 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaithful, Enriched, and Precise: Benchmarking Natural-Science Illustration Generation by T2I models
Jun 04, 2026Scientific illustrations are essential tools for communicating research findings, especially in natural science, where they visualize complex concepts and processes. As Text-to-Image (T2I) models become increasingly capable, researchers have started to use them for scientific illustration generation. However, existing benchmarks often assess outputs at a holistic level, overlooking fine-grained elements, while scientific reasoning ability and output conciseness remain under-quantified. We introduce FEPBench, a benchmark built from carefully selected high-quality scientific illustrations across multiple disciplines and layout types. With the assistance of multimodal large language models (MLLMs) and human experts, we provide fine-grained atom set annotations and systematically evaluate T2I models along three dimensions: instruction faithfulness, reasoning enrichment, and semantic precision. Our evaluation further decomposes model performance across visual, textual, relation, and layout elements. Results show that even state-of-the-art (SOTA) closed-source models, such as GPT Image 2 and Nano Banana Pro, still suffer from text-rendering bottlenecks, limited reasoning enrichment, and difficulty balancing generation richness with precision. These findings provide practical guidance for improving and deploying T2I models in scientific illustration generation. Benchmark data, atom set annotations, and evaluation code will be released by us.
Project Imaging-X: A Survey of 1000+ Open-Access Medical Imaging Datasets for Foundation Model Development
Mar 29, 2026Foundation models have demonstrated remarkable success across diverse domains and tasks, primarily due to the thrive of large-scale, diverse, and high-quality datasets. However, in the field of medical imaging, the curation and assembling of such medical datasets are highly challenging due to the reliance on clinical expertise and strict ethical and privacy constraints, resulting in a scarcity of large-scale unified medical datasets and hindering the development of powerful medical foundation models. In this work, we present the largest survey to date of medical image datasets, covering over 1,000 open-access datasets with a systematic catalog of their modalities, tasks, anatomies, annotations, limitations, and potential for integration. Our analysis exposes a landscape that is modest in scale, fragmented across narrowly scoped tasks, and unevenly distributed across organs and modalities, which in turn limits the utility of existing medical image datasets for developing versatile and robust medical foundation models. To turn fragmentation into scale, we propose a metadata-driven fusion paradigm (MDFP) that integrates public datasets with shared modalities or tasks, thereby transforming multiple small data silos into larger, more coherent resources. Building on MDFP, we release an interactive discovery portal that enables end-to-end, automated medical image dataset integration, and compile all surveyed datasets into a unified, structured table that clearly summarizes their key characteristics and provides reference links, offering the community an accessible and comprehensive repository. By charting the current terrain and offering a principled path to dataset consolidation, our survey provides a practical roadmap for scaling medical imaging corpora, supporting faster data discovery, more principled dataset creation, and more capable medical foundation models.
Accelerating Masked Image Generation by Learning Latent Controlled Dynamics
Feb 27, 2026Masked Image Generation Models (MIGMs) have achieved great success, yet their efficiency is hampered by the multiple steps of bi-directional attention. In fact, there exists notable redundancy in their computation: when sampling discrete tokens, the rich semantics contained in the continuous features are lost. Some existing works attempt to cache the features to approximate future features. However, they exhibit considerable approximation error under aggressive acceleration rates. We attribute this to their limited expressivity and the failure to account for sampling information. To fill this gap, we propose to learn a lightweight model that incorporates both previous features and sampled tokens, and regresses the average velocity field of feature evolution. The model has moderate complexity that suffices to capture the subtle dynamics while keeping lightweight compared to the original base model. We apply our method, MIGM-Shortcut, to two representative MIGM architectures and tasks. In particular, on the state-of-the-art Lumina-DiMOO, it achieves over 4x acceleration of text-to-image generation while maintaining quality, significantly pushing the Pareto frontier of masked image generation. The code and model weights are available at https://github.com/Kaiwen-Zhu/MIGM-Shortcut.
Toward Generalizable Deblurring: Leveraging Massive Blur Priors with Linear Attention for Real-World Scenarios
Jan 10, 2026Image deblurring has advanced rapidly with deep learning, yet most methods exhibit poor generalization beyond their training datasets, with performance dropping significantly in real-world scenarios. Our analysis shows this limitation stems from two factors: datasets face an inherent trade-off between realism and coverage of diverse blur patterns, and algorithmic designs remain restrictive, as pixel-wise losses drive models toward local detail recovery while overlooking structural and semantic consistency, whereas diffusion-based approaches, though perceptually strong, still fail to generalize when trained on narrow datasets with simplistic strategies. Through systematic investigation, we identify blur pattern diversity as the decisive factor for robust generalization and propose Blur Pattern Pretraining (BPP), which acquires blur priors from simulation datasets and transfers them through joint fine-tuning on real data. We further introduce Motion and Semantic Guidance (MoSeG) to strengthen blur priors under severe degradation, and integrate it into GLOWDeblur, a Generalizable reaL-wOrld lightWeight Deblur model that combines convolution-based pre-reconstruction & domain alignment module with a lightweight diffusion backbone. Extensive experiments on six widely-used benchmarks and two real-world datasets validate our approach, confirming the importance of blur priors for robust generalization and demonstrating that the lightweight design of GLOWDeblur ensures practicality in real-world applications. The project page is available at https://vegdog007.github.io/GLOWDeblur_Website/.
UniPercept: Towards Unified Perceptual-Level Image Understanding across Aesthetics, Quality, Structure, and Texture
Dec 25, 2025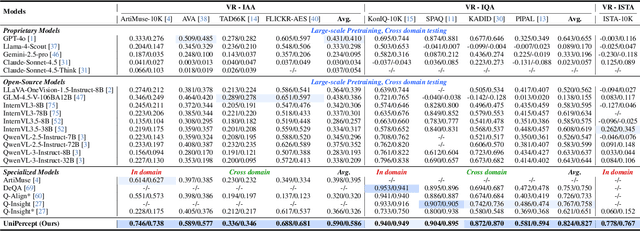

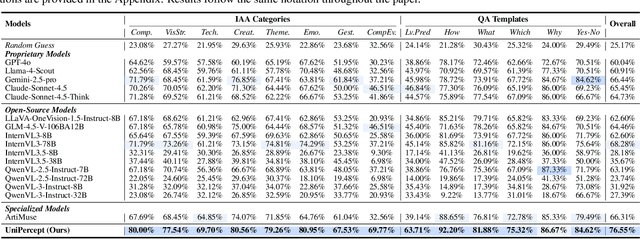
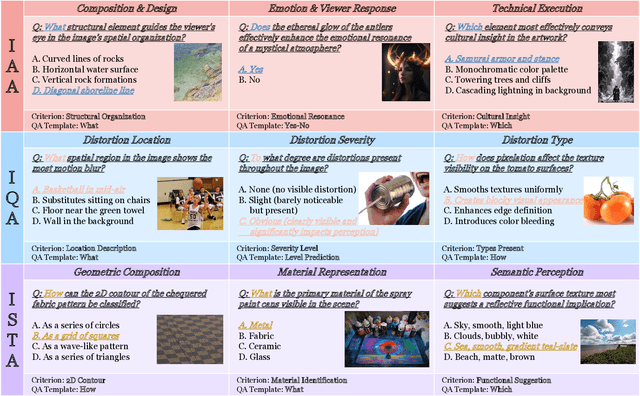
Multimodal large language models (MLLMs) have achieved remarkable progress in visual understanding tasks such as visual grounding, segmentation, and captioning. However, their ability to perceive perceptual-level image features remains limited. In this work, we present UniPercept-Bench, a unified framework for perceptual-level image understanding across three key domains: Aesthetics, Quality, Structure and Texture. We establish a hierarchical definition system and construct large-scale datasets to evaluate perceptual-level image understanding. Based on this foundation, we develop a strong baseline UniPercept trained via Domain-Adaptive Pre-Training and Task-Aligned RL, enabling robust generalization across both Visual Rating (VR) and Visual Question Answering (VQA) tasks. UniPercept outperforms existing MLLMs on perceptual-level image understanding and can serve as a plug-and-play reward model for text-to-image generation. This work defines Perceptual-Level Image Understanding in the era of MLLMs and, through the introduction of a comprehensive benchmark together with a strong baseline, provides a solid foundation for advancing perceptual-level multimodal image understanding.
Omni-Weather: Unified Multimodal Foundation Model for Weather Generation and Understanding
Dec 25, 2025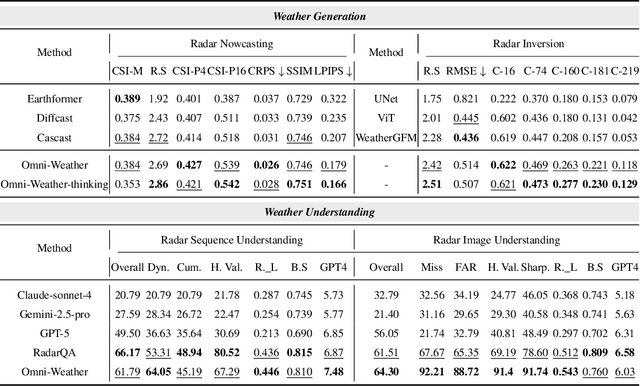
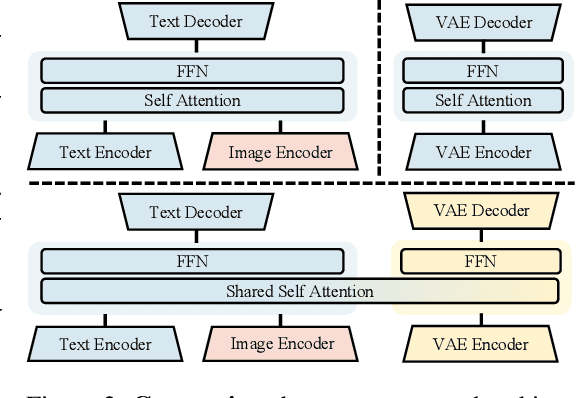
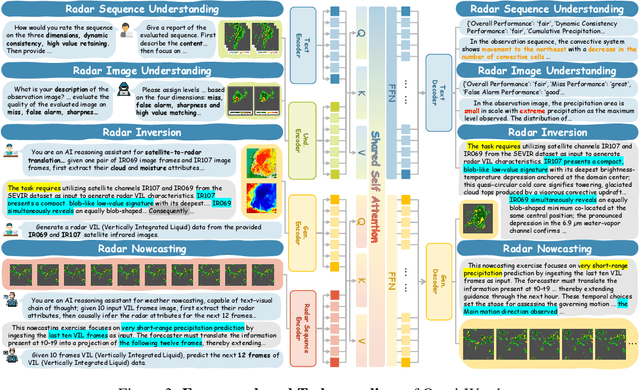

Weather modeling requires both accurate prediction and mechanistic interpretation, yet existing methods treat these goals in isolation, separating generation from understanding. To address this gap, we present Omni-Weather, the first multimodal foundation model that unifies weather generation and understanding within a single architecture. Omni-Weather integrates a radar encoder for weather generation tasks, followed by unified processing using a shared self-attention mechanism. Moreover, we construct a Chain-of-Thought dataset for causal reasoning in weather generation, enabling interpretable outputs and improved perceptual quality. Extensive experiments show Omni-Weather achieves state-of-the-art performance in both weather generation and understanding. Our findings further indicate that generative and understanding tasks in the weather domain can mutually enhance each other. Omni-Weather also demonstrates the feasibility and value of unifying weather generation and understanding.
SynWeather: Weather Observation Data Synthesis across Multiple Regions and Variables via a General Diffusion Transformer
Nov 15, 2025With the advancement of meteorological instruments, abundant data has become available. Current approaches are typically focus on single-variable, single-region tasks and primarily rely on deterministic modeling. This limits unified synthesis across variables and regions, overlooks cross-variable complementarity and often leads to over-smoothed results. To address above challenges, we introduce SynWeather, the first dataset designed for Unified Multi-region and Multi-variable Weather Observation Data Synthesis. SynWeather covers four representative regions: the Continental United States, Europe, East Asia, and Tropical Cyclone regions, as well as provides high-resolution observations of key weather variables, including Composite Radar Reflectivity, Hourly Precipitation, Visible Light, and Microwave Brightness Temperature. In addition, we introduce SynWeatherDiff, a general and probabilistic weather synthesis model built upon the Diffusion Transformer framework to address the over-smoothed problem. Experiments on the SynWeather dataset demonstrate the effectiveness of our network compared with both task-specific and general models.
Factuality Matters: When Image Generation and Editing Meet Structured Visuals
Oct 06, 2025While modern visual generation models excel at creating aesthetically pleasing natural images, they struggle with producing or editing structured visuals like charts, diagrams, and mathematical figures, which demand composition planning, text rendering, and multimodal reasoning for factual fidelity. To address this, we present the first comprehensive, systematic investigation of this domain, encompassing data construction, model training, and an evaluation benchmark. First, we construct a large-scale dataset of 1.3 million high-quality structured image pairs derived from executable drawing programs and augmented with chain-of-thought reasoning annotations. Building on it, we train a unified model that integrates a VLM with FLUX.1 Kontext via a lightweight connector for enhanced multimodal understanding. A three-stage training curriculum enables progressive feature alignment, knowledge infusion, and reasoning-augmented generation, further boosted by an external reasoner at inference time. Finally, we introduce StructBench, a novel benchmark for generation and editing with over 1,700 challenging instances, and an accompanying evaluation metric, StructScore, which employs a multi-round Q\&A protocol to assess fine-grained factual accuracy. Evaluations of 15 models reveal that even leading closed-source systems remain far from satisfactory. Our model attains strong editing performance, and inference-time reasoning yields consistent gains across diverse architectures. By releasing the dataset, model, and benchmark, we aim to advance unified multimodal foundations for structured visuals.
Lumina-OmniLV: A Unified Multimodal Framework for General Low-Level Vision
Apr 08, 2025We present Lunima-OmniLV (abbreviated as OmniLV), a universal multimodal multi-task framework for low-level vision that addresses over 100 sub-tasks across four major categories: image restoration, image enhancement, weak-semantic dense prediction, and stylization. OmniLV leverages both textual and visual prompts to offer flexible and user-friendly interactions. Built on Diffusion Transformer (DiT)-based generative priors, our framework supports arbitrary resolutions -- achieving optimal performance at 1K resolution -- while preserving fine-grained details and high fidelity. Through extensive experiments, we demonstrate that separately encoding text and visual instructions, combined with co-training using shallow feature control, is essential to mitigate task ambiguity and enhance multi-task generalization. Our findings also reveal that integrating high-level generative tasks into low-level vision models can compromise detail-sensitive restoration. These insights pave the way for more robust and generalizable low-level vision systems.
Learning A Low-Level Vision Generalist via Visual Task Prompt
Aug 16, 2024Building a unified model for general low-level vision tasks holds significant research and practical value. Current methods encounter several critical issues. Multi-task restoration approaches can address multiple degradation-to-clean restoration tasks, while their applicability to tasks with different target domains (e.g., image stylization) is limited. Methods like PromptGIP can handle multiple input-target domains but rely on the Masked Autoencoder (MAE) paradigm. Consequently, they are tied to the ViT architecture, resulting in suboptimal image reconstruction quality. In addition, these methods are sensitive to prompt image content and often struggle with low-frequency information processing. In this paper, we propose a Visual task Prompt-based Image Processing (VPIP) framework to overcome these challenges. VPIP employs visual task prompts to manage tasks with different input-target domains and allows flexible selection of backbone network suitable for general tasks. Besides, a new prompt cross-attention is introduced to facilitate interaction between the input and prompt information. Based on the VPIP framework, we train a low-level vision generalist model, namely GenLV, on 30 diverse tasks. Experimental results show that GenLV can successfully address a variety of low-level tasks, significantly outperforming existing methods both quantitatively and qualitatively. Codes are available at https://github.com/chxy95/GenLV.