 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasonCD: A Multimodal Reasoning Large Model for Implicit Change-of-Interest Semantic Mining
Dec 22, 2025
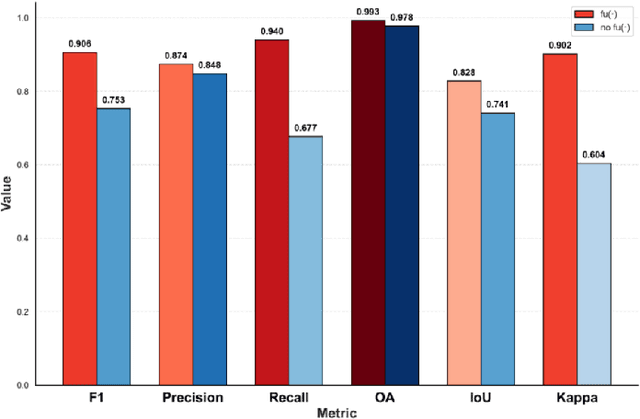
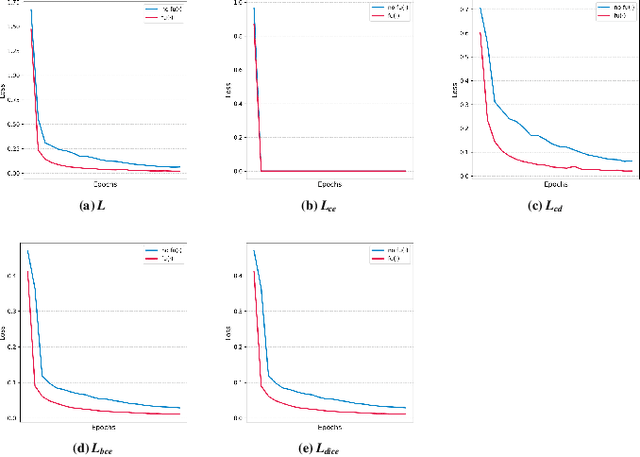
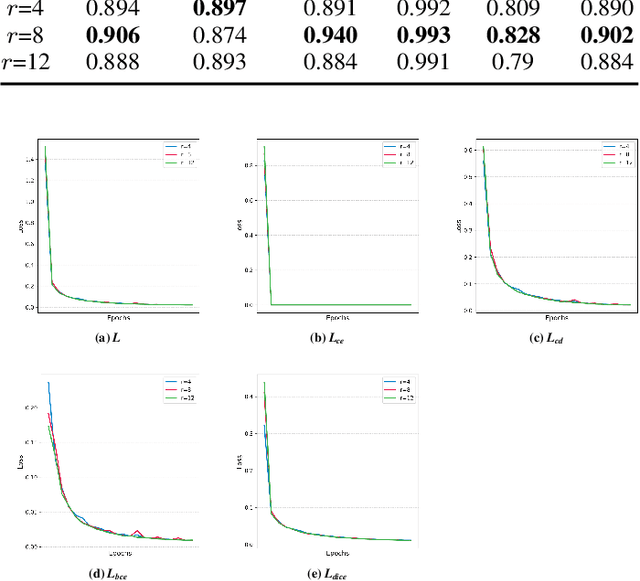
Remote sensing image change detection is one of the fundamental tasks in remote sensing intelligent interpretation. Its core objective is to identify changes within change regions of interest (CRoI). Current multimodal large models encode rich human semantic knowledge, which is utilized for guidance in tasks such as remote sensing change detection. However, existing methods that use semantic guidance for detecting users' CRoI overly rely on explicit textual descriptions of CRoI, leading to the problem of near-complete performance failure when presented with implicit CRoI textual descriptions. This paper proposes a multimodal reasoning change detection model named ReasonCD, capable of mining users' implicit task intent. The model leverages the powerful reasoning capabilities of pre-trained large language models to mine users' implicit task intents and subsequently obtains different change detection results based on these intents. Experiments on public datasets demonstrate that the model achieves excellent change detection performance, with an F1 score of 92.1\% on the BCDD dataset. Furthermore, to validate its superior reasoning functionality, this paper annotates a subset of reasoning data based on the SECOND dataset. Experimental results show that the model not only excels at basic reasoning-based change detection tasks but can also explain the reasoning process to aid human decision-making.
SeFi-CD: A Semantic First Change Detection Paradigm That Can Detect Any Change You Want
Jul 13, 2024



The existing change detection(CD) methods can be summarized as the visual-first change detection (ViFi-CD) paradigm, which first extracts change features from visual differences and then assigns them specific semantic information. However, CD is essentially dependent on change regions of interest (CRoIs), meaning that the CD results are directly determined by the semantics changes of interest, making its primary image factor semantic of interest rather than visual. The ViFi-CD paradigm can only assign specific semantics of interest to specific change features extracted from visual differences, leading to the inevitable omission of potential CRoIs and the inability to adapt to different CRoI CD tasks. In other words, changes in other CRoIs cannot be detected by the ViFi-CD method without retraining the model or significantly modifying the method. This paper introduces a new CD paradigm, the semantic-first CD (SeFi-CD) paradigm. The core idea of SeFi-CD is to first perceive the dynamic semantics of interest and then visually search for change features related to the semantics. Based on the SeFi-CD paradigm, we designed Anything You Want Change Detection (AUWCD). Experiments on public datasets demonstrate that the AUWCD outperforms the current state-of-the-art CD methods, achieving an average F1 score 5.01\% higher than that of these advanced supervised baselines on the SECOND dataset, with a maximum increase of 13.17\%. The proposed SeFi-CD offers a novel CD perspective and approach.
MFDS-Net: Multi-Scale Feature Depth-Supervised Network for Remote Sensing Change Detection with Global Semantic and Detail Information
May 02, 2024Change detection as an interdisciplinary discipline in the field of computer vision and remote sensing at present has been receiving extensive attention and research. Due to the rapid development of society, the geographic information captured by remote sensing satellites is changing faster and more complex, which undoubtedly poses a higher challenge and highlights the value of change detection tasks. We propose MFDS-Net: Multi-Scale Feature Depth-Supervised Network for Remote Sensing Change Detection with Global Semantic and Detail Information (MFDS-Net) with the aim of achieving a more refined description of changing buildings as well as geographic information, enhancing the localisation of changing targets and the acquisition of weak features. To achieve the research objectives, we use a modified ResNet_34 as backbone network to perform feature extraction and DO-Conv as an alternative to traditional convolution to better focus on the association between feature information and to obtain better training results. We propose the Global Semantic Enhancement Module (GSEM) to enhance the processing of high-level semantic information from a global perspective. The Differential Feature Integration Module (DFIM) is proposed to strengthen the fusion of different depth feature information, achieving learning and extraction of differential features. The entire network is trained and optimized using a deep supervision mechanism. The experimental outcomes of MFDS-Net surpass those of current mainstream change detection networks. On the LEVIR dataset, it achieved an F1 score of 91.589 and IoU of 84.483, on the WHU dataset, the scores were F1: 92.384 and IoU: 86.807, and on the GZ-CD dataset, the scores were F1: 86.377 and IoU: 76.021. The code is available at https://github.com/AOZAKIiii/MFDS-Net
HSONet:A Siamese foreground association-driven hard case sample optimization network for high-resolution remote sensing image change detection
Feb 26, 2024



In the later training stages, further improvement of the models ability to determine changes relies on how well the change detection (CD) model learns hard cases; however, there are two additional challenges to learning hard case samples: (1) change labels are limited and tend to pointer only to foreground targets, yet hard case samples are prevalent in the background, which leads to optimizing the loss function focusing on the foreground targets and ignoring the background hard cases, which we call imbalance. (2) Complex situations, such as light shadows, target occlusion, and seasonal changes, induce hard case samples, and in the absence of both supervisory and scene information, it is difficult for the model to learn hard case samples directly to accurately obtain the feature representations of the change information, which we call missingness. We propose a Siamese foreground association-driven hard case sample optimization network (HSONet). To deal with this imbalance, we propose an equilibrium optimization loss function to regulate the optimization focus of the foreground and background, determine the hard case samples through the distribution of the loss values, and introduce dynamic weights in the loss term to gradually shift the optimization focus of the loss from the foreground to the background hard cases as the training progresses. To address this missingness, we understand hard case samples with the help of the scene context, propose the scene-foreground association module, use potential remote sensing spatial scene information to model the association between the target of interest in the foreground and the related context to obtain scene embedding, and apply this information to the feature reinforcement of hard cases. Experiments on four public datasets show that HSONet outperforms current state-of-the-art CD methods, particularly in detecting hard case samples.