 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAscendKernelGen: A Systematic Study of LLM-Based Kernel Generation for Neural Processing Units
Jan 12, 2026To meet the ever-increasing demand for computational efficiency, Neural Processing Units (NPUs) have become critical in modern AI infrastructure. However, unlocking their full potential requires developing high-performance compute kernels using vendor-specific Domain-Specific Languages (DSLs), a task that demands deep hardware expertise and is labor-intensive. While Large Language Models (LLMs) have shown promise in general code generation, they struggle with the strict constraints and scarcity of training data in the NPU domain. Our preliminary study reveals that state-of-the-art general-purpose LLMs fail to generate functional complex kernels for Ascend NPUs, yielding a near-zero success rate. To address these challenges, we propose AscendKernelGen, a generation-evaluation integrated framework for NPU kernel development. We introduce Ascend-CoT, a high-quality dataset incorporating chain-of-thought reasoning derived from real-world kernel implementations, and KernelGen-LM, a domain-adaptive model trained via supervised fine-tuning and reinforcement learning with execution feedback. Furthermore, we design NPUKernelBench, a comprehensive benchmark for assessing compilation, correctness, and performance across varying complexity levels. Experimental results demonstrate that our approach significantly bridges the gap between general LLMs and hardware-specific coding. Specifically, the compilation success rate on complex Level-2 kernels improves from 0% to 95.5% (Pass@10), while functional correctness achieves 64.3% compared to the baseline's complete failure. These results highlight the critical role of domain-specific reasoning and rigorous evaluation in automating accelerator-aware code generation.
Erase then Rectify: A Training-Free Parameter Editing Approach for Cost-Effective Graph Unlearning
Sep 25, 2024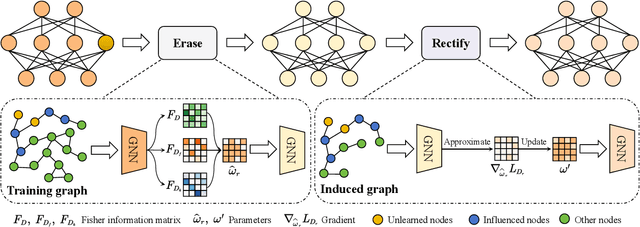
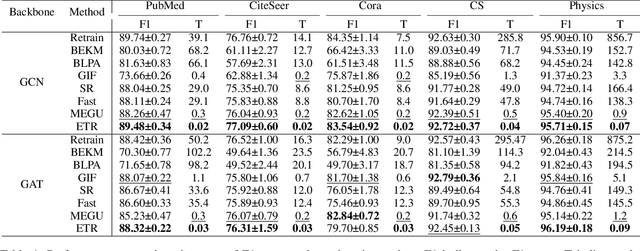
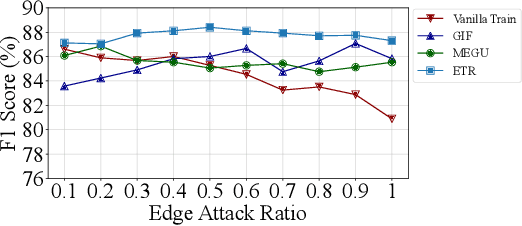
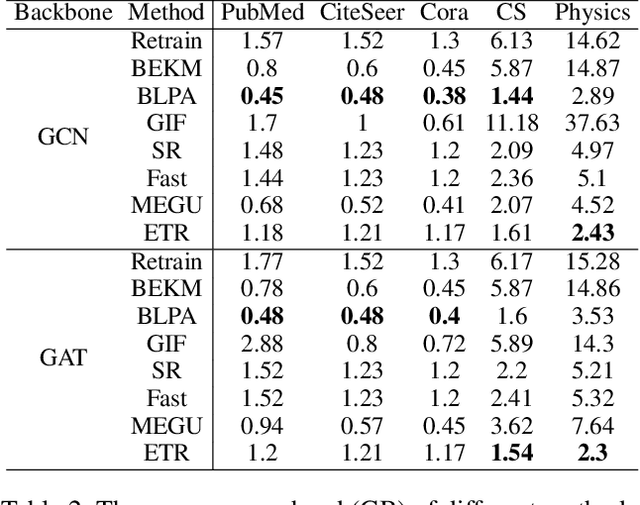
Graph unlearning, which aims to eliminate the influence of specific nodes, edges, or attributes from a trained Graph Neural Network (GNN), is essential in applications where privacy, bias, or data obsolescence is a concern. However, existing graph unlearning techniques often necessitate additional training on the remaining data, leading to significant computational costs, particularly with large-scale graphs. To address these challenges, we propose a two-stage training-free approach, Erase then Rectify (ETR), designed for efficient and scalable graph unlearning while preserving the model utility. Specifically, we first build a theoretical foundation showing that masking parameters critical for unlearned samples enables effective unlearning. Building on this insight, the Erase stage strategically edits model parameters to eliminate the impact of unlearned samples and their propagated influence on intercorrelated nodes. To further ensure the GNN's utility, the Rectify stage devises a gradient approximation method to estimate the model's gradient on the remaining dataset, which is then used to enhance model performance. Overall, ETR achieves graph unlearning without additional training or full training data access, significantly reducing computational overhead and preserving data privacy. Extensive experiments on seven public datasets demonstrate the consistent superiority of ETR in model utility, unlearning efficiency, and unlearning effectiveness, establishing it as a promising solution for real-world graph unlearning challenges.
GraphLoRA: Structure-Aware Contrastive Low-Rank Adaptation for Cross-Graph Transfer Learning
Sep 25, 2024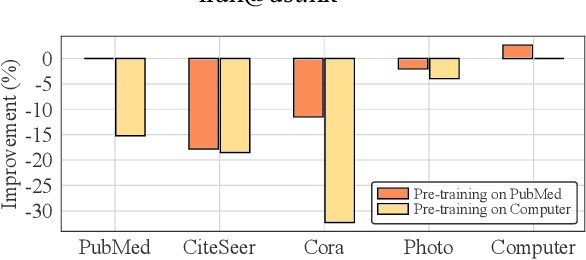
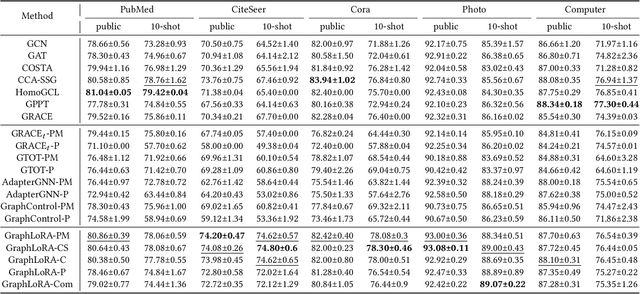
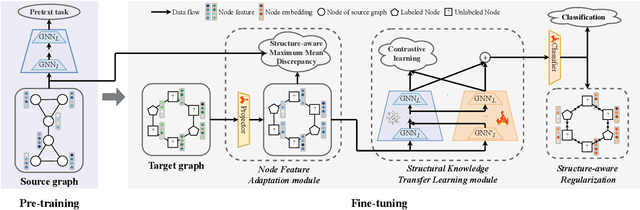
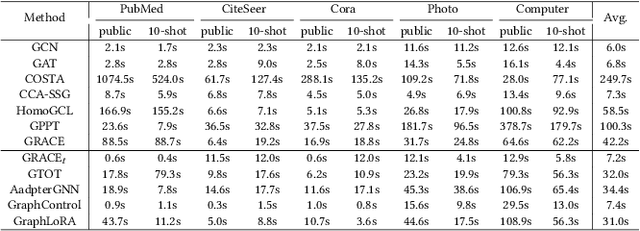
Graph Neural Networks (GNNs) have demonstrated remarkable proficiency in handling a range of graph analytical tasks across various domains, such as e-commerce and social networks. Despite their versatility, GNNs face significant challenges in transferability, limiting their utility in real-world applications. Existing research in GNN transfer learning overlooks discrepancies in distribution among various graph datasets, facing challenges when transferring across different distributions. How to effectively adopt a well-trained GNN to new graphs with varying feature and structural distributions remains an under-explored problem. Taking inspiration from the success of Low-Rank Adaptation (LoRA) in adapting large language models to various domains, we propose GraphLoRA, an effective and parameter-efficient method for transferring well-trained GNNs to diverse graph domains. Specifically, we first propose a Structure-aware Maximum Mean Discrepancy (SMMD) to align divergent node feature distributions across source and target graphs. Moreover, we introduce low-rank adaptation by injecting a small trainable GNN alongside the pre-trained one, effectively bridging structural distribution gaps while mitigating the catastrophic forgetting. Additionally, a structure-aware regularization objective is proposed to enhance the adaptability of the pre-trained GNN to target graph with scarce supervision labels. Extensive experiments on six real-world datasets demonstrate the effectiveness of GraphLoRA against eleven baselines by tuning only 20% of parameters, even across disparate graph domains. The code is available at https://anonymous.4open.science/r/GraphLoRA.
Hypergraph Enhanced Knowledge Tree Prompt Learning for Next-Basket Recommendation
Dec 26, 2023


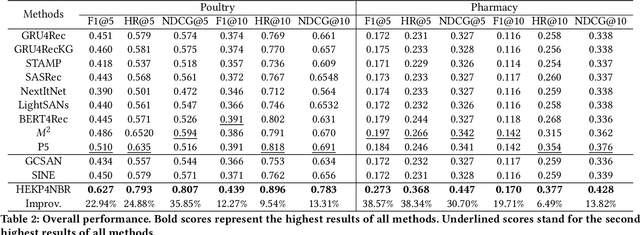
Next-basket recommendation (NBR) aims to infer the items in the next basket given the corresponding basket sequence. Existing NBR methods are mainly based on either message passing in a plain graph or transition modelling in a basket sequence. However, these methods only consider point-to-point binary item relations while item dependencies in real world scenarios are often in higher order. Additionally, the importance of the same item to different users varies due to variation of user preferences, and the relations between items usually involve various aspects. As pretrained language models (PLMs) excel in multiple tasks in natural language processing (NLP) and computer vision (CV), many researchers have made great efforts in utilizing PLMs to boost recommendation. However, existing PLM-based recommendation methods degrade when encountering Out-Of-Vocabulary (OOV) items. OOV items are those whose IDs are out of PLM's vocabulary and thus unintelligible to PLM. To settle the above challenges, we propose a novel method HEKP4NBR, which transforms the knowledge graph (KG) into prompts, namely Knowledge Tree Prompt (KTP), to help PLM encode the OOV item IDs in the user's basket sequence. A hypergraph convolutional module is designed to build a hypergraph based on item similarities measured by an MoE model from multiple aspects and then employ convolution on the hypergraph to model correlations among multiple items. Extensive experiments are conducted on HEKP4NBR on two datasets based on real company data and validate its effectiveness against multiple state-of-the-art methods.
Knowledge Prompt-tuning for Sequential Recommendation
Aug 14, 2023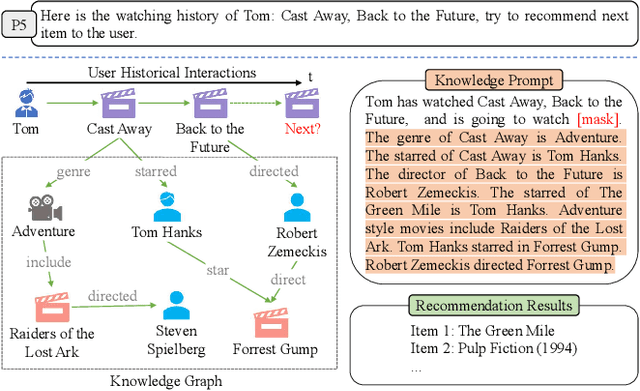
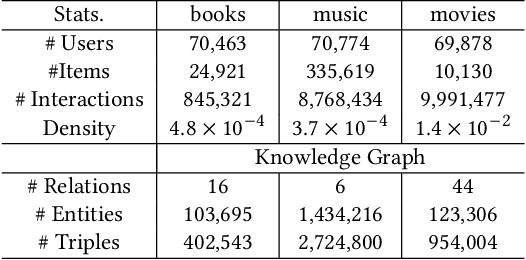
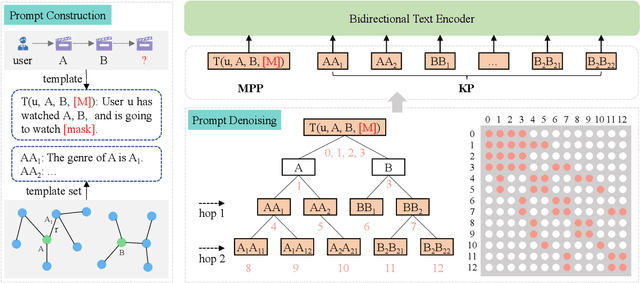
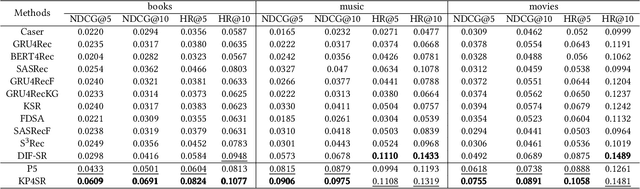
Pre-trained language models (PLMs) have demonstrated strong performance in sequential recommendation (SR), which are utilized to extract general knowledge. However, existing methods still lack domain knowledge and struggle to capture users' fine-grained preferences. Meanwhile, many traditional SR methods improve this issue by integrating side information while suffering from information loss. To summarize, we believe that a good recommendation system should utilize both general and domain knowledge simultaneously. Therefore, we introduce an external knowledge base and propose Knowledge Prompt-tuning for Sequential Recommendation (\textbf{KP4SR}). Specifically, we construct a set of relationship templates and transform a structured knowledge graph (KG) into knowledge prompts to solve the problem of the semantic gap. However, knowledge prompts disrupt the original data structure and introduce a significant amount of noise. We further construct a knowledge tree and propose a knowledge tree mask, which restores the data structure in a mask matrix form, thus mitigating the noise problem. We evaluate KP4SR on three real-world datasets, and experimental results show that our approach outperforms state-of-the-art methods on multiple evaluation metrics. Specifically, compared with PLM-based methods, our method improves NDCG@5 and HR@5 by \textcolor{red}{40.65\%} and \textcolor{red}{36.42\%} on the books dataset, \textcolor{red}{11.17\%} and \textcolor{red}{11.47\%} on the music dataset, and \textcolor{red}{22.17\%} and \textcolor{red}{19.14\%} on the movies dataset, respectively. Our code is publicly available at the link: \href{https://github.com/zhaijianyang/KP4SR}{\textcolor{blue}{https://github.com/zhaijianyang/KP4SR}.}
GraphSHA: Synthesizing Harder Samples for Class-Imbalanced Node Classification
Jun 16, 2023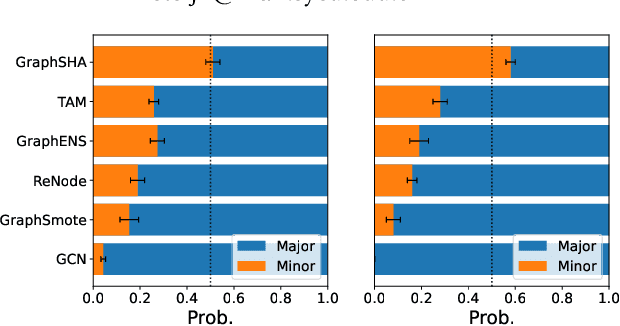
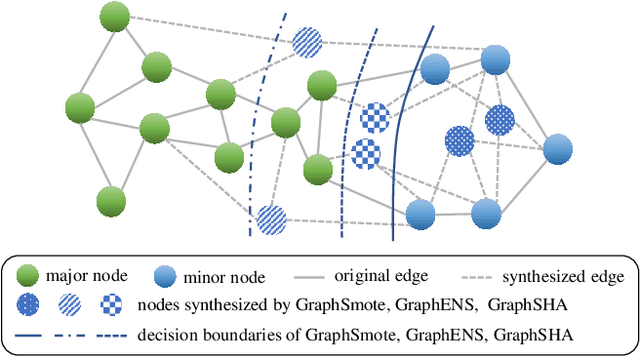
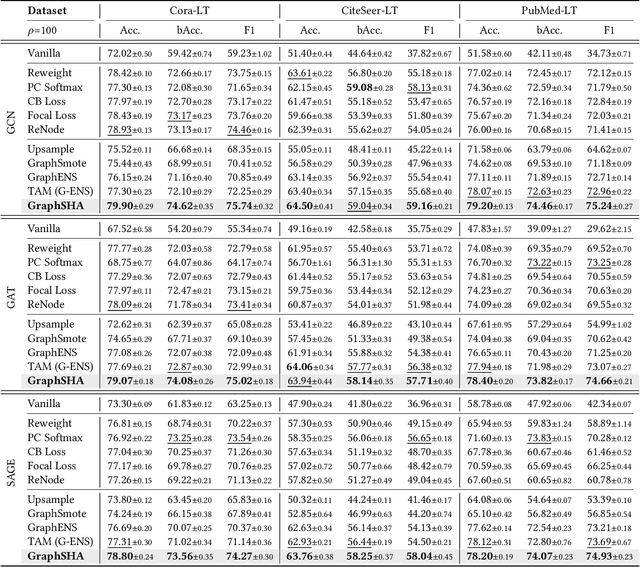
Class imbalance is the phenomenon that some classes have much fewer instances than others, which is ubiquitous in real-world graph-structured scenarios. Recent studies find that off-the-shelf Graph Neural Networks (GNNs) would under-represent minor class samples. We investigate this phenomenon and discover that the subspaces of minor classes being squeezed by those of the major ones in the latent space is the main cause of this failure. We are naturally inspired to enlarge the decision boundaries of minor classes and propose a general framework GraphSHA by Synthesizing HArder minor samples. Furthermore, to avoid the enlarged minor boundary violating the subspaces of neighbor classes, we also propose a module called SemiMixup to transmit enlarged boundary information to the interior of the minor classes while blocking information propagation from minor classes to neighbor classes. Empirically, GraphSHA shows its effectiveness in enlarging the decision boundaries of minor classes, as it outperforms various baseline methods in class-imbalanced node classification with different GNN backbone encoders over seven public benchmark datasets. Code is avilable at https://github.com/wenzhilics/GraphSHA.
HomoGCL: Rethinking Homophily in Graph Contrastive Learning
Jun 16, 2023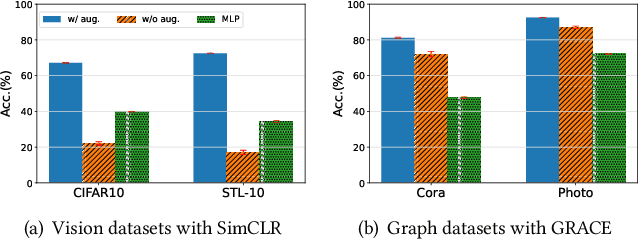
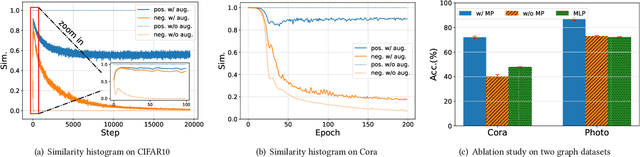
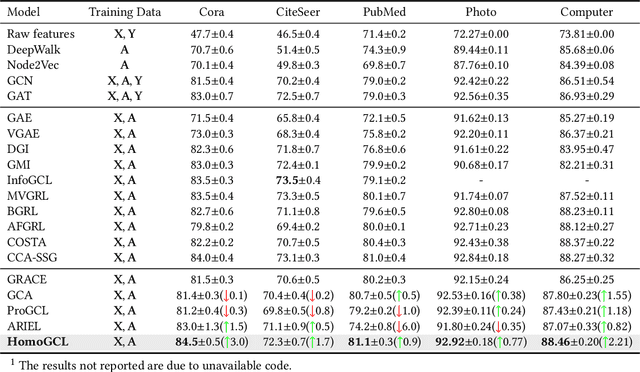
Contrastive learning (CL) has become the de-facto learning paradigm in self-supervised learning on graphs, which generally follows the "augmenting-contrasting" learning scheme. However, we observe that unlike CL in computer vision domain, CL in graph domain performs decently even without augmentation. We conduct a systematic analysis of this phenomenon and argue that homophily, i.e., the principle that "like attracts like", plays a key role in the success of graph CL. Inspired to leverage this property explicitly, we propose HomoGCL, a model-agnostic framework to expand the positive set using neighbor nodes with neighbor-specific significances. Theoretically, HomoGCL introduces a stricter lower bound of the mutual information between raw node features and node embeddings in augmented views. Furthermore, HomoGCL can be combined with existing graph CL models in a plug-and-play way with light extra computational overhead. Extensive experiments demonstrate that HomoGCL yields multiple state-of-the-art results across six public datasets and consistently brings notable performance improvements when applied to various graph CL methods. Code is avilable at https://github.com/wenzhilics/HomoGCL.
One-step Bipartite Graph Cut: A Normalized Formulation and Its Application to Scalable Subspace Clustering
May 12, 2023
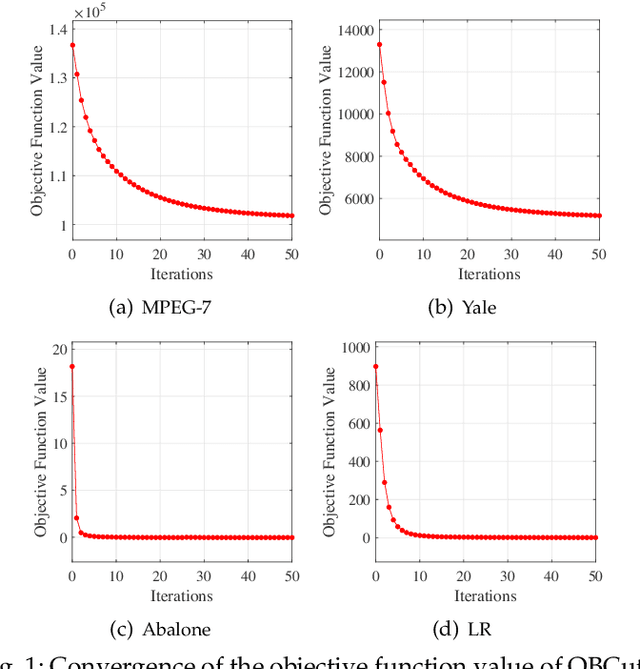
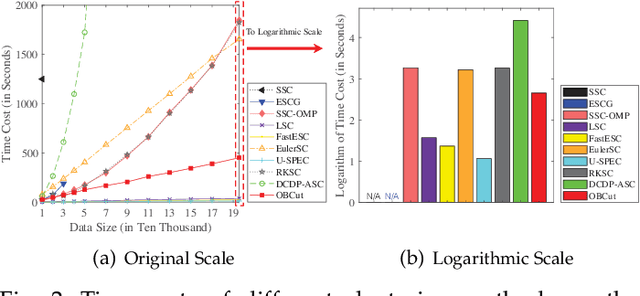
The bipartite graph structure has shown its promising ability in facilitating the subspace clustering and spectral clustering algorithms for large-scale datasets. To avoid the post-processing via k-means during the bipartite graph partitioning, the constrained Laplacian rank (CLR) is often utilized for constraining the number of connected components (i.e., clusters) in the bipartite graph, which, however, neglects the distribution (or normalization) of these connected components and may lead to imbalanced or even ill clusters. Despite the significant success of normalized cut (Ncut) in general graphs, it remains surprisingly an open problem how to enforce a one-step normalized cut for bipartite graphs, especially with linear-time complexity. In this paper, we first characterize a novel one-step bipartite graph cut (OBCut) criterion with normalized constraints, and theoretically prove its equivalence to a trace maximization problem. Then we extend this cut criterion to a scalable subspace clustering approach, where adaptive anchor learning, bipartite graph learning, and one-step normalized bipartite graph partitioning are simultaneously modeled in a unified objective function, and an alternating optimization algorithm is further designed to solve it in linear time. Experiments on a variety of general and large-scale datasets demonstrate the effectiveness and scalability of our approach.
Heterogeneous Tri-stream Clustering Network
Jan 11, 2023Contrastive deep clustering has recently gained significant attention with its ability of joint contrastive learning and clustering via deep neural networks. Despite the rapid progress, previous works mostly require both positive and negative sample pairs for contrastive clustering, which rely on a relative large batch-size. Moreover, they typically adopt a two-stream architecture with two augmented views, which overlook the possibility and potential benefits of multi-stream architectures (especially with heterogeneous or hybrid networks). In light of this, this paper presents a new end-to-end deep clustering approach termed Heterogeneous Tri-stream Clustering Network (HTCN). The tri-stream architecture in HTCN consists of three main components, including two weight-sharing online networks and a target network, where the parameters of the target network are the exponential moving average of that of the online networks. Notably, the two online networks are trained by simultaneously (i) predicting the instance representations of the target network and (ii) enforcing the consistency between the cluster representations of the target network and that of the two online networks. Experimental results on four challenging image datasets demonstrate the superiority of HTCN over the state-of-the-art deep clustering approaches. The code is available at https://github.com/dengxiaozhi/HTCN.
Deep Temporal Contrastive Clustering
Dec 29, 2022Recently the deep learning has shown its advantage in representation learning and clustering for time series data. Despite the considerable progress, the existing deep time series clustering approaches mostly seek to train the deep neural network by some instance reconstruction based or cluster distribution based objective, which, however, lack the ability to exploit the sample-wise (or augmentation-wise) contrastive information or even the higher-level (e.g., cluster-level) contrastiveness for learning discriminative and clustering-friendly representations. In light of this, this paper presents a deep temporal contrastive clustering (DTCC) approach, which for the first time, to our knowledge, incorporates the contrastive learning paradigm into the deep time series clustering research. Specifically, with two parallel views generated from the original time series and their augmentations, we utilize two identical auto-encoders to learn the corresponding representations, and in the meantime perform the cluster distribution learning by incorporating a k-means objective. Further, two levels of contrastive learning are simultaneously enforced to capture the instance-level and cluster-level contrastive information, respectively. With the reconstruction loss of the auto-encoder, the cluster distribution loss, and the two levels of contrastive losses jointly optimized, the network architecture is trained in a self-supervised manner and the clustering result can thereby be obtained. Experiments on a variety of time series datasets demonstrate the superiority of our DTCC approach over the state-of-the-art.