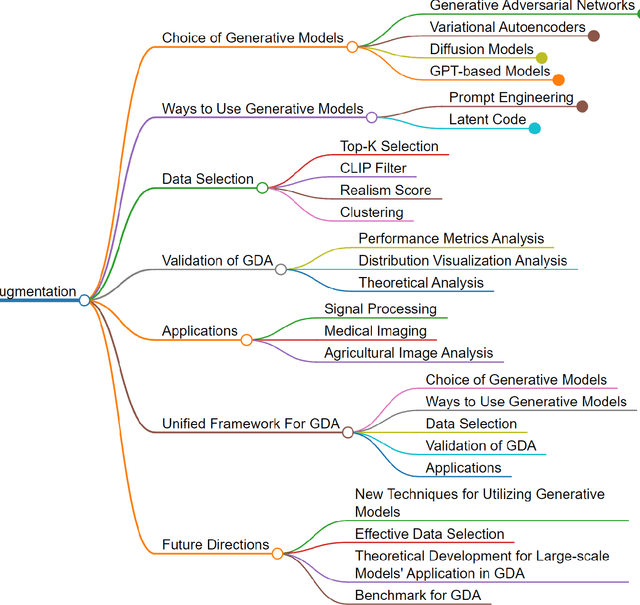

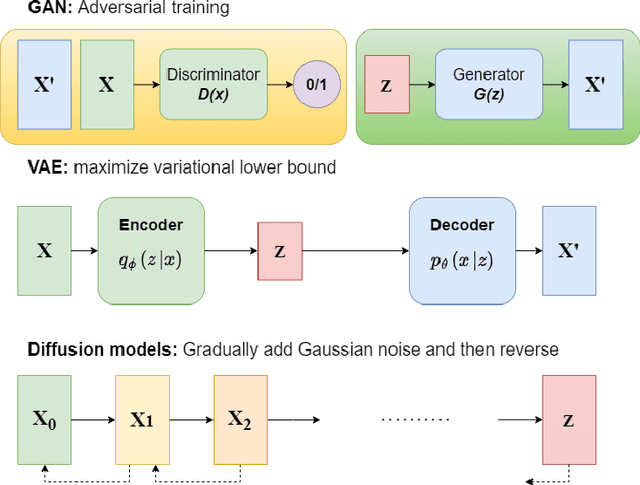
Generative data augmentation (GDA) has emerged as a promising technique to alleviate data scarcity in machine learning applications. This thesis presents a comprehensive survey and unified framework of the GDA landscape. We first provide an overview of GDA, discussing its motivation, taxonomy, and key distinctions from synthetic data generation. We then systematically analyze the critical aspects of GDA - selection of generative models, techniques to utilize them, data selection methodologies, validation approaches, and diverse applications. Our proposed unified framework categorizes the extensive GDA literature, revealing gaps such as the lack of universal benchmarks. The thesis summarises promising research directions, including , effective data selection, theoretical development for large-scale models' application in GDA and establishing a benchmark for GDA. By laying a structured foundation, this thesis aims to nurture more cohesive development and accelerate progress in the vital arena of generative data augmentation.
Data Augmentation for Environmental Sound Classification Using Diffusion Probabilistic Model with Top-k Selection Discriminator
Apr 04, 2023


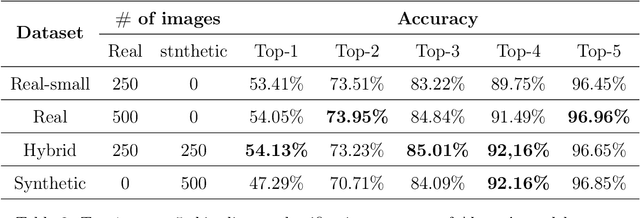
Despite consistent advancement in powerful deep learning techniques in recent years, large amounts of training data are still necessary for the models to avoid overfitting. Synthetic datasets using generative adversarial networks (GAN) have recently been generated to overcome this problem. Nevertheless, despite advancements, GAN-based methods are usually hard to train or fail to generate high-quality data samples. In this paper, we propose an environmental sound classification augmentation technique based on the diffusion probabilistic model with DPM-Solver$++$ for fast sampling. In addition, to ensure the quality of the generated spectrograms, we train a top-k selection discriminator on the dataset. According to the experiment results, the synthesized spectrograms have similar features to the original dataset and can significantly increase the classification accuracy of different state-of-the-art models compared with traditional data augmentation techniques. The public code is available on https://github.com/JNAIC/DPMs-for-Audio-Data-Augmentation.
Effective Audio Classification Network Based on Paired Inverse Pyramid Structure and Dense MLP Block
Nov 05, 2022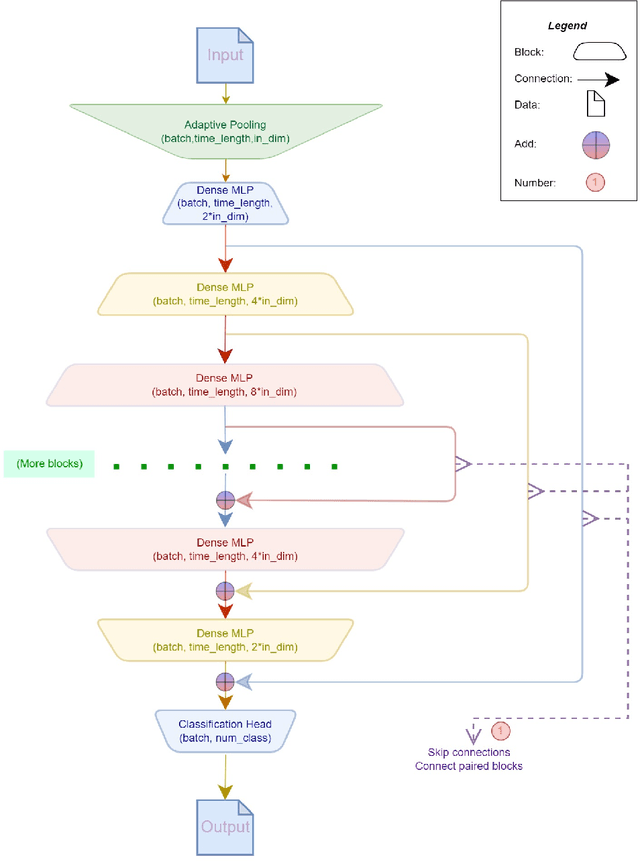
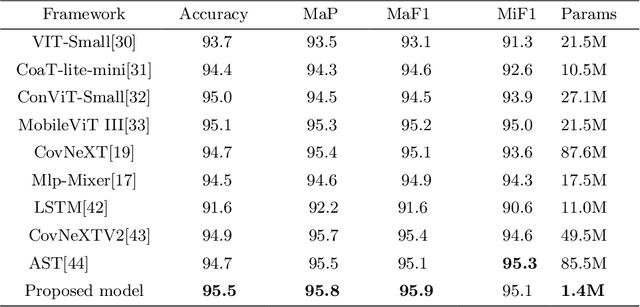
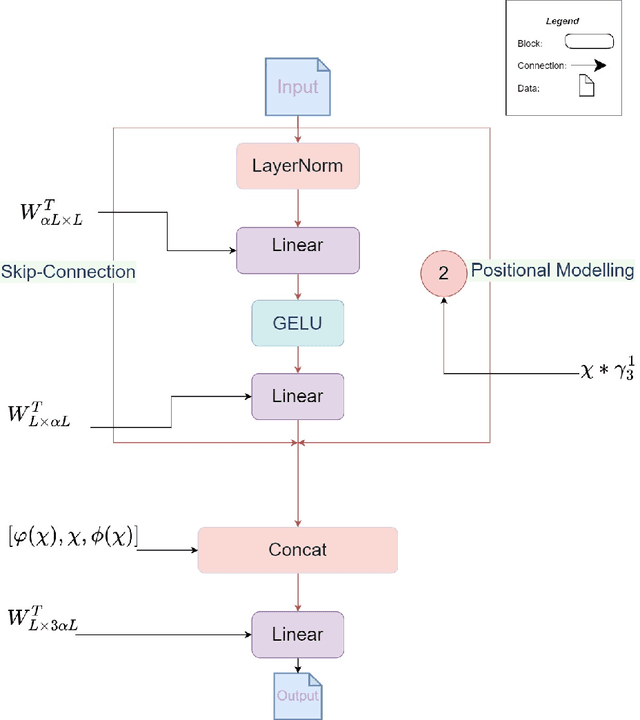
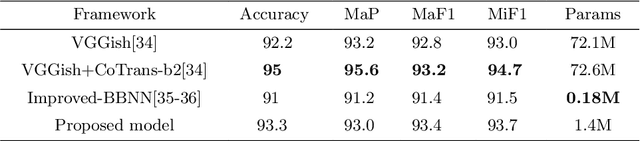
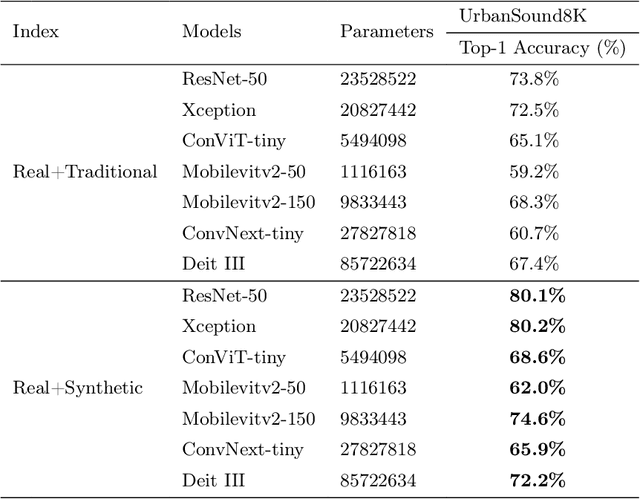
Recently, massive architectures based on Convolutional Neural Network (CNN) and self-attention mechanisms have become necessary for audio classification. While these techniques are state-of-the-art, these works' effectiveness can only be guaranteed with huge computational costs and parameters, large amounts of data augmentation, transfer from large datasets and some other tricks. By utilizing the lightweight nature of audio, we propose an efficient network structure called Paired Inverse Pyramid Structure (PIP) and a network called Paired Inverse Pyramid Structure MLP Network (PIPMN). The PIPMN reaches 96\% of Environmental Sound Classification (ESC) accuracy on the UrbanSound8K dataset and 93.2\% of Music Genre Classification (MGC) on the GTAZN dataset, with only 1 million parameters. Both of the results are achieved without data augmentation or model transfer. Public code is available at: https://github.com/JNAIC/PIPMN