 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniAPO: Unified Multimodal Automated Prompt Optimization
Aug 25, 2025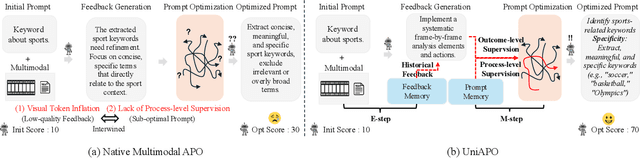
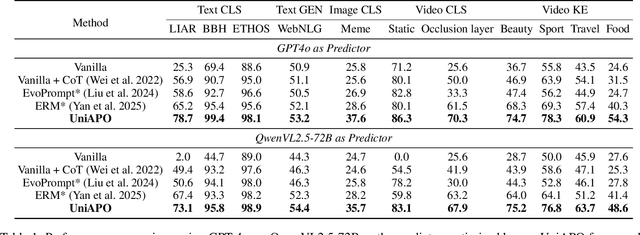
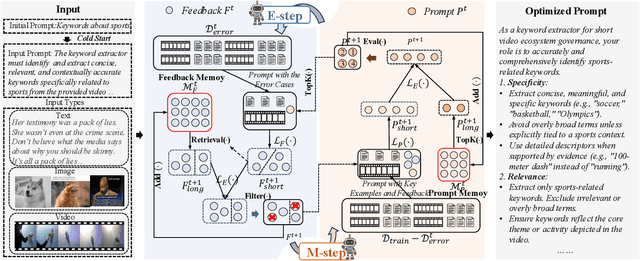
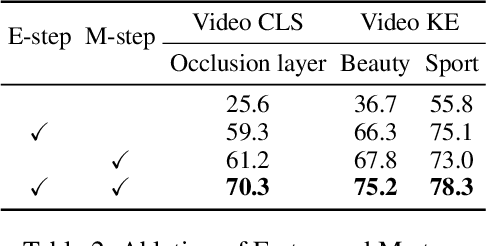
Prompting is fundamental to unlocking the full potential of large language models. To automate and enhance this process, automatic prompt optimization (APO) has been developed, demonstrating effectiveness primarily in text-only input scenarios. However, extending existing APO methods to multimodal tasks, such as video-language generation introduces two core challenges: (i) visual token inflation, where long visual token sequences restrict context capacity and result in insufficient feedback signals; (ii) a lack of process-level supervision, as existing methods focus on outcome-level supervision and overlook intermediate supervision, limiting prompt optimization. We present UniAPO: Unified Multimodal Automated Prompt Optimization, the first framework tailored for multimodal APO. UniAPO adopts an EM-inspired optimization process that decouples feedback modeling and prompt refinement, making the optimization more stable and goal-driven. To further address the aforementioned challenges, we introduce a short-long term memory mechanism: historical feedback mitigates context limitations, while historical prompts provide directional guidance for effective prompt optimization. UniAPO achieves consistent gains across text, image, and video benchmarks, establishing a unified framework for efficient and transferable prompt optimization.
LMM-R1: Empowering 3B LMMs with Strong Reasoning Abilities Through Two-Stage Rule-Based RL
Mar 11, 2025Enhancing reasoning in Large Multimodal Models (LMMs) faces unique challenges from the complex interplay between visual perception and logical reasoning, particularly in compact 3B-parameter architectures where architectural constraints limit reasoning capacity and modality alignment. While rule-based reinforcement learning (RL) excels in text-only domains, its multimodal extension confronts two critical barriers: (1) data limitations due to ambiguous answers and scarce complex reasoning examples, and (2) degraded foundational reasoning induced by multimodal pretraining. To address these challenges, we propose \textbf{LMM-R1}, a two-stage framework adapting rule-based RL for multimodal reasoning through \textbf{Foundational Reasoning Enhancement (FRE)} followed by \textbf{Multimodal Generalization Training (MGT)}. The FRE stage first strengthens reasoning abilities using text-only data with rule-based RL, then the MGT stage generalizes these reasoning capabilities to multimodal domains. Experiments on Qwen2.5-VL-Instruct-3B demonstrate that LMM-R1 achieves 4.83\% and 4.5\% average improvements over baselines in multimodal and text-only benchmarks, respectively, with a 3.63\% gain in complex Football Game tasks. These results validate that text-based reasoning enhancement enables effective multimodal generalization, offering a data-efficient paradigm that bypasses costly high-quality multimodal training data.
Toxic Comments Hunter : Score Severity of Toxic Comments
Feb 15, 2022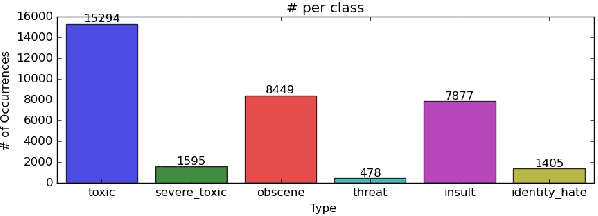


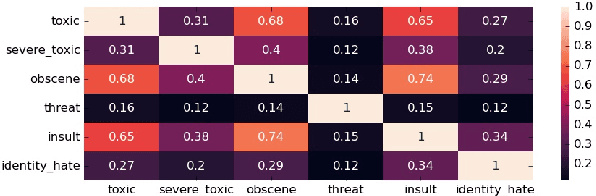
The detection and identification of toxic comments are conducive to creating a civilized and harmonious Internet environment. In this experiment, we collected various data sets related to toxic comments. Because of the characteristics of comment data, we perform data cleaning and feature extraction operations on it from different angles to obtain different toxic comment training sets. In terms of model construction, we used the training set to train the models based on TFIDF and finetuned the Bert model separately. Finally, we encapsulated the code into software to score toxic comments in real-time.