 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpreting the Latent Space of GANs for Semantic Face Editing
Paper and Code

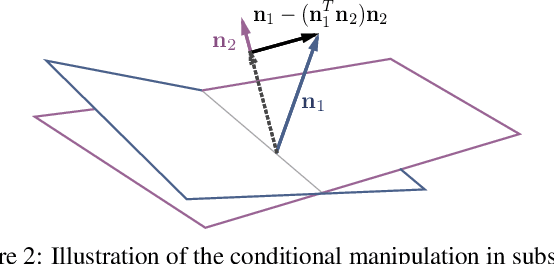
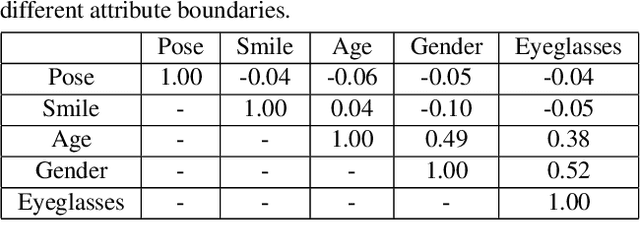

Despite the recent advance of Generative Adversarial Networks (GANs) in high-fidelity image synthesis, there lacks enough understandings on how GANs are able to map the latent code sampled from a random distribution to a photo-realistic image. Previous work assumes the latent space learned by GAN follows a distributed representation but observes the vector arithmetic phenomenon of the output's semantics in latent space. In this work, we interpret the semantics hidden in the latent space of well-trained GANs. We find that the latent code for well-trained generative models, such as ProgressiveGAN and StyleGAN, actually learns a disentangled representation after some linear transformations. We make a rigorous analysis on the encoding of various semantics in the latent space as well as their properties, and then study how these semantics are correlated to each other. Based on our analysis, we propose a simple and general technique, called InterFaceGAN, for semantic face editing in latent space. Given a synthesized face, we are able to faithfully edit its various attributes such as pose, expression, age, presence of eyeglasses, without retraining the GAN model. Furthermore, we show that even the artifacts occurred in output images are able to be fixed using same approach. Extensive results suggest that learning to synthesize faces spontaneously brings a disentangled and controllable facial attribute representation