 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICD-LM: Configuring Vision-Language In-Context Demonstrations by Language Modeling
Paper and Code
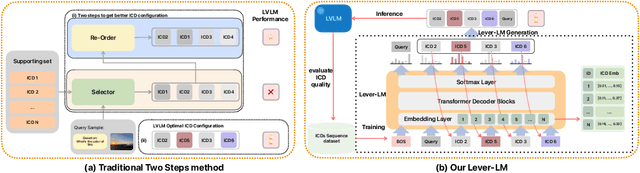
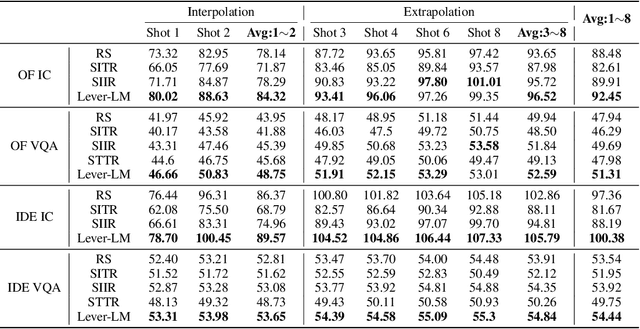
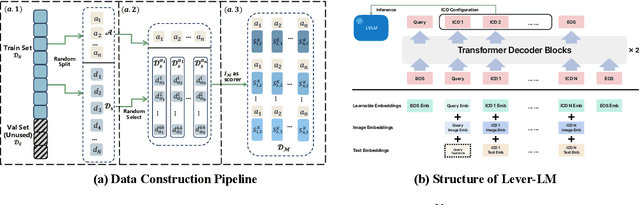
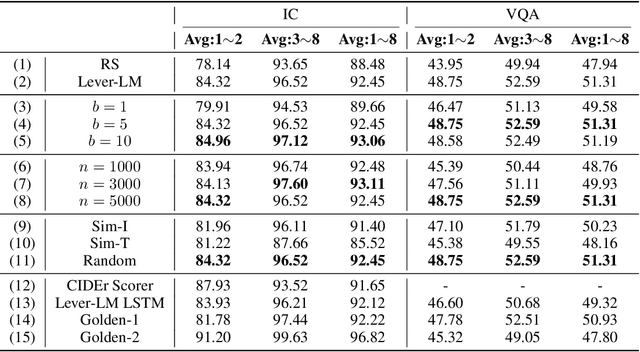
This paper studies how to configure powerful In-Context Demonstration (ICD) sequences for a Large Vision-Language Model (LVLM) to solve Vision-Language tasks through In-Context Learning (ICL). After observing that configuring an ICD sequence is a mirror process of composing a sentence, i.e., just as a sentence can be composed word by word via a Language Model, an ICD sequence can also be configured one by one. Consequently, we introduce an ICD Language Model (ICD-LM) specifically designed to generate effective ICD sequences. This involves creating a dataset of hand-crafted ICD sequences for various query samples and using it to train the ICD-LM. Our approach, diverging from traditional methods in NLP that select and order ICDs separately, enables to simultaneously learn how to select and order ICDs, enhancing the effect of the sequences. Moreover, during data construction, we use the LVLM intended for ICL implementation to validate the strength of each ICD sequence, resulting in a model-specific dataset and the ICD-LM trained by this dataset is also model-specific. We validate our methodology through experiments in Visual Question Answering and Image Captioning, confirming the viability of using a Language Model for ICD configuration. Our comprehensive ablation studies further explore the impact of various dataset construction and ICD-LM development settings on the outcomes. The code is given in https://github.com/ForJadeForest/ICD-LM.