 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReaching Consensus in Cooperative Multi-Agent Reinforcement Learning with Goal Imagination
Mar 05, 2024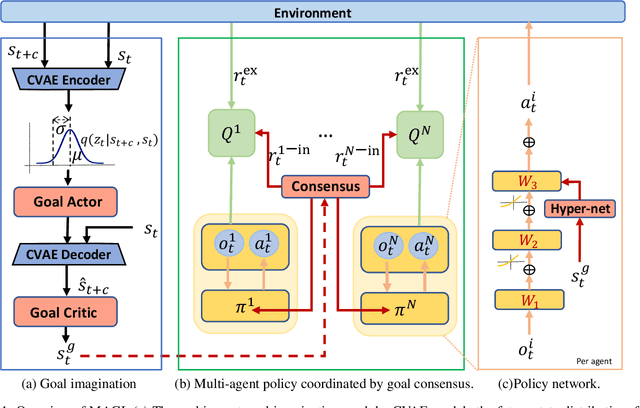
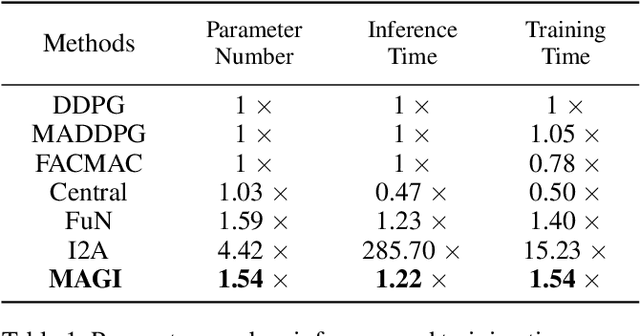
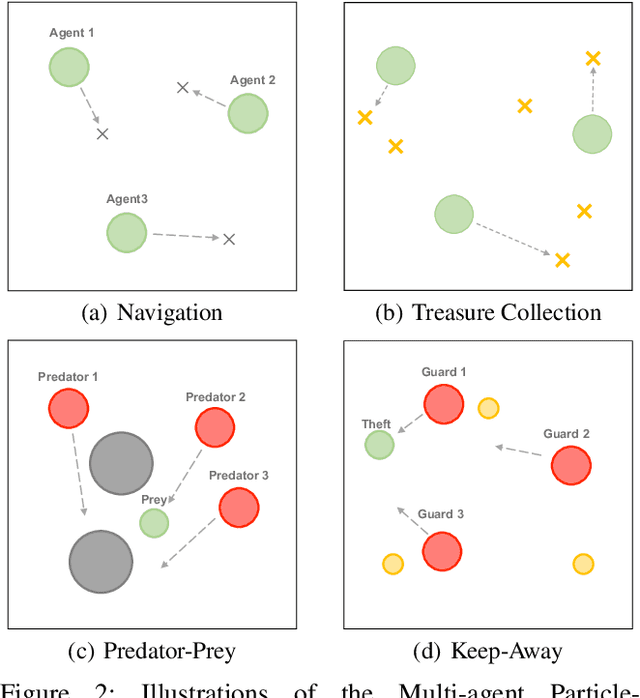

Reaching consensus is key to multi-agent coordination. To accomplish a cooperative task, agents need to coherently select optimal joint actions to maximize the team reward. However, current cooperative multi-agent reinforcement learning (MARL) methods usually do not explicitly take consensus into consideration, which may cause miscoordination problem. In this paper, we propose a model-based consensus mechanism to explicitly coordinate multiple agents. The proposed Multi-agent Goal Imagination (MAGI) framework guides agents to reach consensus with an Imagined common goal. The common goal is an achievable state with high value, which is obtained by sampling from the distribution of future states. We directly model this distribution with a self-supervised generative model, thus alleviating the "curse of dimensinality" problem induced by multi-agent multi-step policy rollout commonly used in model-based methods. We show that such efficient consensus mechanism can guide all agents cooperatively reaching valuable future states. Results on Multi-agent Particle-Environments and Google Research Football environment demonstrate the superiority of MAGI in both sample efficiency and performance.
SMIX($λ$): Enhancing Centralized Value Functions for Cooperative Multi-Agent Reinforcement Learning
Nov 18, 2019
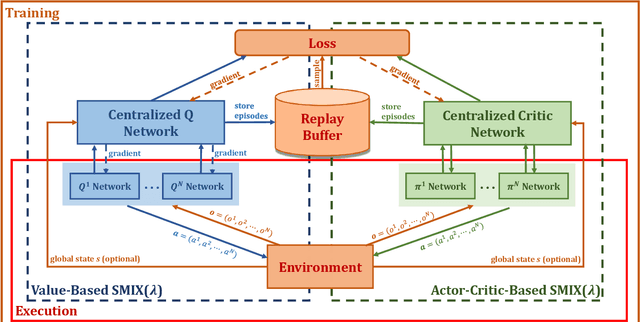

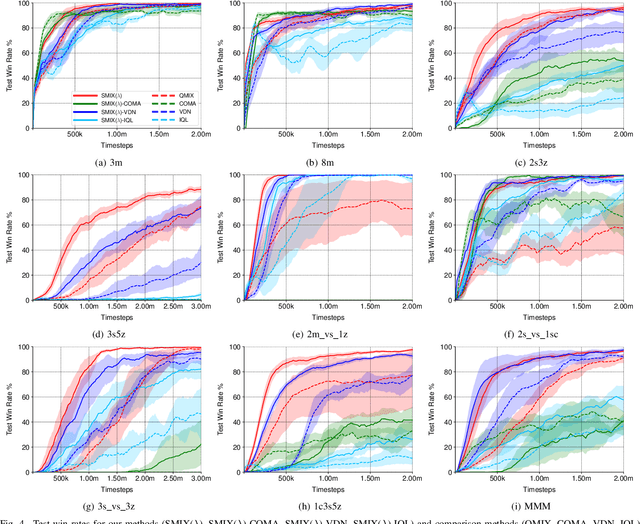
Learning a stable and generalizable centralized value function (CVF) is a crucial but challenging task in multi-agent reinforcement learning (MARL), as it has to deal with the issue that the joint action space increases exponentially with the number of agents in such scenarios. This paper proposes an approach, named SMIX(${\lambda}$), that uses an off-policy training to achieve this by avoiding the greedy assumption commonly made in CVF learning. As importance sampling for such off-policy training is both computationally costly and numerically unstable, we proposed to use the ${\lambda}$-return as a proxy to compute the TD error. With this new loss function objective, we adopt a modified QMIX network structure as the base to train our model. By further connecting it with the ${Q(\lambda)}$ approach from an unified expectation correction viewpoint, we show that the proposed SMIX(${\lambda}$) is equivalent to ${Q(\lambda)}$ and hence shares its convergence properties, while without being suffered from the aforementioned curse of dimensionality problem inherent in MARL. Experiments on the StarCraft Multi-Agent Challenge (SMAC) benchmark demonstrate that our approach not only outperforms several state-of-the-art MARL methods by a large margin, but also can be used as a general tool to improve the overall performance of other CTDE-type algorithms by enhancing their CVFs.