 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDA-VAE: Plug-in Latent Compression for Diffusion via Detail Alignment
Mar 23, 2026Reducing token count is crucial for efficient training and inference of latent diffusion models, especially at high resolution. A common strategy is to build high-compression image tokenizers with more channels per token. However, when trained only for reconstruction, high-dimensional latent spaces often lose meaningful structure, making diffusion training harder. Existing methods address this with extra objectives such as semantic alignment or selective dropout, but usually require costly diffusion retraining. Pretrained diffusion models, however, already exhibit a structured, lower-dimensional latent space; thus, a simpler idea is to expand the latent dimensionality while preserving this structure. We therefore propose \textbf{D}etail-\textbf{A}ligned VAE, which increases the compression ratio of a pretrained VAE with only lightweight adaptation of the pretrained diffusion backbone. DA-VAE uses an explicit latent layout: the first $C$ channels come directly from the pretrained VAE at a base resolution, while an additional $D$ channels encode higher-resolution details. A simple detail-alignment mechanism encourages the expanded latent space to retain the structure of the original one. With a warm-start fine-tuning strategy, our method enables $1024 \times 1024$ image generation with Stable Diffusion 3.5 using only $32 \times 32$ tokens, $4\times$ fewer than the original model, within 5 H100-days. It further unlocks $2048 \times 2048$ generation with SD3.5, achieving a $6\times$ speedup while preserving image quality. We also validate the method and its design choices quantitatively on ImageNet.
How far have we gone in Generative Image Restoration? A study on its capability, limitations and evaluation practices
Mar 05, 2026Generative Image Restoration (GIR) has achieved impressive perceptual realism, but how far have its practical capabilities truly advanced compared with previous methods? To answer this, we present a large-scale study grounded in a new multi-dimensional evaluation pipeline that assesses models on detail, sharpness, semantic correctness, and overall quality. Our analysis covers diverse architectures, including diffusion-based, GAN-based, PSNR-oriented, and general-purpose generation models, revealing critical performance disparities. Furthermore, our analysis uncovers a key evolution in failure modes that signifies a paradigm shift for the perception-oriented low-level vision field. The central challenge is evolving from the previous problem of detail scarcity (under-generation) to the new frontier of detail quality and semantic control (preventing over-generation). We also leverage our benchmark to train a new IQA model that better aligns with human perceptual judgments. Ultimately, this work provides a systematic study of modern generative image restoration models, offering crucial insights that redefine our understanding of their true state and chart a course for future development.
Position: Evaluation of Visual Processing Should Be Human-Centered, Not Metric-Centered
Feb 28, 2026This position paper argues that the evaluation of modern visual processing systems should no longer be driven primarily by single-metric image quality assessment benchmarks, particularly in the era of generative and perception-oriented methods. Image restoration exemplifies this divergence: while objective IQA metrics enable reproducible, scalable evaluation, they have increasingly drifted apart from human perception and user preferences. We contend that this mismatch risks constraining innovation and misguiding research progress across visual processing tasks. Rather than rejecting metrics altogether, this paper calls for a rebalancing of evaluation paradigms, advocating a more human-centered, context-aware, and fine-grained approach to assessing the visual models' outcomes.
PhotoAgent: Agentic Photo Editing with Exploratory Visual Aesthetic Planning
Feb 26, 2026With the recent fast development of generative models, instruction-based image editing has shown great potential in generating high-quality images. However, the quality of editing highly depends on carefully designed instructions, placing the burden of task decomposition and sequencing entirely on the user. To achieve autonomous image editing, we present PhotoAgent, a system that advances image editing through explicit aesthetic planning. Specifically, PhotoAgent formulates autonomous image editing as a long-horizon decision-making problem. It reasons over user aesthetic intent, plans multi-step editing actions via tree search, and iteratively refines results through closed-loop execution with memory and visual feedback, without requiring step-by-step user prompts. To support reliable evaluation in real-world scenarios, we introduce UGC-Edit, an aesthetic evaluation benchmark consisting of 7,000 photos and a learned aesthetic reward model. We also construct a test set containing 1,017 photos to systematically assess autonomous photo editing performance. Extensive experiments demonstrate that PhotoAgent consistently improves both instruction adherence and visual quality compared with baseline methods. The project page is https://github.com/mdyao/PhotoAgent.
RouteMoA: Dynamic Routing without Pre-Inference Boosts Efficient Mixture-of-Agents
Jan 26, 2026Mixture-of-Agents (MoA) improves LLM performance through layered collaboration, but its dense topology raises costs and latency. Existing methods employ LLM judges to filter responses, yet still require all models to perform inference before judging, failing to cut costs effectively. They also lack model selection criteria and struggle with large model pools, where full inference is costly and can exceed context limits. To address this, we propose RouteMoA, an efficient mixture-of-agents framework with dynamic routing. It employs a lightweight scorer to perform initial screening by predicting coarse-grained performance from the query, narrowing candidates to a high-potential subset without inference. A mixture of judges then refines these scores through lightweight self- and cross-assessment based on existing model outputs, providing posterior correction without additional inference. Finally, a model ranking mechanism selects models by balancing performance, cost, and latency. RouteMoA outperforms MoA across varying tasks and model pool sizes, reducing cost by 89.8% and latency by 63.6% in the large-scale model pool.
RadarQA: Multi-modal Quality Analysis of Weather Radar Forecasts
Aug 17, 2025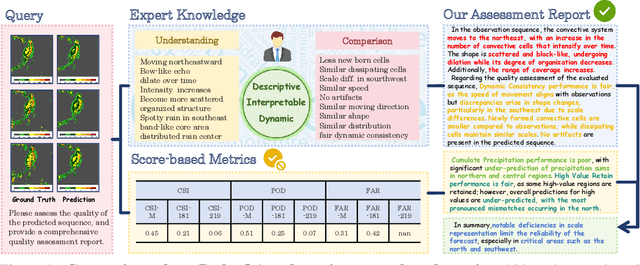
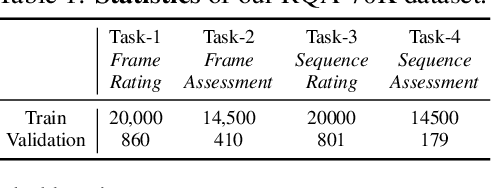

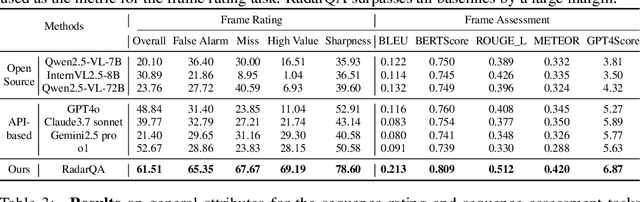
Quality analysis of weather forecasts is an essential topic in meteorology. Although traditional score-based evaluation metrics can quantify certain forecast errors, they are still far from meteorological experts in terms of descriptive capability, interpretability, and understanding of dynamic evolution. With the rapid development of Multi-modal Large Language Models (MLLMs), these models become potential tools to overcome the above challenges. In this work, we introduce an MLLM-based weather forecast analysis method, RadarQA, integrating key physical attributes with detailed assessment reports. We introduce a novel and comprehensive task paradigm for multi-modal quality analysis, encompassing both single frame and sequence, under both rating and assessment scenarios. To support training and benchmarking, we design a hybrid annotation pipeline that combines human expert labeling with automated heuristics. With such an annotation method, we construct RQA-70K, a large-scale dataset with varying difficulty levels for radar forecast quality evaluation. We further design a multi-stage training strategy that iteratively improves model performance at each stage. Extensive experiments show that RadarQA outperforms existing general MLLMs across all evaluation settings, highlighting its potential for advancing quality analysis in weather prediction.
Harnessing Diffusion-Yielded Score Priors for Image Restoration
Jul 28, 2025Deep image restoration models aim to learn a mapping from degraded image space to natural image space. However, they face several critical challenges: removing degradation, generating realistic details, and ensuring pixel-level consistency. Over time, three major classes of methods have emerged, including MSE-based, GAN-based, and diffusion-based methods. However, they fail to achieve a good balance between restoration quality, fidelity, and speed. We propose a novel method, HYPIR, to address these challenges. Our solution pipeline is straightforward: it involves initializing the image restoration model with a pre-trained diffusion model and then fine-tuning it with adversarial training. This approach does not rely on diffusion loss, iterative sampling, or additional adapters. We theoretically demonstrate that initializing adversarial training from a pre-trained diffusion model positions the initial restoration model very close to the natural image distribution. Consequently, this initialization improves numerical stability, avoids mode collapse, and substantially accelerates the convergence of adversarial training. Moreover, HYPIR inherits the capabilities of diffusion models with rich user control, enabling text-guided restoration and adjustable texture richness. Requiring only a single forward pass, it achieves faster convergence and inference speed than diffusion-based methods. Extensive experiments show that HYPIR outperforms previous state-of-the-art methods, achieving efficient and high-quality image restoration.
LMM-R1: Empowering 3B LMMs with Strong Reasoning Abilities Through Two-Stage Rule-Based RL
Mar 11, 2025Enhancing reasoning in Large Multimodal Models (LMMs) faces unique challenges from the complex interplay between visual perception and logical reasoning, particularly in compact 3B-parameter architectures where architectural constraints limit reasoning capacity and modality alignment. While rule-based reinforcement learning (RL) excels in text-only domains, its multimodal extension confronts two critical barriers: (1) data limitations due to ambiguous answers and scarce complex reasoning examples, and (2) degraded foundational reasoning induced by multimodal pretraining. To address these challenges, we propose \textbf{LMM-R1}, a two-stage framework adapting rule-based RL for multimodal reasoning through \textbf{Foundational Reasoning Enhancement (FRE)} followed by \textbf{Multimodal Generalization Training (MGT)}. The FRE stage first strengthens reasoning abilities using text-only data with rule-based RL, then the MGT stage generalizes these reasoning capabilities to multimodal domains. Experiments on Qwen2.5-VL-Instruct-3B demonstrate that LMM-R1 achieves 4.83\% and 4.5\% average improvements over baselines in multimodal and text-only benchmarks, respectively, with a 3.63\% gain in complex Football Game tasks. These results validate that text-based reasoning enhancement enables effective multimodal generalization, offering a data-efficient paradigm that bypasses costly high-quality multimodal training data.
Revisiting the Generalization Problem of Low-level Vision Models Through the Lens of Image Deraining
Feb 18, 2025Generalization remains a significant challenge for low-level vision models, which often struggle with unseen degradations in real-world scenarios despite their success in controlled benchmarks. In this paper, we revisit the generalization problem in low-level vision models. Image deraining is selected as a case study due to its well-defined and easily decoupled structure, allowing for more effective observation and analysis. Through comprehensive experiments, we reveal that the generalization issue is not primarily due to limited network capacity but rather the failure of existing training strategies, which leads networks to overfit specific degradation patterns. Our findings show that guiding networks to focus on learning the underlying image content, rather than the degradation patterns, is key to improving generalization. We demonstrate that balancing the complexity of background images and degradations in the training data helps networks better fit the image distribution. Furthermore, incorporating content priors from pre-trained generative models significantly enhances generalization. Experiments on both image deraining and image denoising validate the proposed strategies. We believe the insights and solutions will inspire further research and improve the generalization of low-level vision models.
UltraFusion: Ultra High Dynamic Imaging using Exposure Fusion
Jan 20, 2025



Capturing high dynamic range (HDR) scenes is one of the most important issues in camera design. Majority of cameras use exposure fusion technique, which fuses images captured by different exposure levels, to increase dynamic range. However, this approach can only handle images with limited exposure difference, normally 3-4 stops. When applying to very high dynamic scenes where a large exposure difference is required, this approach often fails due to incorrect alignment or inconsistent lighting between inputs, or tone mapping artifacts. In this work, we propose UltraFusion, the first exposure fusion technique that can merge input with 9 stops differences. The key idea is that we model the exposure fusion as a guided inpainting problem, where the under-exposed image is used as a guidance to fill the missing information of over-exposed highlight in the over-exposed region. Using under-exposed image as a soft guidance, instead of a hard constrain, our model is robust to potential alignment issue or lighting variations. Moreover, utilizing the image prior of the generative model, our model also generates natural tone mapping, even for very high-dynamic range scene. Our approach outperforms HDR-Transformer on latest HDR benchmarks. Moreover, to test its performance in ultra high dynamic range scene, we capture a new real-world exposure fusion benchmark, UltraFusion Dataset, with exposure difference up to 9 stops, and experiments show that \model~can generate beautiful and high-quality fusion results under various scenarios. An online demo is provided at https://openimaginglab.github.io/UltraFusion/.