 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFault Tolerance in Iterative-Convergent Machine Learning
Oct 17, 2018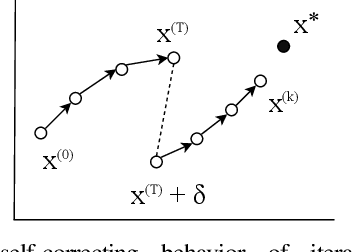
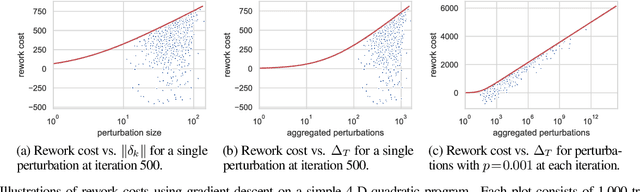
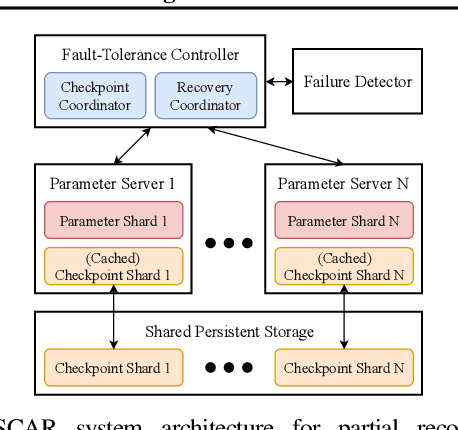
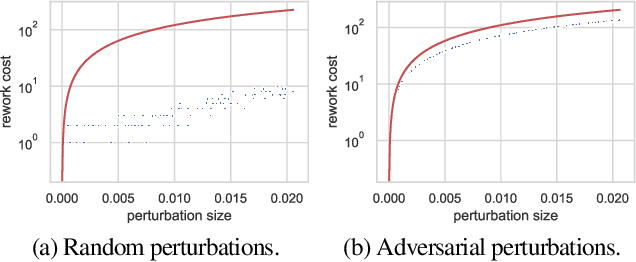
Machine learning (ML) training algorithms often possess an inherent self-correcting behavior due to their iterative-convergent nature. Recent systems exploit this property to achieve adaptability and efficiency in unreliable computing environments by relaxing the consistency of execution and allowing calculation errors to be self-corrected during training. However, the behavior of such systems are only well understood for specific types of calculation errors, such as those caused by staleness, reduced precision, or asynchronicity, and for specific types of training algorithms, such as stochastic gradient descent. In this paper, we develop a general framework to quantify the effects of calculation errors on iterative-convergent algorithms and use this framework to design new strategies for checkpoint-based fault tolerance. Our framework yields a worst-case upper bound on the iteration cost of arbitrary perturbations to model parameters during training. Our system, SCAR, employs strategies which reduce the iteration cost upper bound due to perturbations incurred when recovering from checkpoints. We show that SCAR can reduce the iteration cost of partial failures by 78% - 95% when compared with traditional checkpoint-based fault tolerance across a variety of ML models and training algorithms.
A Hybrid Supervised-unsupervised Method on Image Topic Visualization with Convolutional Neural Network and LDA
Apr 09, 2017
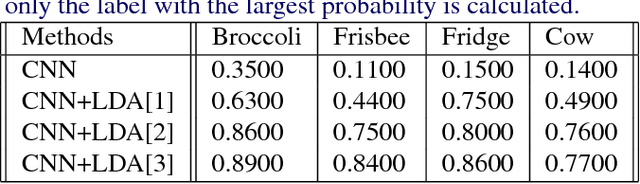


Given the progress in image recognition with recent data driven paradigms, it's still expensive to manually label a large training data to fit a convolutional neural network (CNN) model. This paper proposes a hybrid supervised-unsupervised method combining a pre-trained AlexNet with Latent Dirichlet Allocation (LDA) to extract image topics from both an unlabeled life-logging dataset and the COCO dataset. We generate the bag-of-words representations of an egocentric dataset from the softmax layer of AlexNet and use LDA to visualize the subject's living genre with duplicated images. We use a subset of COCO on 4 categories as ground truth, and define consistent rate to quantitatively analyze the performance of the method, it achieves 84% for consistent rate on average comparing to 18.75% from a raw CNN model. The method is capable of detecting false labels and multi-labels from COCO dataset. For scalability test, parallelization experiments are conducted with Harp-LDA on a Intel Knights Landing cluster: to extract 1,000 topic assignments for 241,035 COCO images, it takes 10 minutes with 60 threads.