 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStableI2I: Spotting Unintended Changes in Image-to-Image Transition
May 06, 2026In most real-world image-to-image (I2I) scenarios, existing evaluations primarily focus on instruction following and the perceptual quality or aesthetics of the generated images. However, they largely fail to assess whether the output image preserves the semantic correspondence and spatial structure of the input image. To address this limitation, we propose StableI2I, a unified and dynamic evaluation framework that explicitly measures content fidelity and pre--post consistency across a wide range of I2I tasks without requiring reference images, including image editing and image restoration. In addition, we construct StableI2I-Bench, a benchmark designed to systematically evaluate the accuracy of MLLMs on such fidelity and consistency assessment tasks. Extensive experimental results demonstrate that StableI2I provides accurate, fine-grained, and interpretable evaluations of content fidelity and consistency, with strong correlations to human subjective judgments. Our framework serves as a practical and reliable evaluation tool for diagnosing content consistency and benchmarking model performance in real-world I2I systems.
Accelerating Masked Image Generation by Learning Latent Controlled Dynamics
Feb 27, 2026Masked Image Generation Models (MIGMs) have achieved great success, yet their efficiency is hampered by the multiple steps of bi-directional attention. In fact, there exists notable redundancy in their computation: when sampling discrete tokens, the rich semantics contained in the continuous features are lost. Some existing works attempt to cache the features to approximate future features. However, they exhibit considerable approximation error under aggressive acceleration rates. We attribute this to their limited expressivity and the failure to account for sampling information. To fill this gap, we propose to learn a lightweight model that incorporates both previous features and sampled tokens, and regresses the average velocity field of feature evolution. The model has moderate complexity that suffices to capture the subtle dynamics while keeping lightweight compared to the original base model. We apply our method, MIGM-Shortcut, to two representative MIGM architectures and tasks. In particular, on the state-of-the-art Lumina-DiMOO, it achieves over 4x acceleration of text-to-image generation while maintaining quality, significantly pushing the Pareto frontier of masked image generation. The code and model weights are available at https://github.com/Kaiwen-Zhu/MIGM-Shortcut.
UniPercept: Towards Unified Perceptual-Level Image Understanding across Aesthetics, Quality, Structure, and Texture
Dec 25, 2025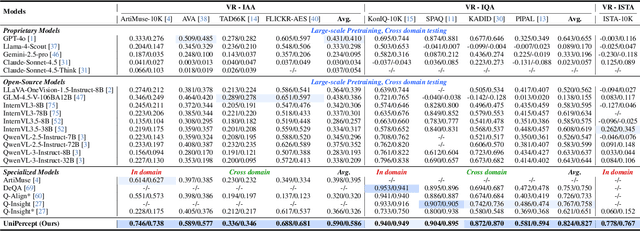

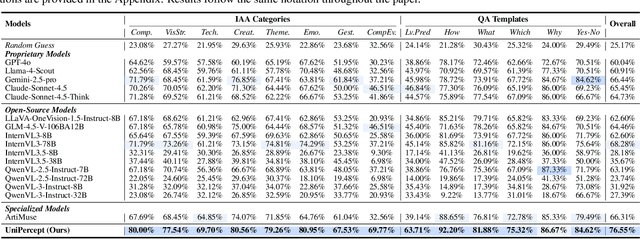
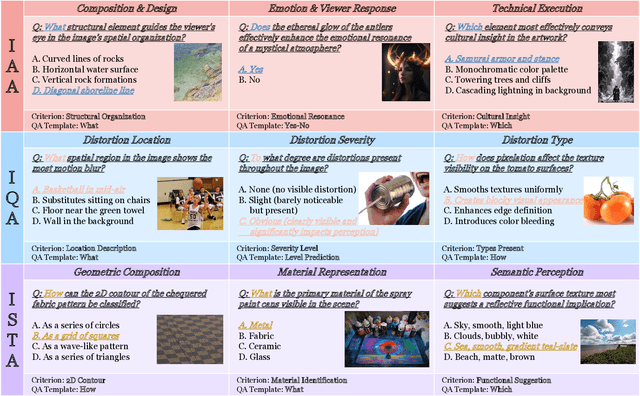
Multimodal large language models (MLLMs) have achieved remarkable progress in visual understanding tasks such as visual grounding, segmentation, and captioning. However, their ability to perceive perceptual-level image features remains limited. In this work, we present UniPercept-Bench, a unified framework for perceptual-level image understanding across three key domains: Aesthetics, Quality, Structure and Texture. We establish a hierarchical definition system and construct large-scale datasets to evaluate perceptual-level image understanding. Based on this foundation, we develop a strong baseline UniPercept trained via Domain-Adaptive Pre-Training and Task-Aligned RL, enabling robust generalization across both Visual Rating (VR) and Visual Question Answering (VQA) tasks. UniPercept outperforms existing MLLMs on perceptual-level image understanding and can serve as a plug-and-play reward model for text-to-image generation. This work defines Perceptual-Level Image Understanding in the era of MLLMs and, through the introduction of a comprehensive benchmark together with a strong baseline, provides a solid foundation for advancing perceptual-level multimodal image understanding.
dMLLM-TTS: Self-Verified and Efficient Test-Time Scaling for Diffusion Multi-Modal Large Language Models
Dec 22, 2025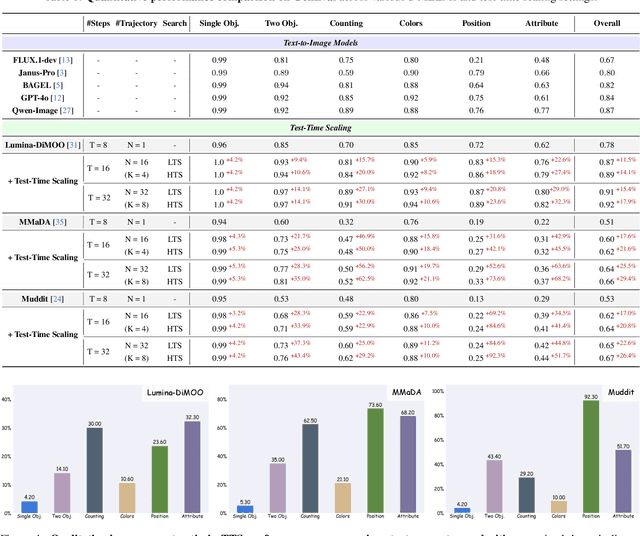

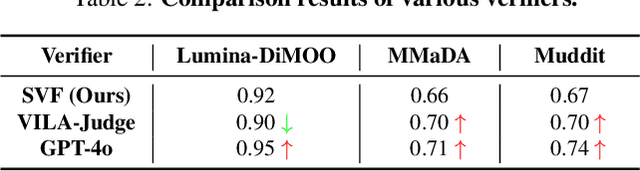
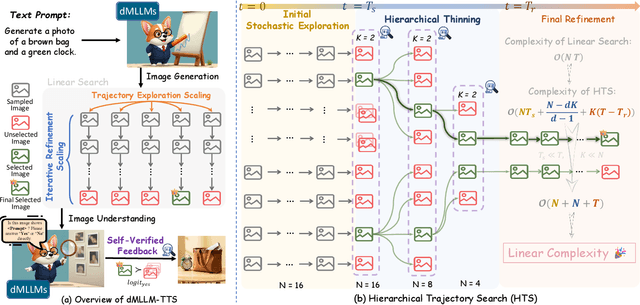
Diffusion Multi-modal Large Language Models (dMLLMs) have recently emerged as a novel architecture unifying image generation and understanding. However, developing effective and efficient Test-Time Scaling (TTS) methods to unlock their full generative potential remains an underexplored challenge. To address this, we propose dMLLM-TTS, a novel framework operating on two complementary scaling axes: (1) trajectory exploration scaling to enhance the diversity of generated hypotheses, and (2) iterative refinement scaling for stable generation. Conventional TTS approaches typically perform linear search across these two dimensions, incurring substantial computational costs of O(NT) and requiring an external verifier for best-of-N selection. To overcome these limitations, we propose two innovations. First, we design an efficient hierarchical search algorithm with O(N+T) complexity that adaptively expands and prunes sampling trajectories. Second, we introduce a self-verified feedback mechanism that leverages the dMLLMs' intrinsic image understanding capabilities to assess text-image alignment, eliminating the need for external verifier. Extensive experiments on the GenEval benchmark across three representative dMLLMs (e.g., Lumina-DiMOO, MMaDA, Muddit) show that our framework substantially improves generation quality while achieving up to 6x greater efficiency than linear search. Project page: https://github.com/Alpha-VLLM/Lumina-DiMOO.
Lumina-OmniLV: A Unified Multimodal Framework for General Low-Level Vision
Apr 08, 2025We present Lunima-OmniLV (abbreviated as OmniLV), a universal multimodal multi-task framework for low-level vision that addresses over 100 sub-tasks across four major categories: image restoration, image enhancement, weak-semantic dense prediction, and stylization. OmniLV leverages both textual and visual prompts to offer flexible and user-friendly interactions. Built on Diffusion Transformer (DiT)-based generative priors, our framework supports arbitrary resolutions -- achieving optimal performance at 1K resolution -- while preserving fine-grained details and high fidelity. Through extensive experiments, we demonstrate that separately encoding text and visual instructions, combined with co-training using shallow feature control, is essential to mitigate task ambiguity and enhance multi-task generalization. Our findings also reveal that integrating high-level generative tasks into low-level vision models can compromise detail-sensitive restoration. These insights pave the way for more robust and generalizable low-level vision systems.
Revisiting the Generalization Problem of Low-level Vision Models Through the Lens of Image Deraining
Feb 18, 2025Generalization remains a significant challenge for low-level vision models, which often struggle with unseen degradations in real-world scenarios despite their success in controlled benchmarks. In this paper, we revisit the generalization problem in low-level vision models. Image deraining is selected as a case study due to its well-defined and easily decoupled structure, allowing for more effective observation and analysis. Through comprehensive experiments, we reveal that the generalization issue is not primarily due to limited network capacity but rather the failure of existing training strategies, which leads networks to overfit specific degradation patterns. Our findings show that guiding networks to focus on learning the underlying image content, rather than the degradation patterns, is key to improving generalization. We demonstrate that balancing the complexity of background images and degradations in the training data helps networks better fit the image distribution. Furthermore, incorporating content priors from pre-trained generative models significantly enhances generalization. Experiments on both image deraining and image denoising validate the proposed strategies. We believe the insights and solutions will inspire further research and improve the generalization of low-level vision models.
An Intelligent Agentic System for Complex Image Restoration Problems
Oct 23, 2024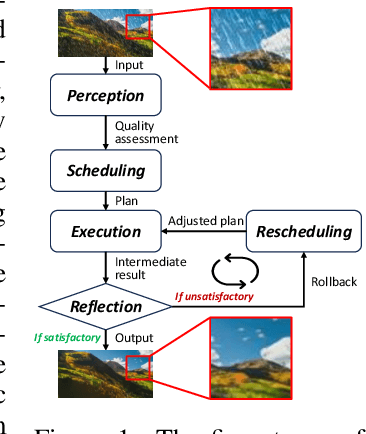

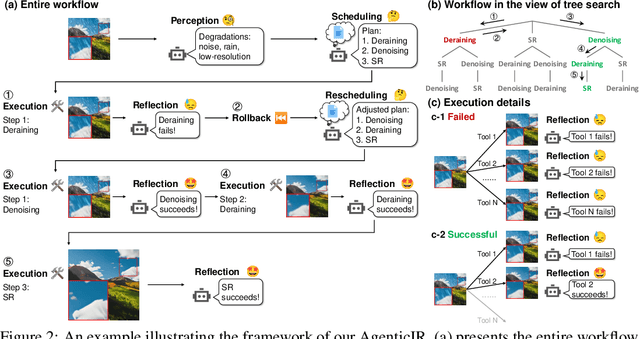
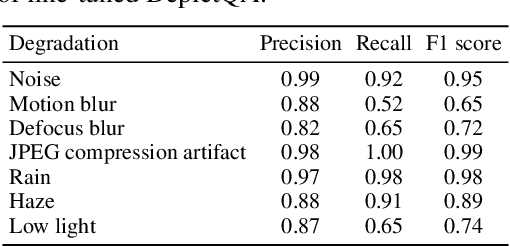
Real-world image restoration (IR) is inherently complex and often requires combining multiple specialized models to address diverse degradations. Inspired by human problem-solving, we propose AgenticIR, an agentic system that mimics the human approach to image processing by following five key stages: Perception, Scheduling, Execution, Reflection, and Rescheduling. AgenticIR leverages large language models (LLMs) and vision-language models (VLMs) that interact via text generation to dynamically operate a toolbox of IR models. We fine-tune VLMs for image quality analysis and employ LLMs for reasoning, guiding the system step by step. To compensate for LLMs' lack of specific IR knowledge and experience, we introduce a self-exploration method, allowing the LLM to observe and summarize restoration results into referenceable documents. Experiments demonstrate AgenticIR's potential in handling complex IR tasks, representing a promising path toward achieving general intelligence in visual processing.
Descriptive Image Quality Assessment in the Wild
May 29, 2024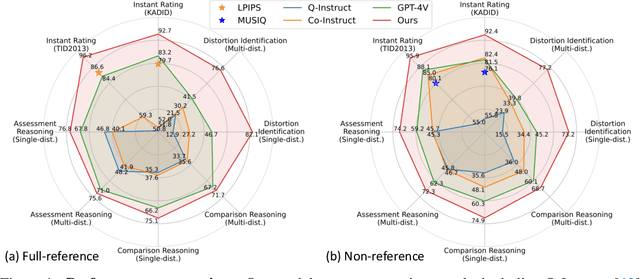

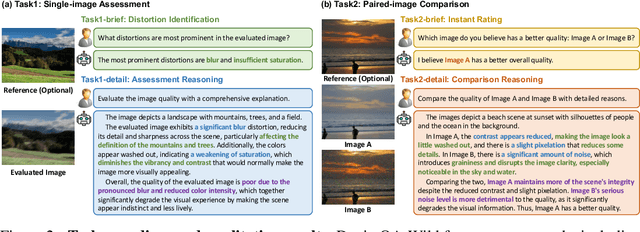
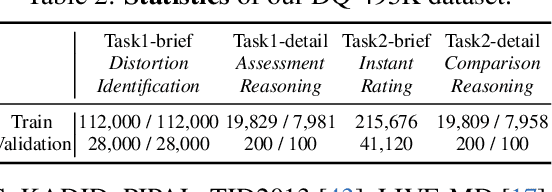
With the rapid advancement of Vision Language Models (VLMs), VLM-based Image Quality Assessment (IQA) seeks to describe image quality linguistically to align with human expression and capture the multifaceted nature of IQA tasks. However, current methods are still far from practical usage. First, prior works focus narrowly on specific sub-tasks or settings, which do not align with diverse real-world applications. Second, their performance is sub-optimal due to limitations in dataset coverage, scale, and quality. To overcome these challenges, we introduce Depicted image Quality Assessment in the Wild (DepictQA-Wild). Our method includes a multi-functional IQA task paradigm that encompasses both assessment and comparison tasks, brief and detailed responses, full-reference and non-reference scenarios. We introduce a ground-truth-informed dataset construction approach to enhance data quality, and scale up the dataset to 495K under the brief-detail joint framework. Consequently, we construct a comprehensive, large-scale, and high-quality dataset, named DQ-495K. We also retain image resolution during training to better handle resolution-related quality issues, and estimate a confidence score that is helpful to filter out low-quality responses. Experimental results demonstrate that DepictQA-Wild significantly outperforms traditional score-based methods, prior VLM-based IQA models, and proprietary GPT-4V in distortion identification, instant rating, and reasoning tasks. Our advantages are further confirmed by real-world applications including assessing the web-downloaded images and ranking model-processed images. Datasets and codes will be released in https://depictqa.github.io/depictqa-wild/.
Reaching Consensus in Cooperative Multi-Agent Reinforcement Learning with Goal Imagination
Mar 05, 2024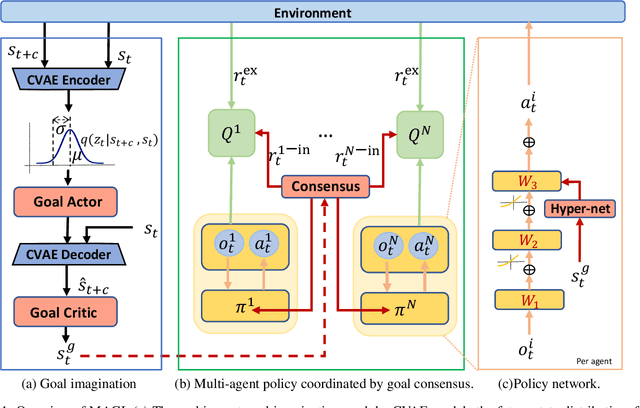
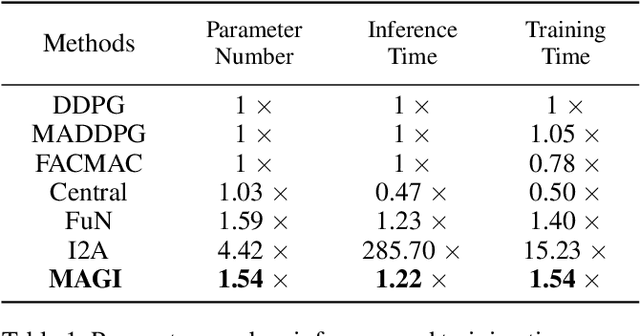
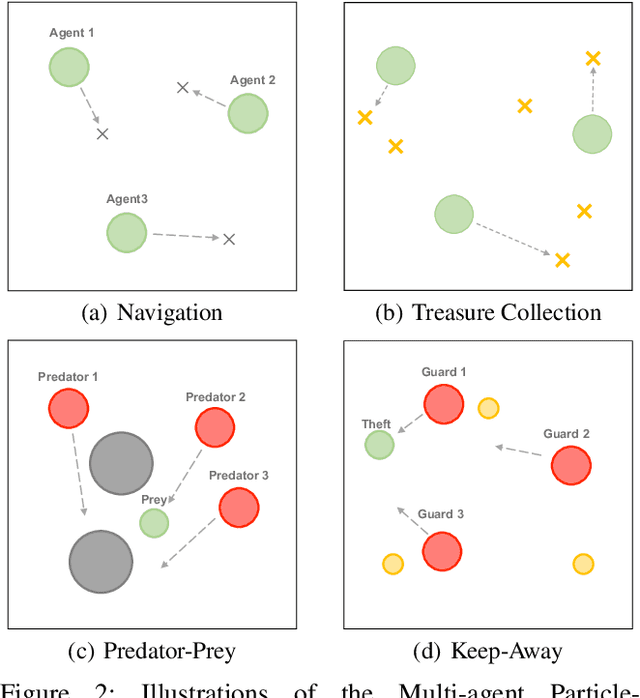

Reaching consensus is key to multi-agent coordination. To accomplish a cooperative task, agents need to coherently select optimal joint actions to maximize the team reward. However, current cooperative multi-agent reinforcement learning (MARL) methods usually do not explicitly take consensus into consideration, which may cause miscoordination problem. In this paper, we propose a model-based consensus mechanism to explicitly coordinate multiple agents. The proposed Multi-agent Goal Imagination (MAGI) framework guides agents to reach consensus with an Imagined common goal. The common goal is an achievable state with high value, which is obtained by sampling from the distribution of future states. We directly model this distribution with a self-supervised generative model, thus alleviating the "curse of dimensinality" problem induced by multi-agent multi-step policy rollout commonly used in model-based methods. We show that such efficient consensus mechanism can guide all agents cooperatively reaching valuable future states. Results on Multi-agent Particle-Environments and Google Research Football environment demonstrate the superiority of MAGI in both sample efficiency and performance.