 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Desensitization Learning for Cross Domain Face Forgery Detection
May 27, 2025In this paper, we propose a new cross-domain face forgery detection method that is insensitive to different and possibly unseen forgery methods while ensuring an acceptable low false positive rate. Although existing face forgery detection methods are applicable to multiple domains to some degree, they often come with a high false positive rate, which can greatly disrupt the usability of the system. To address this issue, we propose an Contrastive Desensitization Network (CDN) based on a robust desensitization algorithm, which captures the essential domain characteristics through learning them from domain transformation over pairs of genuine face images. One advantage of CDN lies in that the learnt face representation is theoretical justified with regard to the its robustness against the domain changes. Extensive experiments over large-scale benchmark datasets demonstrate that our method achieves a much lower false alarm rate with improved detection accuracy compared to several state-of-the-art methods.
RoGA: Towards Generalizable Deepfake Detection through Robust Gradient Alignment
May 27, 2025Recent advancements in domain generalization for deepfake detection have attracted significant attention, with previous methods often incorporating additional modules to prevent overfitting to domain-specific patterns. However, such regularization can hinder the optimization of the empirical risk minimization (ERM) objective, ultimately degrading model performance. In this paper, we propose a novel learning objective that aligns generalization gradient updates with ERM gradient updates. The key innovation is the application of perturbations to model parameters, aligning the ascending points across domains, which specifically enhances the robustness of deepfake detection models to domain shifts. This approach effectively preserves domain-invariant features while managing domain-specific characteristics, without introducing additional regularization. Experimental results on multiple challenging deepfake detection datasets demonstrate that our gradient alignment strategy outperforms state-of-the-art domain generalization techniques, confirming the efficacy of our method. The code is available at https://github.com/Lynn0925/RoGA.
Variational OOD State Correction for Offline Reinforcement Learning
May 01, 2025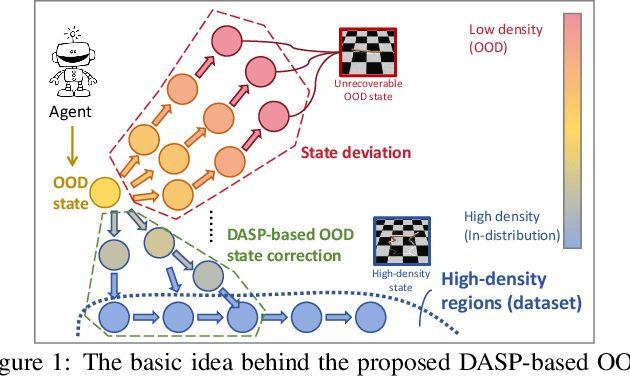
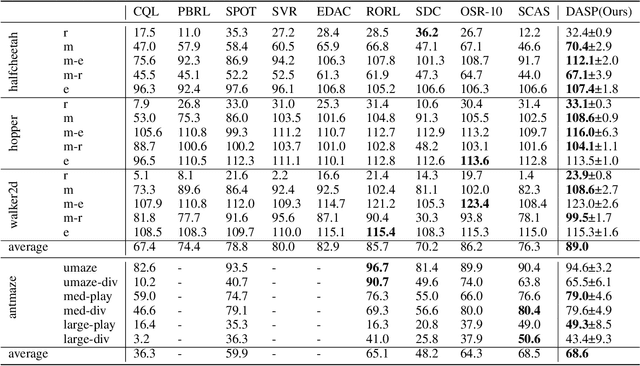
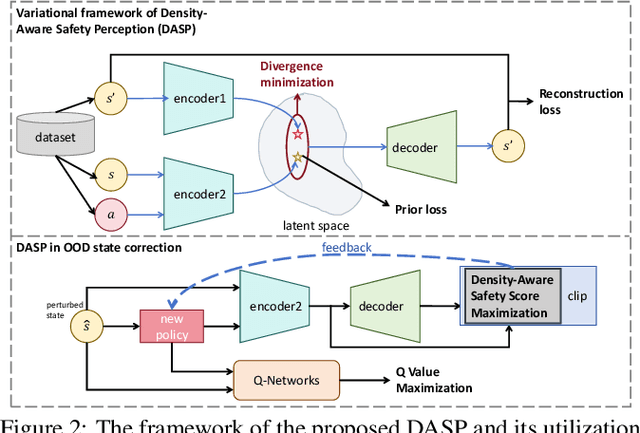
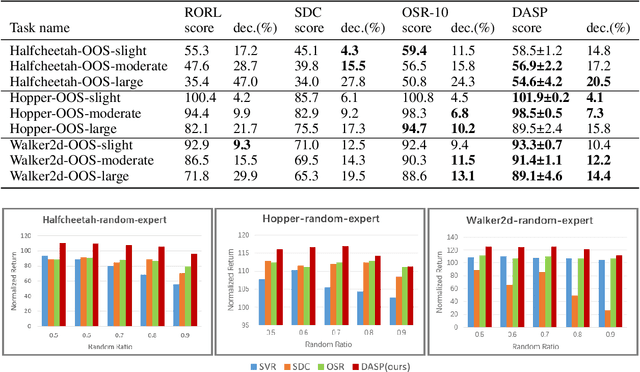
The performance of Offline reinforcement learning is significantly impacted by the issue of state distributional shift, and out-of-distribution (OOD) state correction is a popular approach to address this problem. In this paper, we propose a novel method named Density-Aware Safety Perception (DASP) for OOD state correction. Specifically, our method encourages the agent to prioritize actions that lead to outcomes with higher data density, thereby promoting its operation within or the return to in-distribution (safe) regions. To achieve this, we optimize the objective within a variational framework that concurrently considers both the potential outcomes of decision-making and their density, thus providing crucial contextual information for safe decision-making. Finally, we validate the effectiveness and feasibility of our proposed method through extensive experimental evaluations on the offline MuJoCo and AntMaze suites.
Beyond Non-Expert Demonstrations: Outcome-Driven Action Constraint for Offline Reinforcement Learning
Apr 03, 2025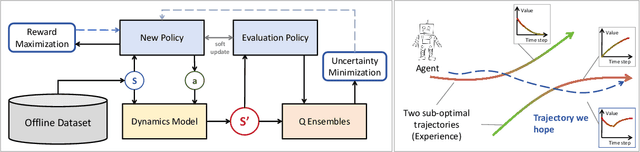
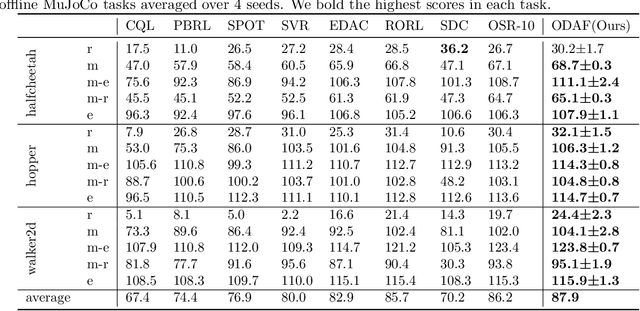
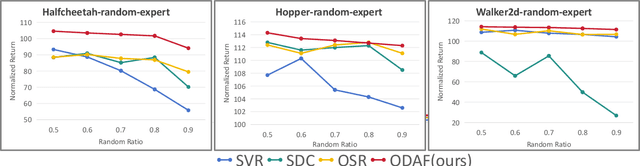
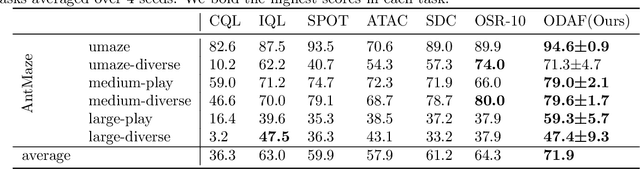
We address the challenge of offline reinforcement learning using realistic data, specifically non-expert data collected through sub-optimal behavior policies. Under such circumstance, the learned policy must be safe enough to manage distribution shift while maintaining sufficient flexibility to deal with non-expert (bad) demonstrations from offline data.To tackle this issue, we introduce a novel method called Outcome-Driven Action Flexibility (ODAF), which seeks to reduce reliance on the empirical action distribution of the behavior policy, hence reducing the negative impact of those bad demonstrations.To be specific, a new conservative reward mechanism is developed to deal with distribution shift by evaluating actions according to whether their outcomes meet safety requirements - remaining within the state support area, rather than solely depending on the actions' likelihood based on offline data.Besides theoretical justification, we provide empirical evidence on widely used MuJoCo and various maze benchmarks, demonstrating that our ODAF method, implemented using uncertainty quantification techniques, effectively tolerates unseen transitions for improved "trajectory stitching," while enhancing the agent's ability to learn from realistic non-expert data.
Transductive Off-policy Proximal Policy Optimization
Jun 06, 2024



Proximal Policy Optimization (PPO) is a popular model-free reinforcement learning algorithm, esteemed for its simplicity and efficacy. However, due to its inherent on-policy nature, its proficiency in harnessing data from disparate policies is constrained. This paper introduces a novel off-policy extension to the original PPO method, christened Transductive Off-policy PPO (ToPPO). Herein, we provide theoretical justification for incorporating off-policy data in PPO training and prudent guidelines for its safe application. Our contribution includes a novel formulation of the policy improvement lower bound for prospective policies derived from off-policy data, accompanied by a computationally efficient mechanism to optimize this bound, underpinned by assurances of monotonic improvement. Comprehensive experimental results across six representative tasks underscore ToPPO's promising performance.
Highway Reinforcement Learning
May 28, 2024



Learning from multi-step off-policy data collected by a set of policies is a core problem of reinforcement learning (RL). Approaches based on importance sampling (IS) often suffer from large variances due to products of IS ratios. Typical IS-free methods, such as $n$-step Q-learning, look ahead for $n$ time steps along the trajectory of actions (where $n$ is called the lookahead depth) and utilize off-policy data directly without any additional adjustment. They work well for proper choices of $n$. We show, however, that such IS-free methods underestimate the optimal value function (VF), especially for large $n$, restricting their capacity to efficiently utilize information from distant future time steps. To overcome this problem, we introduce a novel, IS-free, multi-step off-policy method that avoids the underestimation issue and converges to the optimal VF. At its core lies a simple but non-trivial \emph{highway gate}, which controls the information flow from the distant future by comparing it to a threshold. The highway gate guarantees convergence to the optimal VF for arbitrary $n$ and arbitrary behavioral policies. It gives rise to a novel family of off-policy RL algorithms that safely learn even when $n$ is very large, facilitating rapid credit assignment from the far future to the past. On tasks with greatly delayed rewards, including video games where the reward is given only at the end of the game, our new methods outperform many existing multi-step off-policy algorithms.
HiQA: A Hierarchical Contextual Augmentation RAG for Massive Documents QA
Feb 01, 2024
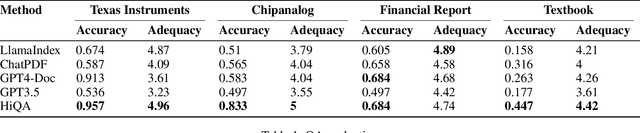
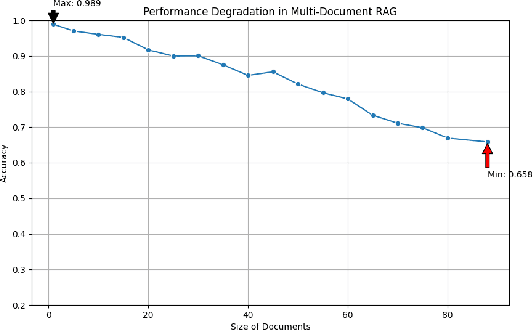
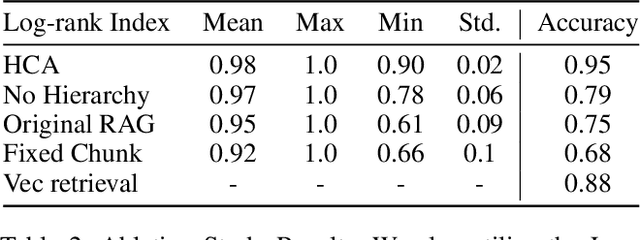
As language model agents leveraging external tools rapidly evolve, significant progress has been made in question-answering(QA) methodologies utilizing supplementary documents and the Retrieval-Augmented Generation (RAG) approach. This advancement has improved the response quality of language models and alleviates the appearance of hallucination. However, these methods exhibit limited retrieval accuracy when faced with massive indistinguishable documents, presenting notable challenges in their practical application. In response to these emerging challenges, we present HiQA, an advanced framework for multi-document question-answering (MDQA) that integrates cascading metadata into content as well as a multi-route retrieval mechanism. We also release a benchmark called MasQA to evaluate and research in MDQA. Finally, HiQA demonstrates the state-of-the-art performance in multi-document environments.
ProxyFormer: Proxy Alignment Assisted Point Cloud Completion with Missing Part Sensitive Transformer
Feb 28, 2023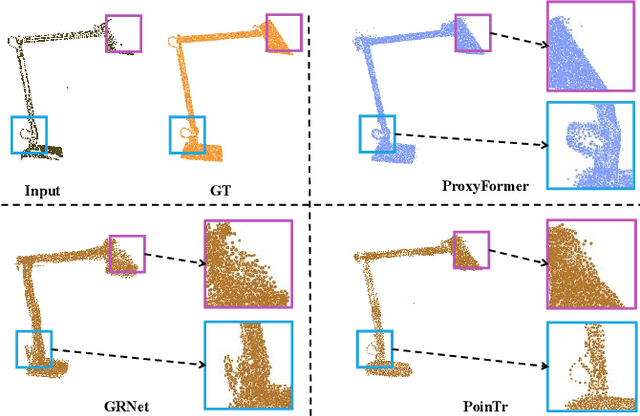



Problems such as equipment defects or limited viewpoints will lead the captured point clouds to be incomplete. Therefore, recovering the complete point clouds from the partial ones plays an vital role in many practical tasks, and one of the keys lies in the prediction of the missing part. In this paper, we propose a novel point cloud completion approach namely ProxyFormer that divides point clouds into existing (input) and missing (to be predicted) parts and each part communicates information through its proxies. Specifically, we fuse information into point proxy via feature and position extractor, and generate features for missing point proxies from the features of existing point proxies. Then, in order to better perceive the position of missing points, we design a missing part sensitive transformer, which converts random normal distribution into reasonable position information, and uses proxy alignment to refine the missing proxies. It makes the predicted point proxies more sensitive to the features and positions of the missing part, and thus make these proxies more suitable for subsequent coarse-to-fine processes. Experimental results show that our method outperforms state-of-the-art completion networks on several benchmark datasets and has the fastest inference speed. Code is available at https://github.com/I2-Multimedia-Lab/ProxyFormer.
Contextual Conservative Q-Learning for Offline Reinforcement Learning
Jan 16, 2023Offline reinforcement learning learns an effective policy on offline datasets without online interaction, and it attracts persistent research attention due to its potential of practical application. However, extrapolation error generated by distribution shift will still lead to the overestimation for those actions that transit to out-of-distribution(OOD) states, which degrades the reliability and robustness of the offline policy. In this paper, we propose Contextual Conservative Q-Learning(C-CQL) to learn a robustly reliable policy through the contextual information captured via an inverse dynamics model. With the supervision of the inverse dynamics model, it tends to learn a policy that generates stable transition at perturbed states, for the fact that pertuebed states are a common kind of OOD states. In this manner, we enable the learnt policy more likely to generate transition that destines to the empirical next state distributions of the offline dataset, i.e., robustly reliable transition. Besides, we theoretically reveal that C-CQL is the generalization of the Conservative Q-Learning(CQL) and aggressive State Deviation Correction(SDC). Finally, experimental results demonstrate the proposed C-CQL achieves the state-of-the-art performance in most environments of offline Mujoco suite and a noisy Mujoco setting.
Smoothing Advantage Learning
Mar 20, 2022



Advantage learning (AL) aims to improve the robustness of value-based reinforcement learning against estimation errors with action-gap-based regularization. Unfortunately, the method tends to be unstable in the case of function approximation. In this paper, we propose a simple variant of AL, named smoothing advantage learning (SAL), to alleviate this problem. The key to our method is to replace the original Bellman Optimal operator in AL with a smooth one so as to obtain more reliable estimation of the temporal difference target. We give a detailed account of the resulting action gap and the performance bound for approximate SAL. Further theoretical analysis reveals that the proposed value smoothing technique not only helps to stabilize the training procedure of AL by controlling the trade-off between convergence rate and the upper bound of the approximation errors, but is beneficial to increase the action gap between the optimal and sub-optimal action value as well.