 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Desensitization Learning for Cross Domain Face Forgery Detection
May 27, 2025In this paper, we propose a new cross-domain face forgery detection method that is insensitive to different and possibly unseen forgery methods while ensuring an acceptable low false positive rate. Although existing face forgery detection methods are applicable to multiple domains to some degree, they often come with a high false positive rate, which can greatly disrupt the usability of the system. To address this issue, we propose an Contrastive Desensitization Network (CDN) based on a robust desensitization algorithm, which captures the essential domain characteristics through learning them from domain transformation over pairs of genuine face images. One advantage of CDN lies in that the learnt face representation is theoretical justified with regard to the its robustness against the domain changes. Extensive experiments over large-scale benchmark datasets demonstrate that our method achieves a much lower false alarm rate with improved detection accuracy compared to several state-of-the-art methods.
RoGA: Towards Generalizable Deepfake Detection through Robust Gradient Alignment
May 27, 2025Recent advancements in domain generalization for deepfake detection have attracted significant attention, with previous methods often incorporating additional modules to prevent overfitting to domain-specific patterns. However, such regularization can hinder the optimization of the empirical risk minimization (ERM) objective, ultimately degrading model performance. In this paper, we propose a novel learning objective that aligns generalization gradient updates with ERM gradient updates. The key innovation is the application of perturbations to model parameters, aligning the ascending points across domains, which specifically enhances the robustness of deepfake detection models to domain shifts. This approach effectively preserves domain-invariant features while managing domain-specific characteristics, without introducing additional regularization. Experimental results on multiple challenging deepfake detection datasets demonstrate that our gradient alignment strategy outperforms state-of-the-art domain generalization techniques, confirming the efficacy of our method. The code is available at https://github.com/Lynn0925/RoGA.
Variational OOD State Correction for Offline Reinforcement Learning
May 01, 2025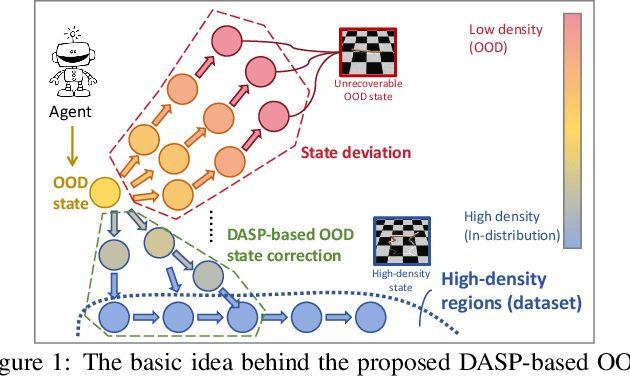
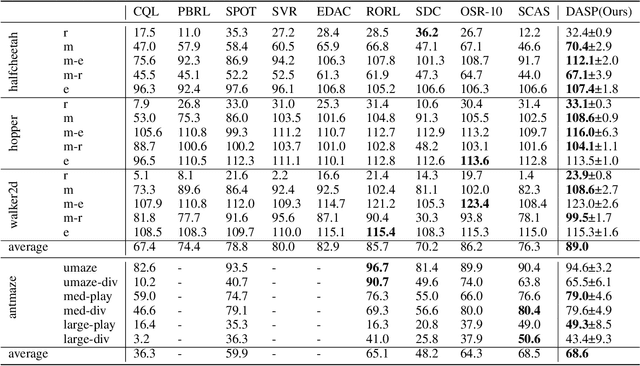
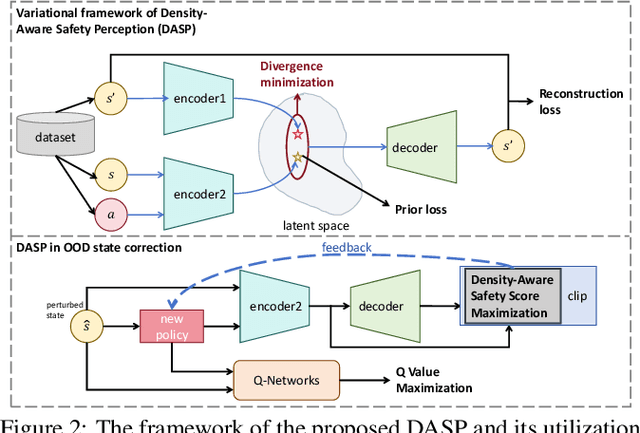
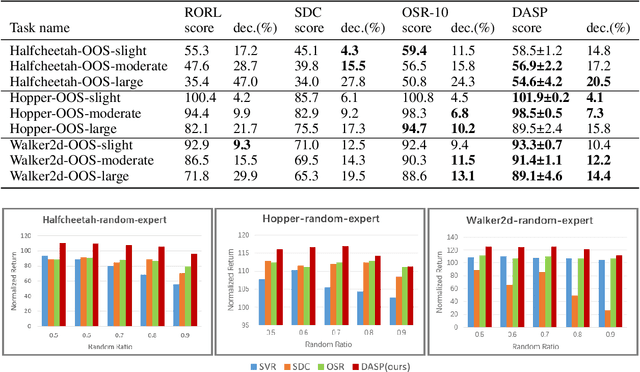
The performance of Offline reinforcement learning is significantly impacted by the issue of state distributional shift, and out-of-distribution (OOD) state correction is a popular approach to address this problem. In this paper, we propose a novel method named Density-Aware Safety Perception (DASP) for OOD state correction. Specifically, our method encourages the agent to prioritize actions that lead to outcomes with higher data density, thereby promoting its operation within or the return to in-distribution (safe) regions. To achieve this, we optimize the objective within a variational framework that concurrently considers both the potential outcomes of decision-making and their density, thus providing crucial contextual information for safe decision-making. Finally, we validate the effectiveness and feasibility of our proposed method through extensive experimental evaluations on the offline MuJoCo and AntMaze suites.
Beyond Non-Expert Demonstrations: Outcome-Driven Action Constraint for Offline Reinforcement Learning
Apr 03, 2025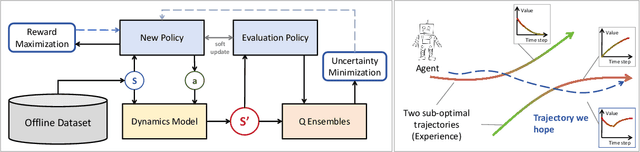
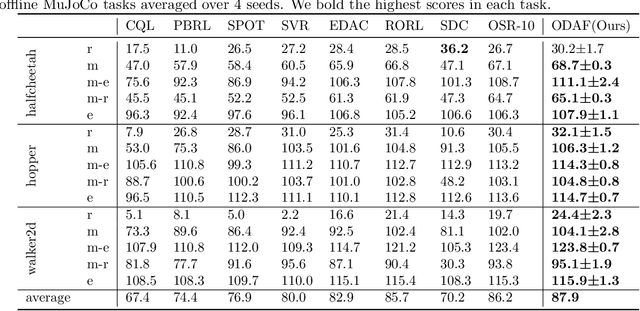
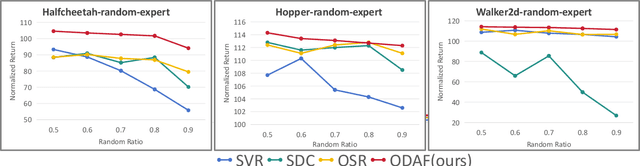
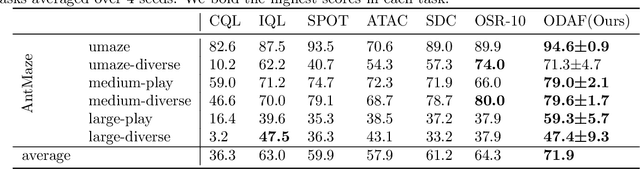
We address the challenge of offline reinforcement learning using realistic data, specifically non-expert data collected through sub-optimal behavior policies. Under such circumstance, the learned policy must be safe enough to manage distribution shift while maintaining sufficient flexibility to deal with non-expert (bad) demonstrations from offline data.To tackle this issue, we introduce a novel method called Outcome-Driven Action Flexibility (ODAF), which seeks to reduce reliance on the empirical action distribution of the behavior policy, hence reducing the negative impact of those bad demonstrations.To be specific, a new conservative reward mechanism is developed to deal with distribution shift by evaluating actions according to whether their outcomes meet safety requirements - remaining within the state support area, rather than solely depending on the actions' likelihood based on offline data.Besides theoretical justification, we provide empirical evidence on widely used MuJoCo and various maze benchmarks, demonstrating that our ODAF method, implemented using uncertainty quantification techniques, effectively tolerates unseen transitions for improved "trajectory stitching," while enhancing the agent's ability to learn from realistic non-expert data.
Magnet: Multi-turn Tool-use Data Synthesis and Distillation via Graph Translation
Mar 10, 2025



Large language models (LLMs) have exhibited the ability to effectively utilize external tools to address user queries. However, their performance may be limited in complex, multi-turn interactions involving users and multiple tools. To address this, we propose Magnet, a principled framework for synthesizing high-quality training trajectories to enhance the function calling capability of large language model agents in multi-turn conversations with humans. The framework is based on automatic and iterative translations from a function signature path to a sequence of queries and executable function calls. We model the complicated function interactions in multi-turn cases with graph and design novel node operations to build reliable signature paths. Motivated by context distillation, when guiding the generation of positive and negative trajectories using a teacher model, we provide reference function call sequences as positive hints in context and contrastive, incorrect function calls as negative hints. Experiments show that training with the positive trajectories with supervised fine-tuning and preference optimization against negative trajectories, our 14B model, Magnet-14B-mDPO, obtains 68.01 on BFCL-v3 and 73.30 on ToolQuery, surpassing the performance of the teacher model Gemini-1.5-pro-002 by a large margin in function calling.
Preliminary Investigation into Data Scaling Laws for Imitation Learning-Based End-to-End Autonomous Driving
Dec 03, 2024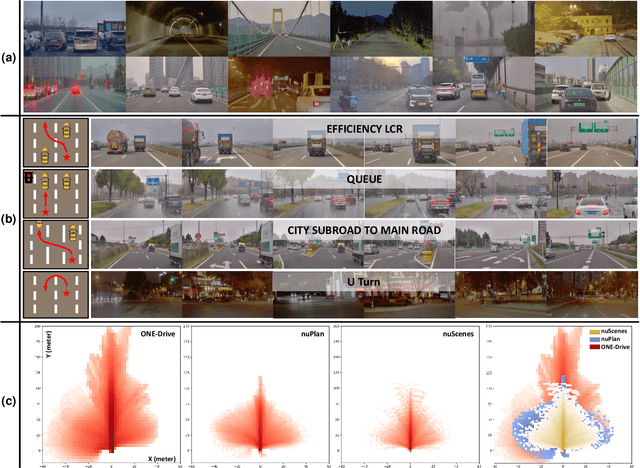
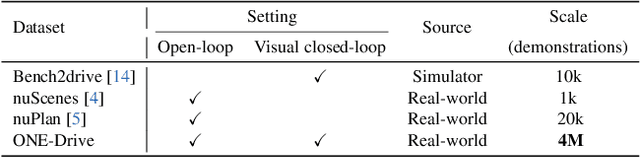

The end-to-end autonomous driving paradigm has recently attracted lots of attention due to its scalability. However, existing methods are constrained by the limited scale of real-world data, which hinders a comprehensive exploration of the scaling laws associated with end-to-end autonomous driving. To address this issue, we collected substantial data from various driving scenarios and behaviors and conducted an extensive study on the scaling laws of existing imitation learning-based end-to-end autonomous driving paradigms. Specifically, approximately 4 million demonstrations from 23 different scenario types were gathered, amounting to over 30,000 hours of driving demonstrations. We performed open-loop evaluations and closed-loop simulation evaluations in 1,400 diverse driving demonstrations (1,300 for open-loop and 100 for closed-loop) under stringent assessment conditions. Through experimental analysis, we discovered that (1) the performance of the driving model exhibits a power-law relationship with the amount of training data; (2) a small increase in the quantity of long-tailed data can significantly improve the performance for the corresponding scenarios; (3) appropriate scaling of data enables the model to achieve combinatorial generalization in novel scenes and actions. Our results highlight the critical role of data scaling in improving the generalizability of models across diverse autonomous driving scenarios, assuring safe deployment in the real world. Project repository: https://github.com/ucaszyp/Driving-Scaling-Law
Contextual Conservative Q-Learning for Offline Reinforcement Learning
Jan 16, 2023Offline reinforcement learning learns an effective policy on offline datasets without online interaction, and it attracts persistent research attention due to its potential of practical application. However, extrapolation error generated by distribution shift will still lead to the overestimation for those actions that transit to out-of-distribution(OOD) states, which degrades the reliability and robustness of the offline policy. In this paper, we propose Contextual Conservative Q-Learning(C-CQL) to learn a robustly reliable policy through the contextual information captured via an inverse dynamics model. With the supervision of the inverse dynamics model, it tends to learn a policy that generates stable transition at perturbed states, for the fact that pertuebed states are a common kind of OOD states. In this manner, we enable the learnt policy more likely to generate transition that destines to the empirical next state distributions of the offline dataset, i.e., robustly reliable transition. Besides, we theoretically reveal that C-CQL is the generalization of the Conservative Q-Learning(CQL) and aggressive State Deviation Correction(SDC). Finally, experimental results demonstrate the proposed C-CQL achieves the state-of-the-art performance in most environments of offline Mujoco suite and a noisy Mujoco setting.
TriDoNet: A Triple Domain Model-driven Network for CT Metal Artifact Reduction
Nov 14, 2022



Recent deep learning-based methods have achieved promising performance for computed tomography metal artifact reduction (CTMAR). However, most of them suffer from two limitations: (i) the domain knowledge is not fully embedded into the network training; (ii) metal artifacts lack effective representation models. The aforementioned limitations leave room for further performance improvement. Against these issues, we propose a novel triple domain model-driven CTMAR network, termed as TriDoNet, whose network training exploits triple domain knowledge, i.e., the knowledge of the sinogram, CT image, and metal artifact domains. Specifically, to explore the non-local repetitive streaking patterns of metal artifacts, we encode them as an explicit tight frame sparse representation model with adaptive thresholds. Furthermore, we design a contrastive regularization (CR) built upon contrastive learning to exploit clean CT images and metal-affected images as positive and negative samples, respectively. Experimental results show that our TriDoNet can generate superior artifact-reduced CT images.
A Content-Based Approach to Email Triage Action Prediction: Exploration and Evaluation
Apr 30, 2019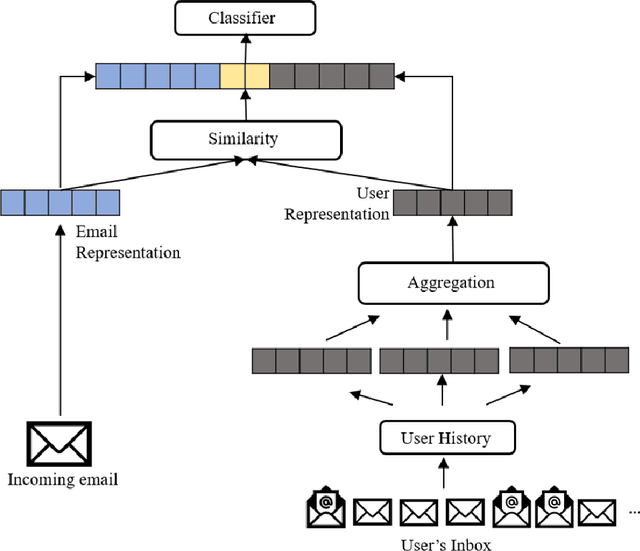

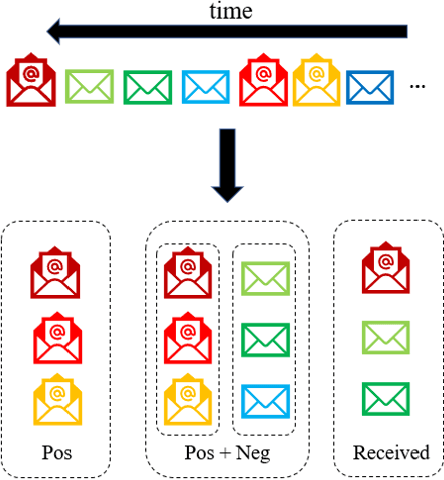

Email has remained a principal form of communication among people, both in enterprise and social settings. With a deluge of emails crowding our mailboxes daily, there is a dire need of smart email systems that can recover important emails and make personalized recommendations. In this work, we study the problem of predicting user triage actions to incoming emails where we take the reply prediction as a working example. Different from existing methods, we formulate the triage action prediction as a recommendation problem and focus on the content-based approach, where the users are represented using the content of current and past emails. We also introduce additional similarity features to further explore the affinities between users and emails. Experiments on the publicly available Avocado email collection demonstrate the advantages of our proposed recommendation framework and our method is able to achieve better performance compared to the state-of-the-art deep recommendation methods. More importantly, we provide valuable insight into the effectiveness of different textual and user representations and show that traditional bag-of-words approaches, with the help from the similarity features, compete favorably with the more advanced neural embedding methods.
Combinatorial Topic Models using Small-Variance Asymptotics
May 27, 2016



Topic models have emerged as fundamental tools in unsupervised machine learning. Most modern topic modeling algorithms take a probabilistic view and derive inference algorithms based on Latent Dirichlet Allocation (LDA) or its variants. In contrast, we study topic modeling as a combinatorial optimization problem, and propose a new objective function derived from LDA by passing to the small-variance limit. We minimize the derived objective by using ideas from combinatorial optimization, which results in a new, fast, and high-quality topic modeling algorithm. In particular, we show that our results are competitive with popular LDA-based topic modeling approaches, and also discuss the (dis)similarities between our approach and its probabilistic counterparts.