 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphLoRA: Structure-Aware Contrastive Low-Rank Adaptation for Cross-Graph Transfer Learning
Sep 25, 2024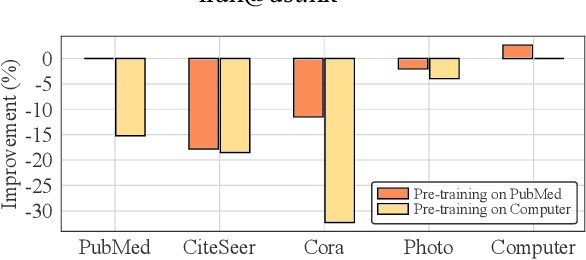
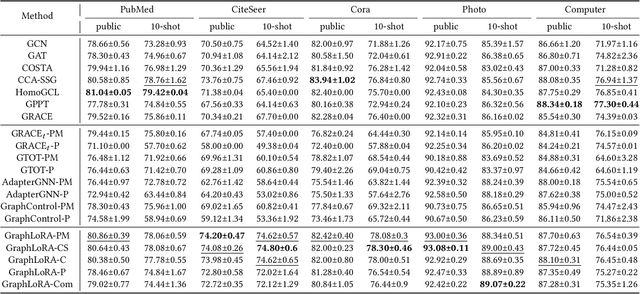
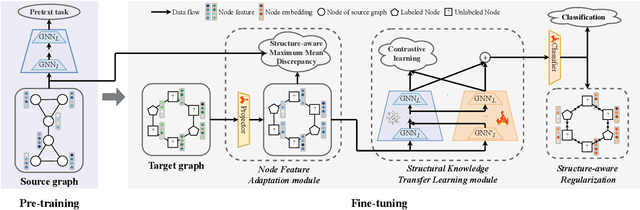
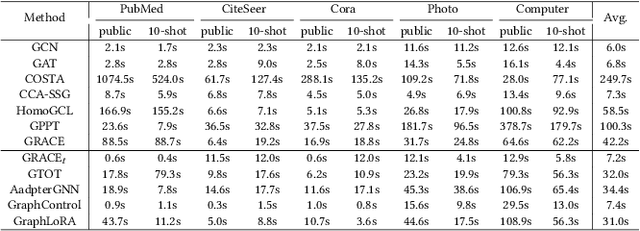
Graph Neural Networks (GNNs) have demonstrated remarkable proficiency in handling a range of graph analytical tasks across various domains, such as e-commerce and social networks. Despite their versatility, GNNs face significant challenges in transferability, limiting their utility in real-world applications. Existing research in GNN transfer learning overlooks discrepancies in distribution among various graph datasets, facing challenges when transferring across different distributions. How to effectively adopt a well-trained GNN to new graphs with varying feature and structural distributions remains an under-explored problem. Taking inspiration from the success of Low-Rank Adaptation (LoRA) in adapting large language models to various domains, we propose GraphLoRA, an effective and parameter-efficient method for transferring well-trained GNNs to diverse graph domains. Specifically, we first propose a Structure-aware Maximum Mean Discrepancy (SMMD) to align divergent node feature distributions across source and target graphs. Moreover, we introduce low-rank adaptation by injecting a small trainable GNN alongside the pre-trained one, effectively bridging structural distribution gaps while mitigating the catastrophic forgetting. Additionally, a structure-aware regularization objective is proposed to enhance the adaptability of the pre-trained GNN to target graph with scarce supervision labels. Extensive experiments on six real-world datasets demonstrate the effectiveness of GraphLoRA against eleven baselines by tuning only 20% of parameters, even across disparate graph domains. The code is available at https://anonymous.4open.science/r/GraphLoRA.
Erase then Rectify: A Training-Free Parameter Editing Approach for Cost-Effective Graph Unlearning
Sep 25, 2024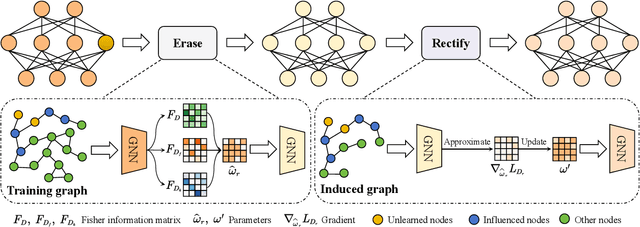
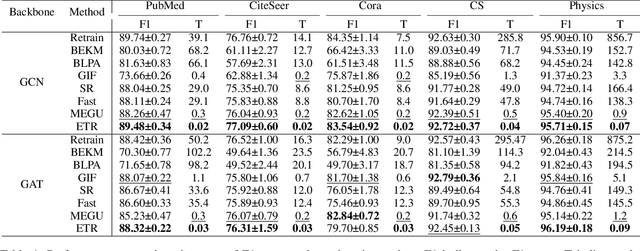
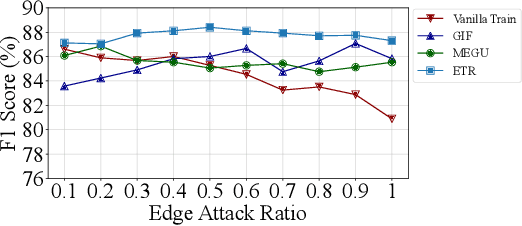
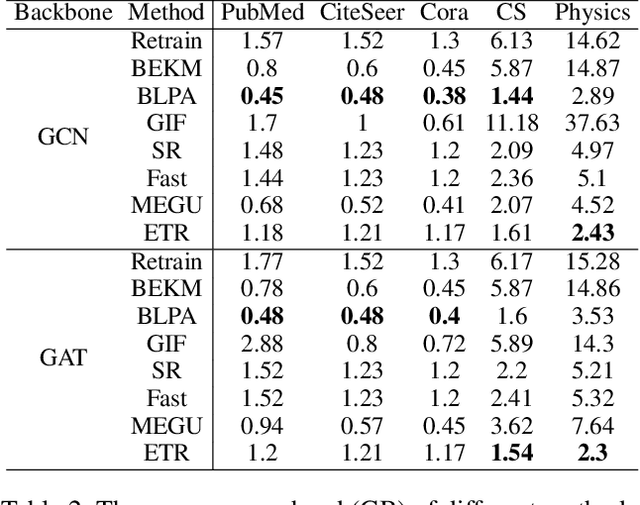
Graph unlearning, which aims to eliminate the influence of specific nodes, edges, or attributes from a trained Graph Neural Network (GNN), is essential in applications where privacy, bias, or data obsolescence is a concern. However, existing graph unlearning techniques often necessitate additional training on the remaining data, leading to significant computational costs, particularly with large-scale graphs. To address these challenges, we propose a two-stage training-free approach, Erase then Rectify (ETR), designed for efficient and scalable graph unlearning while preserving the model utility. Specifically, we first build a theoretical foundation showing that masking parameters critical for unlearned samples enables effective unlearning. Building on this insight, the Erase stage strategically edits model parameters to eliminate the impact of unlearned samples and their propagated influence on intercorrelated nodes. To further ensure the GNN's utility, the Rectify stage devises a gradient approximation method to estimate the model's gradient on the remaining dataset, which is then used to enhance model performance. Overall, ETR achieves graph unlearning without additional training or full training data access, significantly reducing computational overhead and preserving data privacy. Extensive experiments on seven public datasets demonstrate the consistent superiority of ETR in model utility, unlearning efficiency, and unlearning effectiveness, establishing it as a promising solution for real-world graph unlearning challenges.