 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Efficient Language Model Pretraining and Downstream Adaptation via Self-Evolution: A Case Study on SuperGLUE
Dec 04, 2022



This technical report briefly describes our JDExplore d-team's Vega v2 submission on the SuperGLUE leaderboard. SuperGLUE is more challenging than the widely used general language understanding evaluation (GLUE) benchmark, containing eight difficult language understanding tasks, including question answering, natural language inference, word sense disambiguation, coreference resolution, and reasoning. [Method] Instead of arbitrarily increasing the size of a pretrained language model (PLM), our aim is to 1) fully extract knowledge from the input pretraining data given a certain parameter budget, e.g., 6B, and 2) effectively transfer this knowledge to downstream tasks. To achieve goal 1), we propose self-evolution learning for PLMs to wisely predict the informative tokens that should be masked, and supervise the masked language modeling (MLM) process with rectified smooth labels. For goal 2), we leverage the prompt transfer technique to improve the low-resource tasks by transferring the knowledge from the foundation model and related downstream tasks to the target task. [Results] According to our submission record (Oct. 2022), with our optimized pretraining and fine-tuning strategies, our 6B Vega method achieved new state-of-the-art performance on 4/8 tasks, sitting atop the SuperGLUE leaderboard on Oct. 8, 2022, with an average score of 91.3.
InterFaceGAN: Interpreting the Disentangled Face Representation Learned by GANs
May 18, 2020
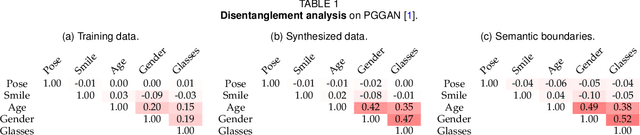
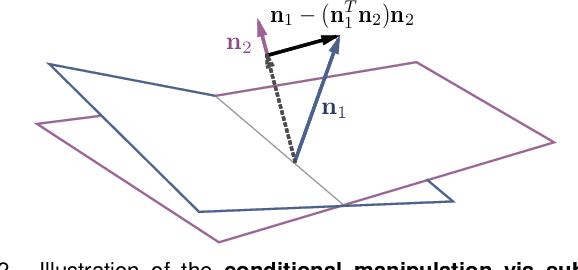
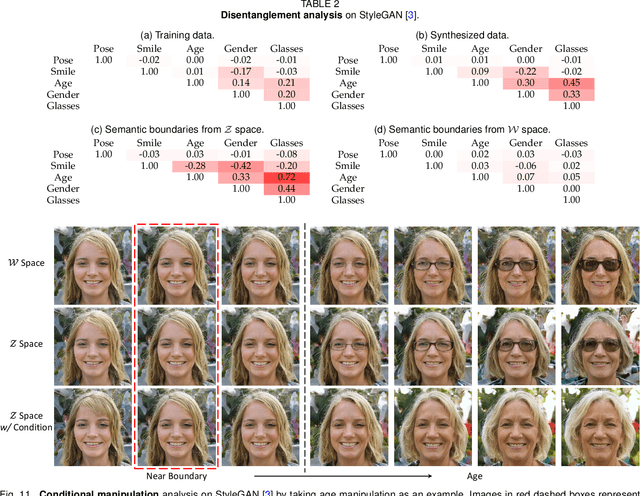
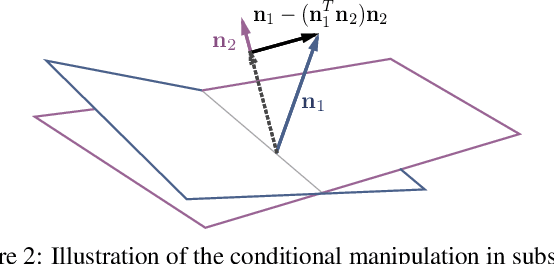
Although Generative Adversarial Networks (GANs) have made significant progress in face synthesis, there lacks enough understanding of what GANs have learned in the latent representation to map a randomly sampled code to a photo-realistic face image. In this work, we propose a framework, called InterFaceGAN, to interpret the disentangled face representation learned by the state-of-the-art GAN models and thoroughly analyze the properties of the facial semantics in the latent space. We first find that GANs actually learn various semantics in some linear subspaces of the latent space when being trained to synthesize high-quality faces. After identifying the subspaces of the corresponding latent semantics, we are able to realistically manipulate the facial attributes occurring in the synthesized images without retraining the model. We then conduct a detailed study on the correlation between different semantics and manage to better disentangle them via subspace projection, resulting in more precise control of the attribute manipulation. Besides manipulating gender, age, expression, and the presence of eyeglasses, we can even alter the face pose as well as fix the artifacts accidentally generated by GANs. Furthermore, we perform in-depth face identity analysis and layer-wise analysis to quantitatively evaluate the editing results. Finally, we apply our approach to real face editing by involving GAN inversion approaches as well as explicitly training additional feed-forward models based on the synthetic data established by InterFaceGAN. Extensive experimental results suggest that learning to synthesize faces spontaneously brings a disentangled and controllable face representation.
Interpreting the Latent Space of GANs for Semantic Face Editing
Jul 25, 2019
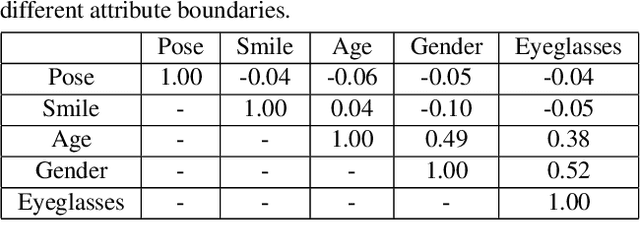

Despite the recent advance of Generative Adversarial Networks (GANs) in high-fidelity image synthesis, there lacks enough understandings on how GANs are able to map the latent code sampled from a random distribution to a photo-realistic image. Previous work assumes the latent space learned by GAN follows a distributed representation but observes the vector arithmetic phenomenon of the output's semantics in latent space. In this work, we interpret the semantics hidden in the latent space of well-trained GANs. We find that the latent code for well-trained generative models, such as ProgressiveGAN and StyleGAN, actually learns a disentangled representation after some linear transformations. We make a rigorous analysis on the encoding of various semantics in the latent space as well as their properties, and then study how these semantics are correlated to each other. Based on our analysis, we propose a simple and general technique, called InterFaceGAN, for semantic face editing in latent space. Given a synthesized face, we are able to faithfully edit its various attributes such as pose, expression, age, presence of eyeglasses, without retraining the GAN model. Furthermore, we show that even the artifacts occurred in output images are able to be fixed using same approach. Extensive results suggest that learning to synthesize faces spontaneously brings a disentangled and controllable facial attribute representation
Path-Restore: Learning Network Path Selection for Image Restoration
Apr 23, 2019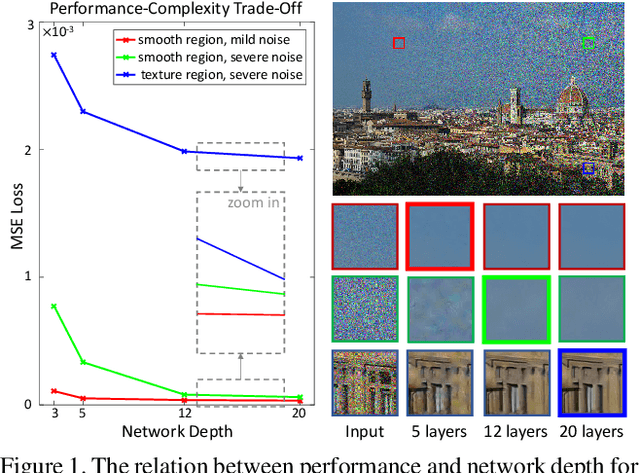
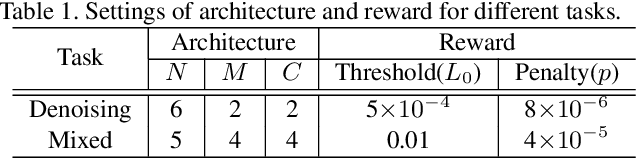
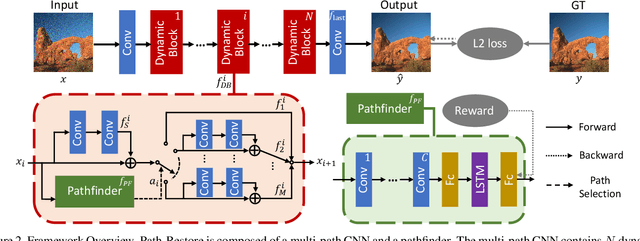
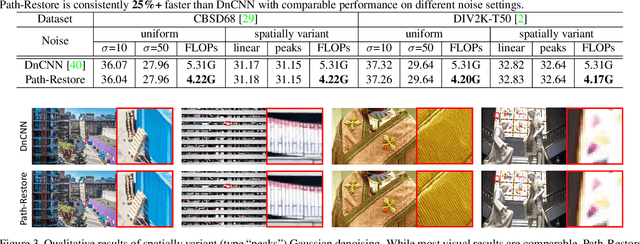
Very deep Convolutional Neural Networks (CNNs) have greatly improved the performance on various image restoration tasks. However, this comes at a price of increasing computational burden, which limits their practical usages. We believe that some corrupted image regions are inherently easier to restore than others since the distortion and content vary within an image. To this end, we propose Path-Restore, a multi-path CNN with a pathfinder that could dynamically select an appropriate route for each image region. We train the pathfinder using reinforcement learning with a difficulty-regulated reward, which is related to the performance, complexity and "the difficulty of restoring a region". We conduct experiments on denoising and mixed restoration tasks. The results show that our method could achieve comparable or superior performance to existing approaches with less computational cost. In particular, our method is effective for real-world denoising, where the noise distribution varies across different regions of a single image. We surpass the state-of-the-art CBDNet by 0.94 dB and run 29% faster on the realistic Darmstadt Noise Dataset. Models and codes will be released.
Switchable Whitening for Deep Representation Learning
Apr 22, 2019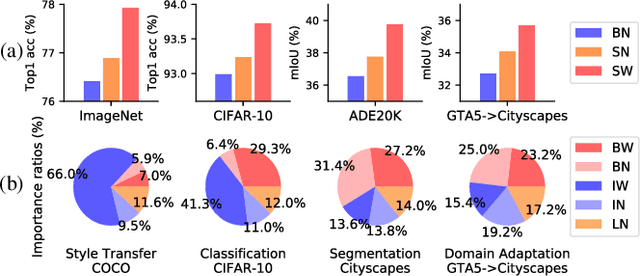

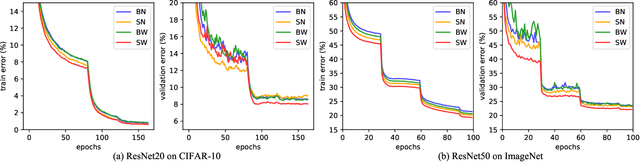
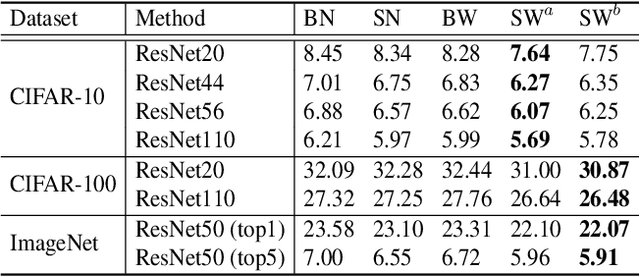
Normalization methods are essential components in convolutional neural networks (CNNs). They either standardize or whiten data using statistics estimated in predefined sets of pixels. Unlike existing works that design normalization techniques for specific tasks, we propose Switchable Whitening (SW), which provides a general form unifying different whitening methods as well as standardization methods. SW learns to switch among these operations in an end-to-end manner. It has several advantages. First, SW adaptively selects appropriate whitening or standardization statistics for different tasks (see Fig.1), making it well suited for a wide range of tasks without manual design. Second, by integrating benefits of different normalizers, SW shows consistent improvements over its counterparts in various challenging benchmarks. Third, SW serves as a useful tool for understanding the characteristics of whitening and standardization techniques. We show that SW outperforms other alternatives on image classification (CIFAR-10/100, ImageNet), semantic segmentation (ADE20K, Cityscapes), domain adaptation (GTA5, Cityscapes), and image style transfer (COCO). For example, without bells and whistles, we achieve state-of-the-art performance with 45.33% mIoU on the ADE20K dataset. Code and models will be released.
A Lightweight Optical Flow CNN - Revisiting Data Fidelity and Regularization
Mar 15, 2019

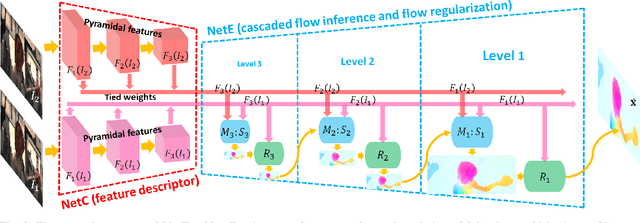
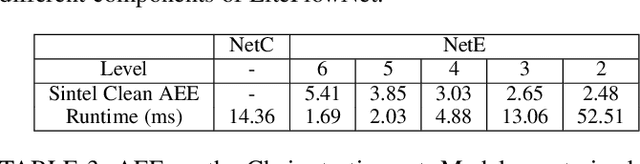
Over four decades, the majority addresses the problem of optical flow estimation using variational methods. With the advance of machine learning, some recent works have attempted to address the problem using convolutional neural network (CNN) and have showed promising results. FlowNet2, the state-of-the-art CNN, requires over 160M parameters to achieve accurate flow estimation. Our LiteFlowNet2 outperforms FlowNet2 on Sintel and KITTI benchmarks, while being 25.3 times smaller in the footprint and 3.1 times faster in the running speed. LiteFlowNet2 which is built on the foundation laid by conventional methods has marked a milestone to achieve the corresponding roles as data fidelity and regularization in variational methods. We present an effective flow inference approach at each pyramid level through a novel lightweight cascaded network. It provides high flow estimation accuracy through early correction with seamless incorporation of descriptor matching. A novel flow regularization layer is used to ameliorate the issue of outliers and vague flow boundaries through a novel feature-driven local convolution. Our network also owns an effective structure for pyramidal feature extraction and embraces feature warping rather than image warping as practiced in FlowNet2. Comparing to our earlier work, LiteFlowNet2 improves the optical flow accuracy on Sintel clean pass by 24%, Sintel final pass by 8.9%, KITTI 2012 by 16.8%, and KITTI 2015 by 17.5%. Our network protocol and trained models will be made publicly available on https://github.com/twhui/LiteFlowNet2 .
DeepFashion2: A Versatile Benchmark for Detection, Pose Estimation, Segmentation and Re-Identification of Clothing Images
Jan 23, 2019
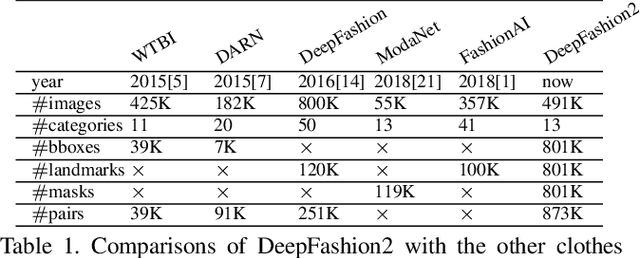


Understanding fashion images has been advanced by benchmarks with rich annotations such as DeepFashion, whose labels include clothing categories, landmarks, and consumer-commercial image pairs. However, DeepFashion has nonnegligible issues such as single clothing-item per image, sparse landmarks (4~8 only), and no per-pixel masks, making it had significant gap from real-world scenarios. We fill in the gap by presenting DeepFashion2 to address these issues. It is a versatile benchmark of four tasks including clothes detection, pose estimation, segmentation, and retrieval. It has 801K clothing items where each item has rich annotations such as style, scale, viewpoint, occlusion, bounding box, dense landmarks and masks. There are also 873K Commercial-Consumer clothes pairs. A strong baseline is proposed, called Match R-CNN, which builds upon Mask R-CNN to solve the above four tasks in an end-to-end manner. Extensive evaluations are conducted with different criterions in DeepFashion2.
Feature Matters: A Stage-by-Stage Approach for Knowledge Transfer
Dec 05, 2018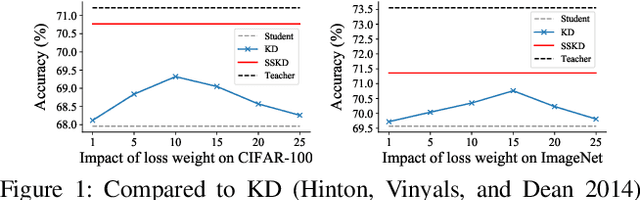

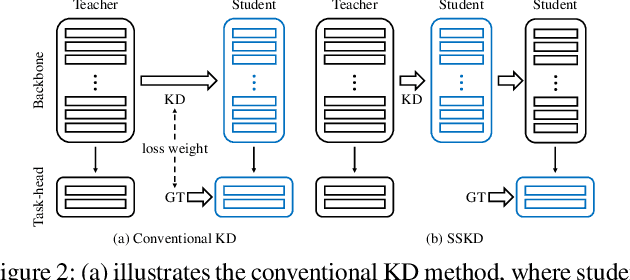
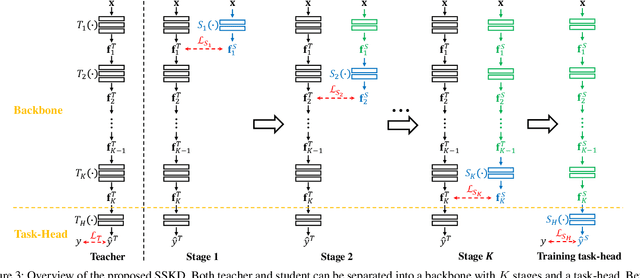
Convolutional Neural Networks (CNNs) become deeper and deeper in recent years, making the study of model acceleration imperative. It is a common practice to employ a shallow network, called student, to learn from a deep one, which is termed as teacher. Prior work made many attempts to transfer different types of knowledge from teacher to student, however, there are two problems remaining unsolved. Firstly, the knowledge used by existing methods is usually manually defined, which may not be consistent with the information learned by the original model. Secondly, there lacks an effective training scheme for the transfer process, leading to degradation of performance. In this work, we argue that feature is the most important knowledge from teacher. It is sufficient for student to achieve appealing performance by just learning similar features as teacher without any processing. Based on this discovery, we further present an efficient learning strategy, which is to make student mimic features of teacher stage by stage. Extensive experiments suggest that the proposed approach significantly narrows down the gap between student and teacher, and shows strong stability on various tasks, ie classification and detection, outperforming the state-of-the-art methods.
FaceFeat-GAN: a Two-Stage Approach for Identity-Preserving Face Synthesis
Dec 04, 2018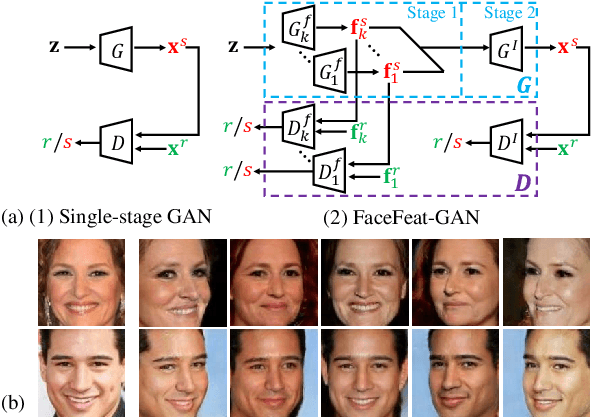

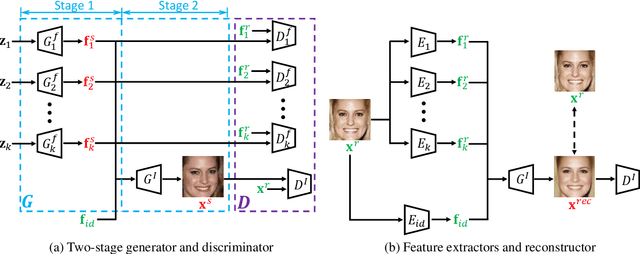
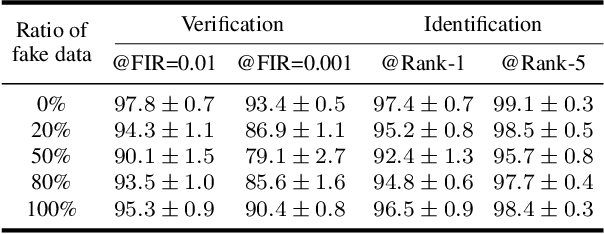
The advance of Generative Adversarial Networks (GANs) enables realistic face image synthesis. However, synthesizing face images that preserve facial identity as well as have high diversity within each identity remains challenging. To address this problem, we present FaceFeat-GAN, a novel generative model that improves both image quality and diversity by using two stages. Unlike existing single-stage models that map random noise to image directly, our two-stage synthesis includes the first stage of diverse feature generation and the second stage of feature-to-image rendering. The competitions between generators and discriminators are carefully designed in both stages with different objective functions. Specially, in the first stage, they compete in the feature domain to synthesize various facial features rather than images. In the second stage, they compete in the image domain to render photo-realistic images that contain high diversity but preserve identity. Extensive experiments show that FaceFeat-GAN generates images that not only retain identity information but also have high diversity and quality, significantly outperforming previous methods.
Deep Network Interpolation for Continuous Imagery Effect Transition
Nov 26, 2018
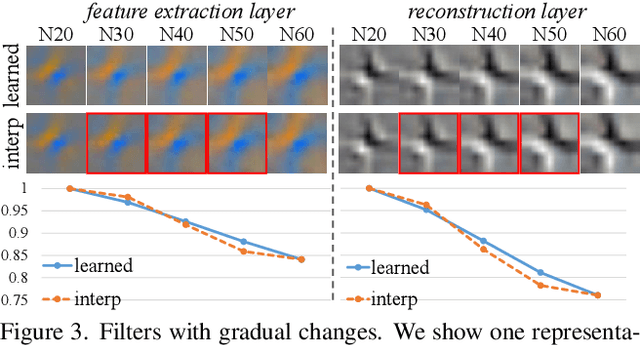
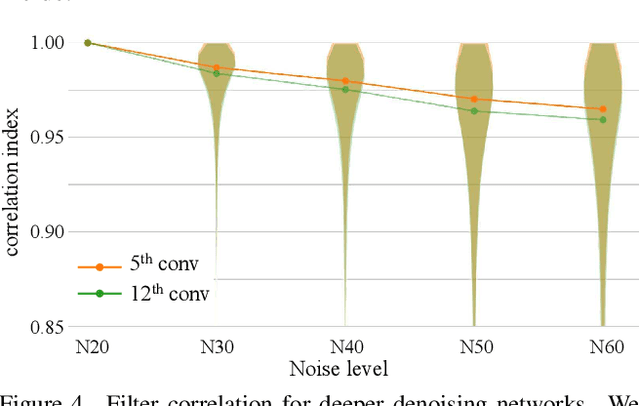

Deep convolutional neural network has demonstrated its capability of learning a deterministic mapping for the desired imagery effect. However, the large variety of user flavors motivates the possibility of continuous transition among different output effects. Unlike existing methods that require a specific design to achieve one particular transition (e.g., style transfer), we propose a simple yet universal approach to attain a smooth control of diverse imagery effects in many low-level vision tasks, including image restoration, image-to-image translation, and style transfer. Specifically, our method, namely Deep Network Interpolation (DNI), applies linear interpolation in the parameter space of two or more correlated networks. A smooth control of imagery effects can be achieved by tweaking the interpolation coefficients. In addition to DNI and its broad applications, we also investigate the mechanism of network interpolation from the perspective of learned filters.