 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Loosely Annotated Images with Imagined Annotations
Paper and Code
May 29, 2008
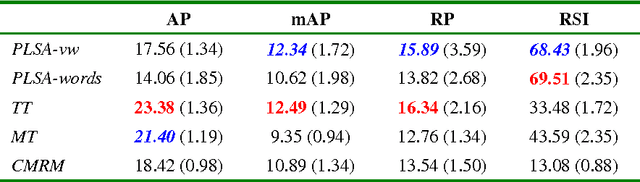
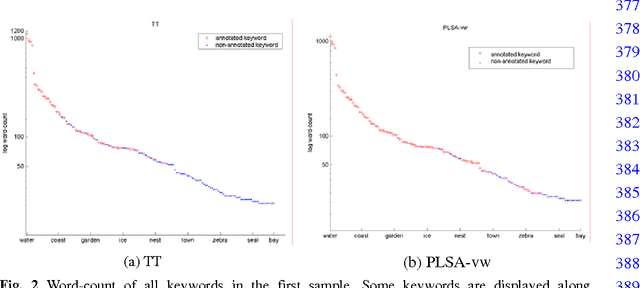
In this paper, we present an approach to learning latent semantic analysis models from loosely annotated images for automatic image annotation and indexing. The given annotation in training images is loose due to: (1) ambiguous correspondences between visual features and annotated keywords; (2) incomplete lists of annotated keywords. The second reason motivates us to enrich the incomplete annotation in a simple way before learning topic models. In particular, some imagined keywords are poured into the incomplete annotation through measuring similarity between keywords. Then, both given and imagined annotations are used to learning probabilistic topic models for automatically annotating new images. We conduct experiments on a typical Corel dataset of images and loose annotations, and compare the proposed method with state-of-the-art discrete annotation methods (using a set of discrete blobs to represent an image). The proposed method improves word-driven probability Latent Semantic Analysis (PLSA-words) up to a comparable performance with the best discrete annotation method, while a merit of PLSA-words is still kept, i.e., a wider semantic range.