 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Frequency Modulation for Controllable Text-driven Image Generation
Feb 11, 2026The success of text-guided diffusion models has established a new image generation paradigm driven by the iterative refinement of text prompts. However, modifying the original text prompt to achieve the expected semantic adjustments often results in unintended global structure changes that disrupt user intent. Existing methods rely on empirical feature map selection for intervention, whose performance heavily depends on appropriate selection, leading to suboptimal stability. This paper tries to solve the aforementioned problem from a frequency perspective and analyzes the impact of the frequency spectrum of noisy latent variables on the hierarchical emergence of the structure framework and fine-grained textures during the generation process. We find that lower-frequency components are primarily responsible for establishing the structure framework in the early generation stage. Their influence diminishes over time, giving way to higher-frequency components that synthesize fine-grained textures. In light of this, we propose a training-free frequency modulation method utilizing a frequency-dependent weighting function with dynamic decay. This method maintains the structure framework consistency while permitting targeted semantic modifications. By directly manipulating the noisy latent variable, the proposed method avoids the empirical selection of internal feature maps. Extensive experiments demonstrate that the proposed method significantly outperforms current state-of-the-art methods, achieving an effective balance between preserving structure and enabling semantic updates.
SeFi-CD: A Semantic First Change Detection Paradigm That Can Detect Any Change You Want
Jul 13, 2024



The existing change detection(CD) methods can be summarized as the visual-first change detection (ViFi-CD) paradigm, which first extracts change features from visual differences and then assigns them specific semantic information. However, CD is essentially dependent on change regions of interest (CRoIs), meaning that the CD results are directly determined by the semantics changes of interest, making its primary image factor semantic of interest rather than visual. The ViFi-CD paradigm can only assign specific semantics of interest to specific change features extracted from visual differences, leading to the inevitable omission of potential CRoIs and the inability to adapt to different CRoI CD tasks. In other words, changes in other CRoIs cannot be detected by the ViFi-CD method without retraining the model or significantly modifying the method. This paper introduces a new CD paradigm, the semantic-first CD (SeFi-CD) paradigm. The core idea of SeFi-CD is to first perceive the dynamic semantics of interest and then visually search for change features related to the semantics. Based on the SeFi-CD paradigm, we designed Anything You Want Change Detection (AUWCD). Experiments on public datasets demonstrate that the AUWCD outperforms the current state-of-the-art CD methods, achieving an average F1 score 5.01\% higher than that of these advanced supervised baselines on the SECOND dataset, with a maximum increase of 13.17\%. The proposed SeFi-CD offers a novel CD perspective and approach.
Homogeneous Tokenizer Matters: Homogeneous Visual Tokenizer for Remote Sensing Image Understanding
Mar 27, 2024



The tokenizer, as one of the fundamental components of large models, has long been overlooked or even misunderstood in visual tasks. One key factor of the great comprehension power of the large language model is that natural language tokenizers utilize meaningful words or subwords as the basic elements of language. In contrast, mainstream visual tokenizers, represented by patch-based methods such as Patch Embed, rely on meaningless rectangular patches as basic elements of vision, which cannot serve as effectively as words or subwords in language. Starting from the essence of the tokenizer, we defined semantically independent regions (SIRs) for vision. We designed a simple HOmogeneous visual tOKenizer: HOOK. HOOK mainly consists of two modules: the Object Perception Module (OPM) and the Object Vectorization Module (OVM). To achieve homogeneity, the OPM splits the image into 4*4 pixel seeds and then utilizes the attention mechanism to perceive SIRs. The OVM employs cross-attention to merge seeds within the same SIR. To achieve adaptability, the OVM defines a variable number of learnable vectors as cross-attention queries, allowing for the adjustment of token quantity. We conducted experiments on the NWPU-RESISC45, WHU-RS19 classification dataset, and GID5 segmentation dataset for sparse and dense tasks. The results demonstrate that the visual tokens obtained by HOOK correspond to individual objects, which demonstrates homogeneity. HOOK outperformed Patch Embed by 6\% and 10\% in the two tasks and achieved state-of-the-art performance compared to the baselines used for comparison. Compared to Patch Embed, which requires more than one hundred tokens for one image, HOOK requires only 6 and 8 tokens for sparse and dense tasks, respectively, resulting in efficiency improvements of 1.5 to 2.8 times. The code is available at https://github.com/GeoX-Lab/Hook.
HSONet:A Siamese foreground association-driven hard case sample optimization network for high-resolution remote sensing image change detection
Feb 26, 2024



In the later training stages, further improvement of the models ability to determine changes relies on how well the change detection (CD) model learns hard cases; however, there are two additional challenges to learning hard case samples: (1) change labels are limited and tend to pointer only to foreground targets, yet hard case samples are prevalent in the background, which leads to optimizing the loss function focusing on the foreground targets and ignoring the background hard cases, which we call imbalance. (2) Complex situations, such as light shadows, target occlusion, and seasonal changes, induce hard case samples, and in the absence of both supervisory and scene information, it is difficult for the model to learn hard case samples directly to accurately obtain the feature representations of the change information, which we call missingness. We propose a Siamese foreground association-driven hard case sample optimization network (HSONet). To deal with this imbalance, we propose an equilibrium optimization loss function to regulate the optimization focus of the foreground and background, determine the hard case samples through the distribution of the loss values, and introduce dynamic weights in the loss term to gradually shift the optimization focus of the loss from the foreground to the background hard cases as the training progresses. To address this missingness, we understand hard case samples with the help of the scene context, propose the scene-foreground association module, use potential remote sensing spatial scene information to model the association between the target of interest in the foreground and the related context to obtain scene embedding, and apply this information to the feature reinforcement of hard cases. Experiments on four public datasets show that HSONet outperforms current state-of-the-art CD methods, particularly in detecting hard case samples.
GraSS: Contrastive Learning with Gradient Guided Sampling Strategy for Remote Sensing Image Semantic Segmentation
Jul 03, 2023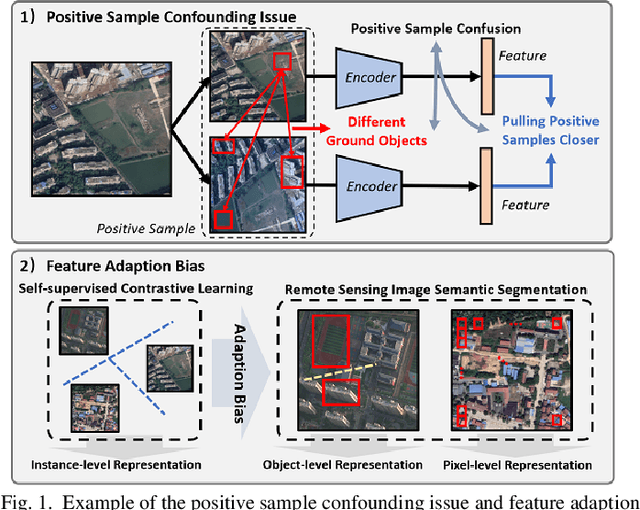

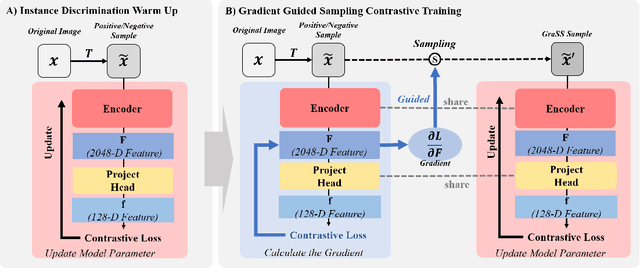
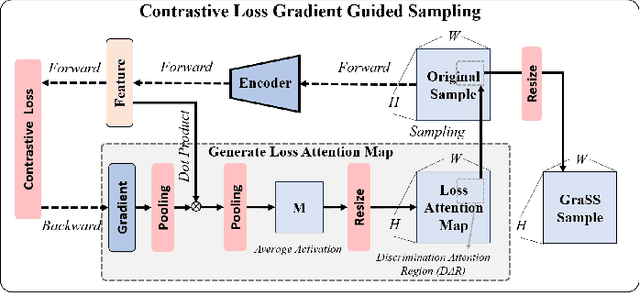
Self-supervised contrastive learning (SSCL) has achieved significant milestones in remote sensing image (RSI) understanding. Its essence lies in designing an unsupervised instance discrimination pretext task to extract image features from a large number of unlabeled images that are beneficial for downstream tasks. However, existing instance discrimination based SSCL suffer from two limitations when applied to the RSI semantic segmentation task: 1) Positive sample confounding issue; 2) Feature adaptation bias. It introduces a feature adaptation bias when applied to semantic segmentation tasks that require pixel-level or object-level features. In this study, We observed that the discrimination information can be mapped to specific regions in RSI through the gradient of unsupervised contrastive loss, these specific regions tend to contain singular ground objects. Based on this, we propose contrastive learning with Gradient guided Sampling Strategy (GraSS) for RSI semantic segmentation. GraSS consists of two stages: Instance Discrimination warm-up (ID warm-up) and Gradient guided Sampling contrastive training (GS training). The ID warm-up aims to provide initial discrimination information to the contrastive loss gradients. The GS training stage aims to utilize the discrimination information contained in the contrastive loss gradients and adaptively select regions in RSI patches that contain more singular ground objects, in order to construct new positive and negative samples. Experimental results on three open datasets demonstrate that GraSS effectively enhances the performance of SSCL in high-resolution RSI semantic segmentation. Compared to seven baseline methods from five different types of SSCL, GraSS achieves an average improvement of 1.57\% and a maximum improvement of 3.58\% in terms of mean intersection over the union. The source code is available at https://github.com/GeoX-Lab/GraSS