 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExamGAN and Twin-ExamGAN for Exam Script Generation
Aug 22, 2021
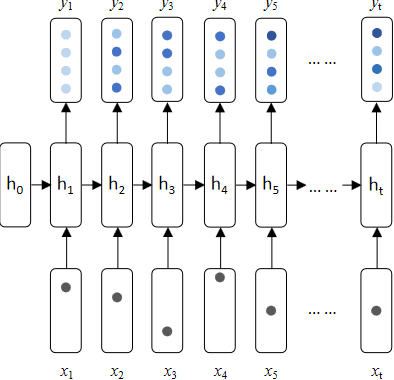
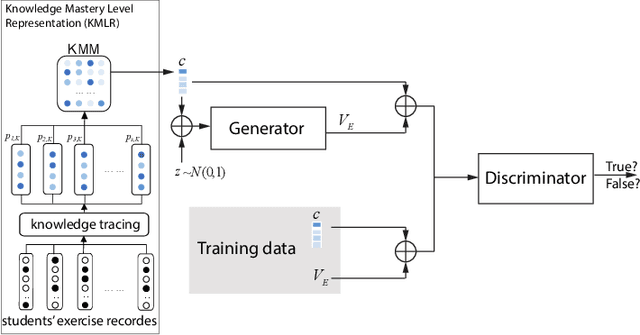

Nowadays, the learning management system (LMS) has been widely used in different educational stages from primary to tertiary education for student administration, documentation, tracking, reporting, and delivery of educational courses, training programs, or learning and development programs. Towards effective learning outcome assessment, the exam script generation problem has attracted many attentions and been investigated recently. But the research in this field is still in its early stage. There are opportunities to further improve the quality of generated exam scripts in various aspects. In particular, two essential issues have been ignored largely by existing solutions. First, given a course, it is unknown yet how to generate an exam script which can result in a desirable distribution of student scores in a class (or across different classes). Second, while it is frequently encountered in practice, it is unknown so far how to generate a pair of high quality exam scripts which are equivalent in assessment (i.e., the student scores are comparable by taking either of them) but have significantly different sets of questions. To fill the gap, this paper proposes ExamGAN (Exam Script Generative Adversarial Network) to generate high quality exam scripts, and then extends ExamGAN to T-ExamGAN (Twin-ExamGAN) to generate a pair of high quality exam scripts. Based on extensive experiments on three benchmark datasets, it has verified the superiority of proposed solutions in various aspects against the state-of-the-art. Moreover, we have conducted a case study which demonstrated the effectiveness of proposed solution in a real teaching scenario.
Rank Position Forecasting in Car Racing
Oct 23, 2020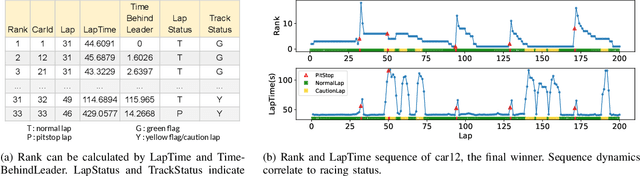
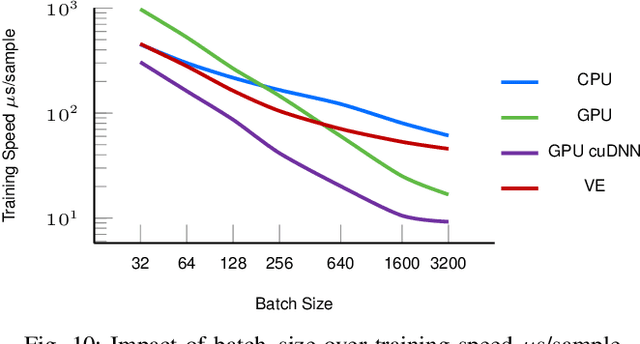
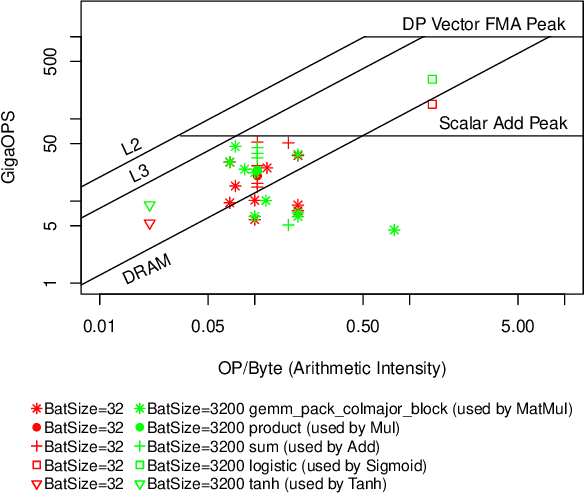
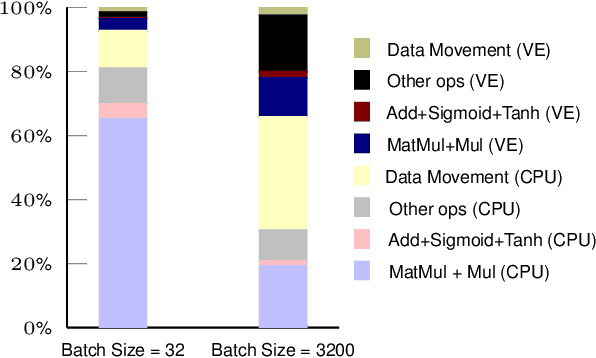
Forecasting is challenging since uncertainty resulted from exogenous factors exists. This work investigates the rank position forecasting problem in car racing, which predicts the rank positions at the future laps for cars. Among the many factors that bring changes to the rank positions, pit stops are critical but irregular and rare. We found existing methods, including statistical models, machine learning regression models, and state-of-the-art deep forecasting model based on encoder-decoder architecture, all have limitations in the forecasting. By elaborative analysis of pit stops events, we propose a deep model, RankNet, with the cause effects decomposition that modeling the rank position sequence and pit stop events separately. It also incorporates probabilistic forecasting to model the uncertainty inside each sub-model. Through extensive experiments, RankNet demonstrates a strong performance improvement over the baselines, e.g., MAE improves more than 10% consistently, and is also more stable when adapting to unseen new data. Details of model optimization, performance profiling are presented. It is promising to provide useful forecasting tools for the car racing analysis and shine a light on solutions to similar challenging issues in general forecasting problems.
A Hybrid Supervised-unsupervised Method on Image Topic Visualization with Convolutional Neural Network and LDA
Apr 09, 2017
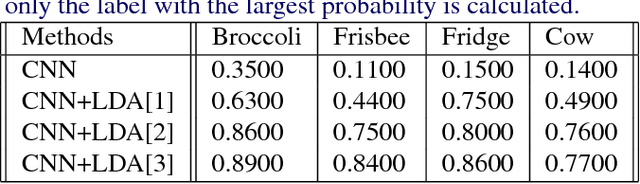


Given the progress in image recognition with recent data driven paradigms, it's still expensive to manually label a large training data to fit a convolutional neural network (CNN) model. This paper proposes a hybrid supervised-unsupervised method combining a pre-trained AlexNet with Latent Dirichlet Allocation (LDA) to extract image topics from both an unlabeled life-logging dataset and the COCO dataset. We generate the bag-of-words representations of an egocentric dataset from the softmax layer of AlexNet and use LDA to visualize the subject's living genre with duplicated images. We use a subset of COCO on 4 categories as ground truth, and define consistent rate to quantitatively analyze the performance of the method, it achieves 84% for consistent rate on average comparing to 18.75% from a raw CNN model. The method is capable of detecting false labels and multi-labels from COCO dataset. For scalability test, parallelization experiments are conducted with Harp-LDA on a Intel Knights Landing cluster: to extract 1,000 topic assignments for 241,035 COCO images, it takes 10 minutes with 60 threads.