 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundation Reinforcement Learning: towards Embodied Generalist Agents with Foundation Prior Assistance
Oct 10, 2023



Recently, people have shown that large-scale pre-training from internet-scale data is the key to building generalist models, as witnessed in NLP. To build embodied generalist agents, we and many other researchers hypothesize that such foundation prior is also an indispensable component. However, it is unclear what is the proper concrete form to represent those embodied foundation priors and how they should be used in the downstream task. In this paper, we propose an intuitive and effective set of embodied priors that consist of foundation policy, value, and success reward. The proposed priors are based on the goal-conditioned MDP. To verify their effectiveness, we instantiate an actor-critic method assisted by the priors, called Foundation Actor-Critic (FAC). We name our framework as Foundation Reinforcement Learning (FRL), since it completely relies on embodied foundation priors to explore, learn and reinforce. The benefits of FRL are threefold. (1) Sample efficient. With foundation priors, FAC learns significantly faster than traditional RL. Our evaluation on the Meta-World has proved that FAC can achieve 100% success rates for 7/8 tasks under less than 200k frames, which outperforms the baseline method with careful manual-designed rewards under 1M frames. (2) Robust to noisy priors. Our method tolerates the unavoidable noise in embodied foundation models. We show that FAC works well even under heavy noise or quantization errors. (3) Minimal human intervention: FAC completely learns from the foundation priors, without the need of human-specified dense reward, or providing teleoperated demos. Thus, FAC can be easily scaled up. We believe our FRL framework could enable the future robot to autonomously explore and learn without human intervention in the physical world. In summary, our proposed FRL is a novel and powerful learning paradigm, towards achieving embodied generalist agents.
Seer: Language Instructed Video Prediction with Latent Diffusion Models
Apr 12, 2023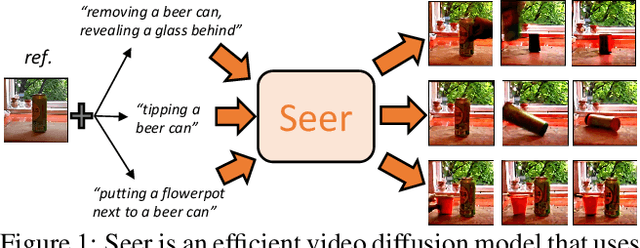
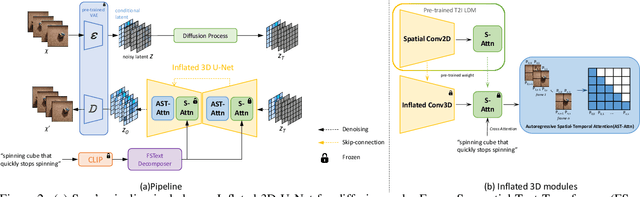

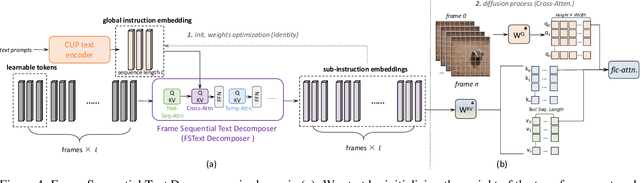
Imagining the future trajectory is the key for robots to make sound planning and successfully reach their goals. Therefore, text-conditioned video prediction (TVP) is an essential task to facilitate general robot policy learning, i.e., predicting future video frames with a given language instruction and reference frames. It is a highly challenging task to ground task-level goals specified by instructions and high-fidelity frames together, requiring large-scale data and computation. To tackle this task and empower robots with the ability to foresee the future, we propose a sample and computation-efficient model, named \textbf{Seer}, by inflating the pretrained text-to-image (T2I) stable diffusion models along the temporal axis. We inflate the denoising U-Net and language conditioning model with two novel techniques, Autoregressive Spatial-Temporal Attention and Frame Sequential Text Decomposer, to propagate the rich prior knowledge in the pretrained T2I models across the frames. With the well-designed architecture, Seer makes it possible to generate high-fidelity, coherent, and instruction-aligned video frames by fine-tuning a few layers on a small amount of data. The experimental results on Something Something V2 (SSv2) and Bridgedata datasets demonstrate our superior video prediction performance with around 210-hour training on 4 RTX 3090 GPUs: decreasing the FVD of the current SOTA model from 290 to 200 on SSv2 and achieving at least 70\% preference in the human evaluation.