 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarnessing Diffusion-Yielded Score Priors for Image Restoration
Jul 28, 2025Deep image restoration models aim to learn a mapping from degraded image space to natural image space. However, they face several critical challenges: removing degradation, generating realistic details, and ensuring pixel-level consistency. Over time, three major classes of methods have emerged, including MSE-based, GAN-based, and diffusion-based methods. However, they fail to achieve a good balance between restoration quality, fidelity, and speed. We propose a novel method, HYPIR, to address these challenges. Our solution pipeline is straightforward: it involves initializing the image restoration model with a pre-trained diffusion model and then fine-tuning it with adversarial training. This approach does not rely on diffusion loss, iterative sampling, or additional adapters. We theoretically demonstrate that initializing adversarial training from a pre-trained diffusion model positions the initial restoration model very close to the natural image distribution. Consequently, this initialization improves numerical stability, avoids mode collapse, and substantially accelerates the convergence of adversarial training. Moreover, HYPIR inherits the capabilities of diffusion models with rich user control, enabling text-guided restoration and adjustable texture richness. Requiring only a single forward pass, it achieves faster convergence and inference speed than diffusion-based methods. Extensive experiments show that HYPIR outperforms previous state-of-the-art methods, achieving efficient and high-quality image restoration.
SimpleGVR: A Simple Baseline for Latent-Cascaded Video Super-Resolution
Jun 24, 2025Latent diffusion models have emerged as a leading paradigm for efficient video generation. However, as user expectations shift toward higher-resolution outputs, relying solely on latent computation becomes inadequate. A promising approach involves decoupling the process into two stages: semantic content generation and detail synthesis. The former employs a computationally intensive base model at lower resolutions, while the latter leverages a lightweight cascaded video super-resolution (VSR) model to achieve high-resolution output. In this work, we focus on studying key design principles for latter cascaded VSR models, which are underexplored currently. First, we propose two degradation strategies to generate training pairs that better mimic the output characteristics of the base model, ensuring alignment between the VSR model and its upstream generator. Second, we provide critical insights into VSR model behavior through systematic analysis of (1) timestep sampling strategies, (2) noise augmentation effects on low-resolution (LR) inputs. These findings directly inform our architectural and training innovations. Finally, we introduce interleaving temporal unit and sparse local attention to achieve efficient training and inference, drastically reducing computational overhead. Extensive experiments demonstrate the superiority of our framework over existing methods, with ablation studies confirming the efficacy of each design choice. Our work establishes a simple yet effective baseline for cascaded video super-resolution generation, offering practical insights to guide future advancements in efficient cascaded synthesis systems.
UniCon: Unidirectional Information Flow for Effective Control of Large-Scale Diffusion Models
Mar 21, 2025We introduce UniCon, a novel architecture designed to enhance control and efficiency in training adapters for large-scale diffusion models. Unlike existing methods that rely on bidirectional interaction between the diffusion model and control adapter, UniCon implements a unidirectional flow from the diffusion network to the adapter, allowing the adapter alone to generate the final output. UniCon reduces computational demands by eliminating the need for the diffusion model to compute and store gradients during adapter training. Our results indicate that UniCon reduces GPU memory usage by one-third and increases training speed by 2.3 times, while maintaining the same adapter parameter size. Additionally, without requiring extra computational resources, UniCon enables the training of adapters with double the parameter volume of existing ControlNets. In a series of image conditional generation tasks, UniCon has demonstrated precise responsiveness to control inputs and exceptional generation capabilities.
Interpreting Low-level Vision Models with Causal Effect Maps
Jul 29, 2024



Deep neural networks have significantly improved the performance of low-level vision tasks but also increased the difficulty of interpretability. A deep understanding of deep models is beneficial for both network design and practical reliability. To take up this challenge, we introduce causality theory to interpret low-level vision models and propose a model-/task-agnostic method called Causal Effect Map (CEM). With CEM, we can visualize and quantify the input-output relationships on either positive or negative effects. After analyzing various low-level vision tasks with CEM, we have reached several interesting insights, such as: (1) Using more information of input images (e.g., larger receptive field) does NOT always yield positive outcomes. (2) Attempting to incorporate mechanisms with a global receptive field (e.g., channel attention) into image denoising may prove futile. (3) Integrating multiple tasks to train a general model could encourage the network to prioritize local information over global context. Based on the causal effect theory, the proposed diagnostic tool can refresh our common knowledge and bring a deeper understanding of low-level vision models. Codes are available at https://github.com/J-FHu/CEM.
Scaling Up to Excellence: Practicing Model Scaling for Photo-Realistic Image Restoration In the Wild
Jan 24, 2024We introduce SUPIR (Scaling-UP Image Restoration), a groundbreaking image restoration method that harnesses generative prior and the power of model scaling up. Leveraging multi-modal techniques and advanced generative prior, SUPIR marks a significant advance in intelligent and realistic image restoration. As a pivotal catalyst within SUPIR, model scaling dramatically enhances its capabilities and demonstrates new potential for image restoration. We collect a dataset comprising 20 million high-resolution, high-quality images for model training, each enriched with descriptive text annotations. SUPIR provides the capability to restore images guided by textual prompts, broadening its application scope and potential. Moreover, we introduce negative-quality prompts to further improve perceptual quality. We also develop a restoration-guided sampling method to suppress the fidelity issue encountered in generative-based restoration. Experiments demonstrate SUPIR's exceptional restoration effects and its novel capacity to manipulate restoration through textual prompts.
GET3D--: Learning GET3D from Unconstrained Image Collections
Jul 27, 2023
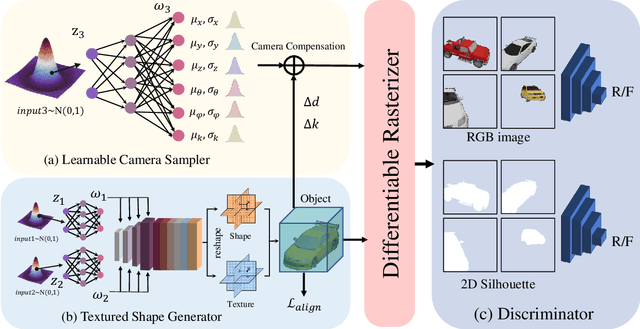
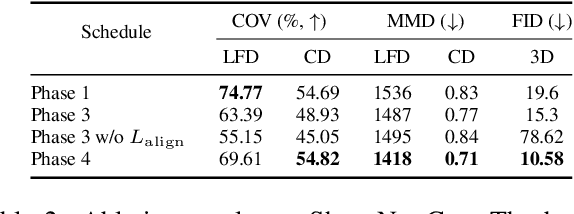

The demand for efficient 3D model generation techniques has grown exponentially, as manual creation of 3D models is time-consuming and requires specialized expertise. While generative models have shown potential in creating 3D textured shapes from 2D images, their applicability in 3D industries is limited due to the lack of a well-defined camera distribution in real-world scenarios, resulting in low-quality shapes. To overcome this limitation, we propose GET3D--, the first method that directly generates textured 3D shapes from 2D images with unknown pose and scale. GET3D-- comprises a 3D shape generator and a learnable camera sampler that captures the 6D external changes on the camera. In addition, We propose a novel training schedule to stably optimize both the shape generator and camera sampler in a unified framework. By controlling external variations using the learnable camera sampler, our method can generate aligned shapes with clear textures. Extensive experiments demonstrate the efficacy of GET3D--, which precisely fits the 6D camera pose distribution and generates high-quality shapes on both synthetic and realistic unconstrained datasets.
OSRT: Omnidirectional Image Super-Resolution with Distortion-aware Transformer
Feb 09, 2023Omnidirectional images (ODIs) have obtained lots of research interest for immersive experiences. Although ODIs require extremely high resolution to capture details of the entire scene, the resolutions of most ODIs are insufficient. Previous methods attempt to solve this issue by image super-resolution (SR) on equirectangular projection (ERP) images. However, they omit geometric properties of ERP in the degradation process, and their models can hardly generalize to real ERP images. In this paper, we propose Fisheye downsampling, which mimics the real-world imaging process and synthesizes more realistic low-resolution samples. Then we design a distortion-aware Transformer (OSRT) to modulate ERP distortions continuously and self-adaptively. Without a cumbersome process, OSRT outperforms previous methods by about 0.2dB on PSNR. Moreover, we propose a convenient data augmentation strategy, which synthesizes pseudo ERP images from plain images. This simple strategy can alleviate the over-fitting problem of large networks and significantly boost the performance of ODISR. Extensive experiments have demonstrated the state-of-the-art performance of our OSRT. Codes and models will be available at https://github.com/Fanghua-Yu/OSRT.