 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFollowing Gaze Across Views
Paper and Code
Dec 09, 2016


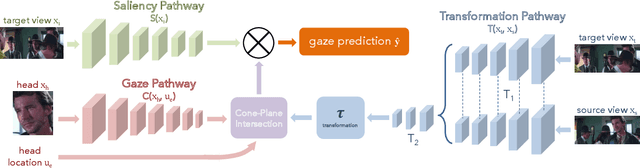
Following the gaze of people inside videos is an important signal for understanding people and their actions. In this paper, we present an approach for following gaze across views by predicting where a particular person is looking throughout a scene. We collect VideoGaze, a new dataset which we use as a benchmark to both train and evaluate models. Given one view with a person in it and a second view of the scene, our model estimates a density for gaze location in the second view. A key aspect of our approach is an end-to-end model that solves the following sub-problems: saliency, gaze pose, and geometric relationships between views. Although our model is supervised only with gaze, we show that the model learns to solve these subproblems automatically without supervision. Experiments suggest that our approach follows gaze better than standard baselines and produces plausible results for everyday situations.