 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEngiAgent: Fully Connected Coordination of LLM Agents for Solving Open-ended Engineering Problems with Feasible Solutions
May 04, 2026Engineering problem solving is central to real-world decision-making, requiring mathematical formulations that not only represent complex problems but also produce feasible solutions under data and physical constraints. Unlike mathematical problem solving, which operates on predefined formulations, engineering tasks demand open-ended analysis, feasibility-driven modeling, and iterative refinement. Although large language models (LLMs) have shown strong capabilities in reasoning and code generation, they often fail to ensure feasibility, which limits their applicability to engineering problem solving. To address this challenge, we propose EngiAgent, a multi-agent system with a fully connected coordinator that simulates expert workflows through specialized agents for problem analysis, modeling, verification, solving, and solution evaluation. The fully connected coordinator enables flexible feedback routing, overcoming the rigidity of prior pipeline-based reflection methods and ensuring feasibility at every stage of the process. This design not only improves robustness to diverse failure cases such as data extraction errors, constraint inconsistencies, and solver failures, but also enhances the overall quality of problem solving. Empirical results across four representative domains demonstrate that EngiAgent achieves substantial improvements in feasibility compared to prior approaches, establishing a new paradigm for feasibility-oriented engineering problem solving with LLMs. Our source code and data are available at https://github.com/AI4Engi/EngiAgent.
How far have we gone in Generative Image Restoration? A study on its capability, limitations and evaluation practices
Mar 05, 2026Generative Image Restoration (GIR) has achieved impressive perceptual realism, but how far have its practical capabilities truly advanced compared with previous methods? To answer this, we present a large-scale study grounded in a new multi-dimensional evaluation pipeline that assesses models on detail, sharpness, semantic correctness, and overall quality. Our analysis covers diverse architectures, including diffusion-based, GAN-based, PSNR-oriented, and general-purpose generation models, revealing critical performance disparities. Furthermore, our analysis uncovers a key evolution in failure modes that signifies a paradigm shift for the perception-oriented low-level vision field. The central challenge is evolving from the previous problem of detail scarcity (under-generation) to the new frontier of detail quality and semantic control (preventing over-generation). We also leverage our benchmark to train a new IQA model that better aligns with human perceptual judgments. Ultimately, this work provides a systematic study of modern generative image restoration models, offering crucial insights that redefine our understanding of their true state and chart a course for future development.
Position: Evaluation of Visual Processing Should Be Human-Centered, Not Metric-Centered
Feb 28, 2026This position paper argues that the evaluation of modern visual processing systems should no longer be driven primarily by single-metric image quality assessment benchmarks, particularly in the era of generative and perception-oriented methods. Image restoration exemplifies this divergence: while objective IQA metrics enable reproducible, scalable evaluation, they have increasingly drifted apart from human perception and user preferences. We contend that this mismatch risks constraining innovation and misguiding research progress across visual processing tasks. Rather than rejecting metrics altogether, this paper calls for a rebalancing of evaluation paradigms, advocating a more human-centered, context-aware, and fine-grained approach to assessing the visual models' outcomes.
Accelerating Masked Image Generation by Learning Latent Controlled Dynamics
Feb 27, 2026Masked Image Generation Models (MIGMs) have achieved great success, yet their efficiency is hampered by the multiple steps of bi-directional attention. In fact, there exists notable redundancy in their computation: when sampling discrete tokens, the rich semantics contained in the continuous features are lost. Some existing works attempt to cache the features to approximate future features. However, they exhibit considerable approximation error under aggressive acceleration rates. We attribute this to their limited expressivity and the failure to account for sampling information. To fill this gap, we propose to learn a lightweight model that incorporates both previous features and sampled tokens, and regresses the average velocity field of feature evolution. The model has moderate complexity that suffices to capture the subtle dynamics while keeping lightweight compared to the original base model. We apply our method, MIGM-Shortcut, to two representative MIGM architectures and tasks. In particular, on the state-of-the-art Lumina-DiMOO, it achieves over 4x acceleration of text-to-image generation while maintaining quality, significantly pushing the Pareto frontier of masked image generation. The code and model weights are available at https://github.com/Kaiwen-Zhu/MIGM-Shortcut.
Evaluating Parameter Efficient Methods for RLVR
Dec 30, 2025We systematically evaluate Parameter-Efficient Fine-Tuning (PEFT) methods under the paradigm of Reinforcement Learning with Verifiable Rewards (RLVR). RLVR incentivizes language models to enhance their reasoning capabilities through verifiable feedback; however, while methods like LoRA are commonly used, the optimal PEFT architecture for RLVR remains unidentified. In this work, we conduct the first comprehensive evaluation of over 12 PEFT methodologies across the DeepSeek-R1-Distill families on mathematical reasoning benchmarks. Our empirical results challenge the default adoption of standard LoRA with three main findings. First, we demonstrate that structural variants, such as DoRA, AdaLoRA, and MiSS, consistently outperform LoRA. Second, we uncover a spectral collapse phenomenon in SVD-informed initialization strategies (\textit{e.g.,} PiSSA, MiLoRA), attributing their failure to a fundamental misalignment between principal-component updates and RL optimization. Furthermore, our ablations reveal that extreme parameter reduction (\textit{e.g.,} VeRA, Rank-1) severely bottlenecks reasoning capacity. We further conduct ablation studies and scaling experiments to validate our findings. This work provides a definitive guide for advocating for more exploration for parameter-efficient RL methods.
Harnessing Diffusion-Yielded Score Priors for Image Restoration
Jul 28, 2025Deep image restoration models aim to learn a mapping from degraded image space to natural image space. However, they face several critical challenges: removing degradation, generating realistic details, and ensuring pixel-level consistency. Over time, three major classes of methods have emerged, including MSE-based, GAN-based, and diffusion-based methods. However, they fail to achieve a good balance between restoration quality, fidelity, and speed. We propose a novel method, HYPIR, to address these challenges. Our solution pipeline is straightforward: it involves initializing the image restoration model with a pre-trained diffusion model and then fine-tuning it with adversarial training. This approach does not rely on diffusion loss, iterative sampling, or additional adapters. We theoretically demonstrate that initializing adversarial training from a pre-trained diffusion model positions the initial restoration model very close to the natural image distribution. Consequently, this initialization improves numerical stability, avoids mode collapse, and substantially accelerates the convergence of adversarial training. Moreover, HYPIR inherits the capabilities of diffusion models with rich user control, enabling text-guided restoration and adjustable texture richness. Requiring only a single forward pass, it achieves faster convergence and inference speed than diffusion-based methods. Extensive experiments show that HYPIR outperforms previous state-of-the-art methods, achieving efficient and high-quality image restoration.
PhotoArtAgent: Intelligent Photo Retouching with Language Model-Based Artist Agents
May 29, 2025Photo retouching is integral to photographic art, extending far beyond simple technical fixes to heighten emotional expression and narrative depth. While artists leverage expertise to create unique visual effects through deliberate adjustments, non-professional users often rely on automated tools that produce visually pleasing results but lack interpretative depth and interactive transparency. In this paper, we introduce PhotoArtAgent, an intelligent system that combines Vision-Language Models (VLMs) with advanced natural language reasoning to emulate the creative process of a professional artist. The agent performs explicit artistic analysis, plans retouching strategies, and outputs precise parameters to Lightroom through an API. It then evaluates the resulting images and iteratively refines them until the desired artistic vision is achieved. Throughout this process, PhotoArtAgent provides transparent, text-based explanations of its creative rationale, fostering meaningful interaction and user control. Experimental results show that PhotoArtAgent not only surpasses existing automated tools in user studies but also achieves results comparable to those of professional human artists.
Position: Agentic Systems Constitute a Key Component of Next-Generation Intelligent Image Processing
May 21, 2025
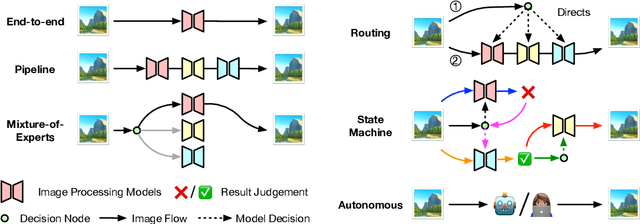
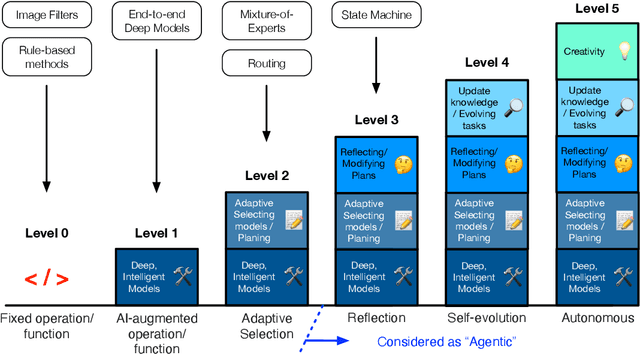
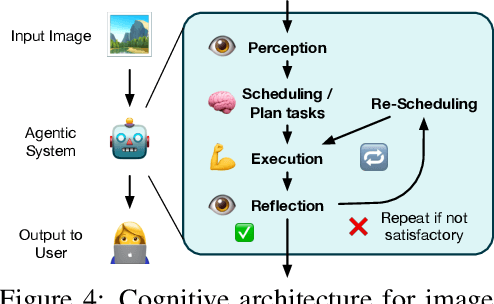
This position paper argues that the image processing community should broaden its focus from purely model-centric development to include agentic system design as an essential complementary paradigm. While deep learning has significantly advanced capabilities for specific image processing tasks, current approaches face critical limitations in generalization, adaptability, and real-world problem-solving flexibility. We propose that developing intelligent agentic systems, capable of dynamically selecting, combining, and optimizing existing image processing tools, represents the next evolutionary step for the field. Such systems would emulate human experts' ability to strategically orchestrate different tools to solve complex problems, overcoming the brittleness of monolithic models. The paper analyzes key limitations of model-centric paradigms, establishes design principles for agentic image processing systems, and outlines different capability levels for such agents.
UniCon: Unidirectional Information Flow for Effective Control of Large-Scale Diffusion Models
Mar 21, 2025We introduce UniCon, a novel architecture designed to enhance control and efficiency in training adapters for large-scale diffusion models. Unlike existing methods that rely on bidirectional interaction between the diffusion model and control adapter, UniCon implements a unidirectional flow from the diffusion network to the adapter, allowing the adapter alone to generate the final output. UniCon reduces computational demands by eliminating the need for the diffusion model to compute and store gradients during adapter training. Our results indicate that UniCon reduces GPU memory usage by one-third and increases training speed by 2.3 times, while maintaining the same adapter parameter size. Additionally, without requiring extra computational resources, UniCon enables the training of adapters with double the parameter volume of existing ControlNets. In a series of image conditional generation tasks, UniCon has demonstrated precise responsiveness to control inputs and exceptional generation capabilities.
Revisiting the Generalization Problem of Low-level Vision Models Through the Lens of Image Deraining
Feb 18, 2025Generalization remains a significant challenge for low-level vision models, which often struggle with unseen degradations in real-world scenarios despite their success in controlled benchmarks. In this paper, we revisit the generalization problem in low-level vision models. Image deraining is selected as a case study due to its well-defined and easily decoupled structure, allowing for more effective observation and analysis. Through comprehensive experiments, we reveal that the generalization issue is not primarily due to limited network capacity but rather the failure of existing training strategies, which leads networks to overfit specific degradation patterns. Our findings show that guiding networks to focus on learning the underlying image content, rather than the degradation patterns, is key to improving generalization. We demonstrate that balancing the complexity of background images and degradations in the training data helps networks better fit the image distribution. Furthermore, incorporating content priors from pre-trained generative models significantly enhances generalization. Experiments on both image deraining and image denoising validate the proposed strategies. We believe the insights and solutions will inspire further research and improve the generalization of low-level vision models.