 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Generalization of SFT: A Reinforcement Learning Perspective with Reward Rectification
Aug 07, 2025We present a simple yet theoretically motivated improvement to Supervised Fine-Tuning (SFT) for the Large Language Model (LLM), addressing its limited generalization compared to reinforcement learning (RL). Through mathematical analysis, we reveal that standard SFT gradients implicitly encode a problematic reward structure that may severely restrict the generalization capabilities of model. To rectify this, we propose Dynamic Fine-Tuning (DFT), stabilizing gradient updates for each token by dynamically rescaling the objective function with the probability of this token. Remarkably, this single-line code change significantly outperforms standard SFT across multiple challenging benchmarks and base models, demonstrating greatly improved generalization. Additionally, our approach shows competitive results in offline RL settings, offering an effective yet simpler alternative. This work bridges theoretical insight and practical solutions, substantially advancing SFT performance. The code will be available at https://github.com/yongliang-wu/DFT.
Mimic In-Context Learning for Multimodal Tasks
Apr 11, 2025Recently, In-context Learning (ICL) has become a significant inference paradigm in Large Multimodal Models (LMMs), utilizing a few in-context demonstrations (ICDs) to prompt LMMs for new tasks. However, the synergistic effects in multimodal data increase the sensitivity of ICL performance to the configurations of ICDs, stimulating the need for a more stable and general mapping function. Mathematically, in Transformer-based models, ICDs act as ``shift vectors'' added to the hidden states of query tokens. Inspired by this, we introduce Mimic In-Context Learning (MimIC) to learn stable and generalizable shift effects from ICDs. Specifically, compared with some previous shift vector-based methods, MimIC more strictly approximates the shift effects by integrating lightweight learnable modules into LMMs with four key enhancements: 1) inserting shift vectors after attention layers, 2) assigning a shift vector to each attention head, 3) making shift magnitude query-dependent, and 4) employing a layer-wise alignment loss. Extensive experiments on two LMMs (Idefics-9b and Idefics2-8b-base) across three multimodal tasks (VQAv2, OK-VQA, Captioning) demonstrate that MimIC outperforms existing shift vector-based methods. The code is available at https://github.com/Kamichanw/MimIC.
LMM-R1: Empowering 3B LMMs with Strong Reasoning Abilities Through Two-Stage Rule-Based RL
Mar 11, 2025Enhancing reasoning in Large Multimodal Models (LMMs) faces unique challenges from the complex interplay between visual perception and logical reasoning, particularly in compact 3B-parameter architectures where architectural constraints limit reasoning capacity and modality alignment. While rule-based reinforcement learning (RL) excels in text-only domains, its multimodal extension confronts two critical barriers: (1) data limitations due to ambiguous answers and scarce complex reasoning examples, and (2) degraded foundational reasoning induced by multimodal pretraining. To address these challenges, we propose \textbf{LMM-R1}, a two-stage framework adapting rule-based RL for multimodal reasoning through \textbf{Foundational Reasoning Enhancement (FRE)} followed by \textbf{Multimodal Generalization Training (MGT)}. The FRE stage first strengthens reasoning abilities using text-only data with rule-based RL, then the MGT stage generalizes these reasoning capabilities to multimodal domains. Experiments on Qwen2.5-VL-Instruct-3B demonstrate that LMM-R1 achieves 4.83\% and 4.5\% average improvements over baselines in multimodal and text-only benchmarks, respectively, with a 3.63\% gain in complex Football Game tasks. These results validate that text-based reasoning enhancement enables effective multimodal generalization, offering a data-efficient paradigm that bypasses costly high-quality multimodal training data.
Navigating the Unknown: A Chat-Based Collaborative Interface for Personalized Exploratory Tasks
Oct 31, 2024



The rise of large language models (LLMs) has revolutionized user interactions with knowledge-based systems, enabling chatbots to synthesize vast amounts of information and assist with complex, exploratory tasks. However, LLM-based chatbots often struggle to provide personalized support, particularly when users start with vague queries or lack sufficient contextual information. This paper introduces the Collaborative Assistant for Personalized Exploration (CARE), a system designed to enhance personalization in exploratory tasks by combining a multi-agent LLM framework with a structured user interface. CARE's interface consists of a Chat Panel, Solution Panel, and Needs Panel, enabling iterative query refinement and dynamic solution generation. The multi-agent framework collaborates to identify both explicit and implicit user needs, delivering tailored, actionable solutions. In a within-subject user study with 22 participants, CARE was consistently preferred over a baseline LLM chatbot, with users praising its ability to reduce cognitive load, inspire creativity, and provide more tailored solutions. Our findings highlight CARE's potential to transform LLM-based systems from passive information retrievers to proactive partners in personalized problem-solving and exploration.
ICCV23 Visual-Dialog Emotion Explanation Challenge: SEU_309 Team Technical Report
Jul 13, 2024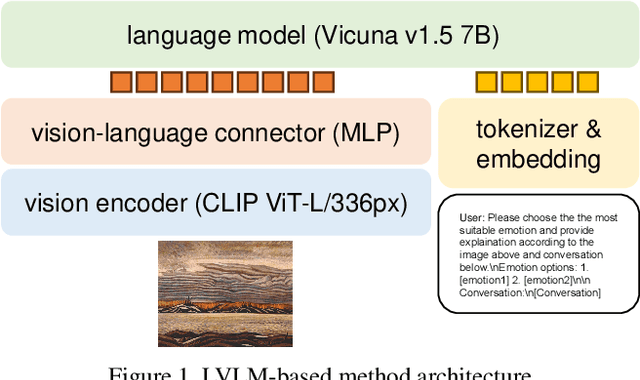

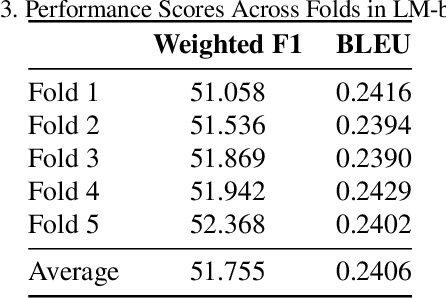
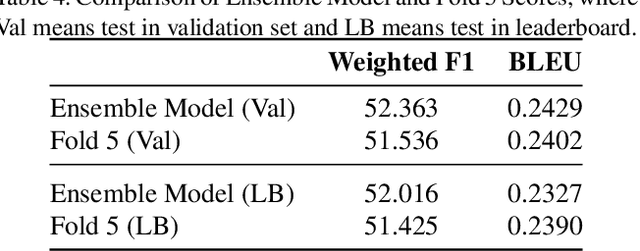
The Visual-Dialog Based Emotion Explanation Generation Challenge focuses on generating emotion explanations through visual-dialog interactions in art discussions. Our approach combines state-of-the-art multi-modal models, including Language Model (LM) and Large Vision Language Model (LVLM), to achieve superior performance. By leveraging these models, we outperform existing benchmarks, securing the top rank in the ICCV23 Visual-Dialog Based Emotion Explanation Generation Challenge, which is part of the 5th Workshop On Closing The Loop Between Vision And Language (CLCV) with significant scores in F1 and BLEU metrics. Our method demonstrates exceptional ability in generating accurate emotion explanations, advancing our understanding of emotional impacts in art.
Learnable In-Context Vector for Visual Question Answering
Jun 19, 2024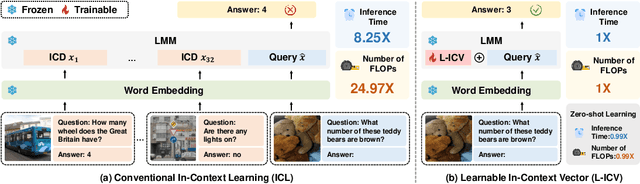
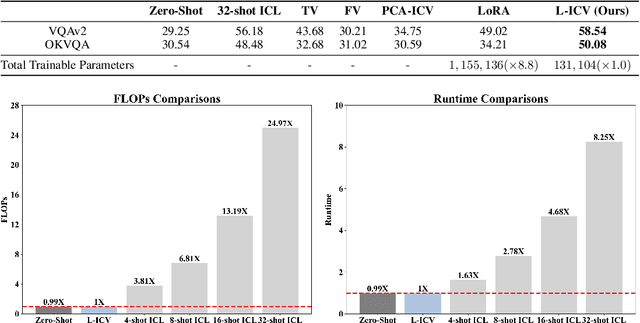
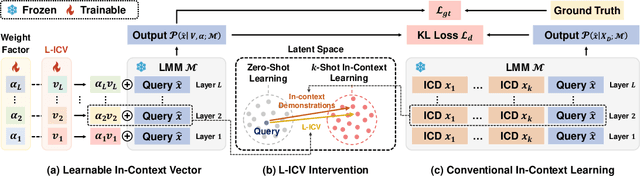
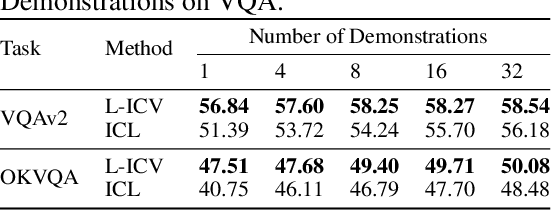
As language models continue to scale, Large Language Models (LLMs) have exhibited emerging capabilities in In-Context Learning (ICL), enabling them to solve language tasks by prefixing a few in-context demonstrations (ICDs) as context. Inspired by these advancements, researchers have extended these techniques to develop Large Multimodal Models (LMMs) with ICL capabilities. However, applying ICL usually faces two major challenges: 1) using more ICDs will largely increase the inference time and 2) the performance is sensitive to the selection of ICDs. These challenges are further exacerbated in LMMs due to the integration of multiple data types and the combinational complexity of multimodal ICDs. Recently, to address these challenges, some NLP studies introduce non-learnable In-Context Vectors (ICVs) which extract useful task information from ICDs into a single vector and then insert it into the LLM to help solve the corresponding task. However, although useful in simple NLP tasks, these non-learnable methods fail to handle complex multimodal tasks like Visual Question Answering (VQA). In this study, we propose \textbf{Learnable ICV} (L-ICV) to distill essential task information from demonstrations, improving ICL performance in LMMs. Experiments show that L-ICV can significantly reduce computational costs while enhancing accuracy in VQA tasks compared to traditional ICL and other non-learnable ICV methods.
ICD-LM: Configuring Vision-Language In-Context Demonstrations by Language Modeling
Dec 22, 2023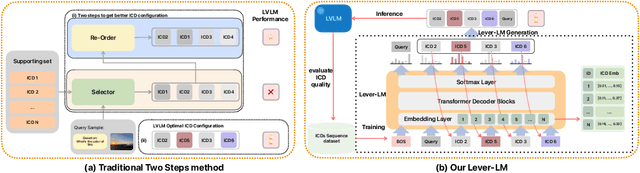
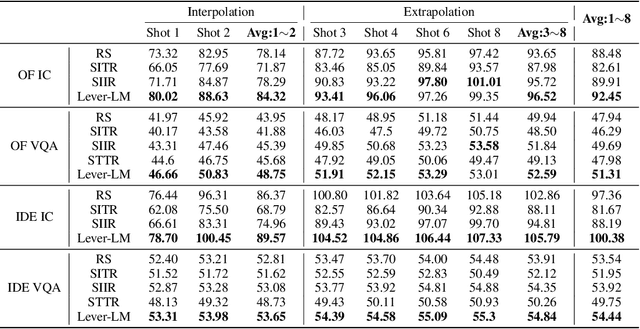
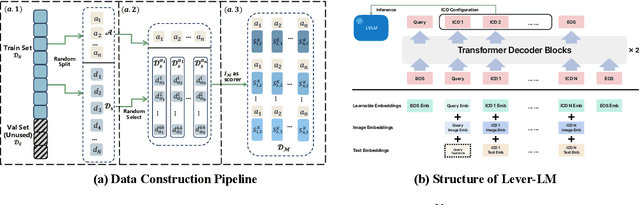
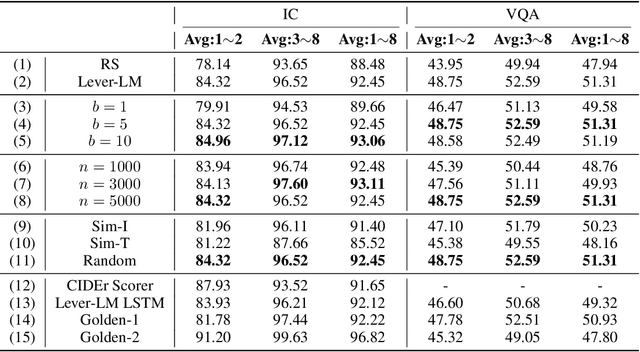
This paper studies how to configure powerful In-Context Demonstration (ICD) sequences for a Large Vision-Language Model (LVLM) to solve Vision-Language tasks through In-Context Learning (ICL). After observing that configuring an ICD sequence is a mirror process of composing a sentence, i.e., just as a sentence can be composed word by word via a Language Model, an ICD sequence can also be configured one by one. Consequently, we introduce an ICD Language Model (ICD-LM) specifically designed to generate effective ICD sequences. This involves creating a dataset of hand-crafted ICD sequences for various query samples and using it to train the ICD-LM. Our approach, diverging from traditional methods in NLP that select and order ICDs separately, enables to simultaneously learn how to select and order ICDs, enhancing the effect of the sequences. Moreover, during data construction, we use the LVLM intended for ICL implementation to validate the strength of each ICD sequence, resulting in a model-specific dataset and the ICD-LM trained by this dataset is also model-specific. We validate our methodology through experiments in Visual Question Answering and Image Captioning, confirming the viability of using a Language Model for ICD configuration. Our comprehensive ablation studies further explore the impact of various dataset construction and ICD-LM development settings on the outcomes. The code is given in https://github.com/ForJadeForest/ICD-LM.