 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScenePilot-Bench: A Large-Scale Dataset and Benchmark for Evaluation of Vision-Language Models in Autonomous Driving
Jan 27, 2026In this paper, we introduce ScenePilot-Bench, a large-scale first-person driving benchmark designed to evaluate vision-language models (VLMs) in autonomous driving scenarios. ScenePilot-Bench is built upon ScenePilot-4K, a diverse dataset comprising 3,847 hours of driving videos, annotated with multi-granularity information including scene descriptions, risk assessments, key participant identification, ego trajectories, and camera parameters. The benchmark features a four-axis evaluation suite that assesses VLM capabilities in scene understanding, spatial perception, motion planning, and GPT-Score, with safety-aware metrics and cross-region generalization settings. We benchmark representative VLMs on ScenePilot-Bench, providing empirical analyses that clarify current performance boundaries and identify gaps for driving-oriented reasoning. ScenePilot-Bench offers a comprehensive framework for evaluating and advancing VLMs in safety-critical autonomous driving contexts.
S2R-HDR: A Large-Scale Rendered Dataset for HDR Fusion
Apr 10, 2025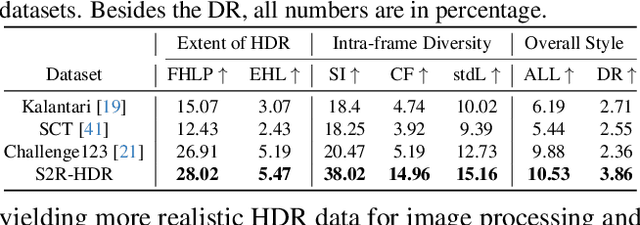
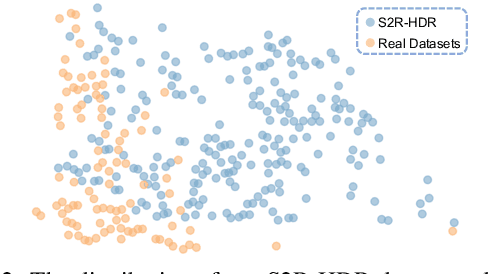
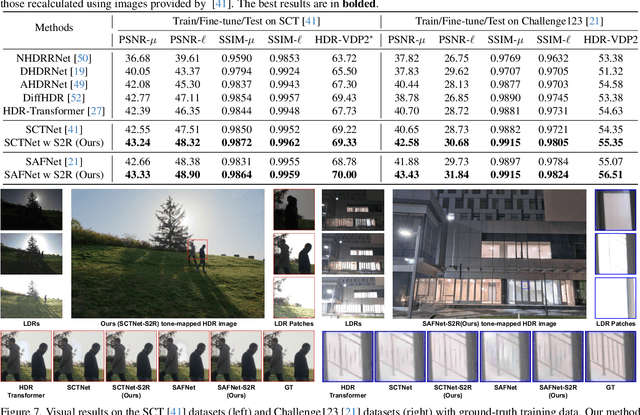

The generalization of learning-based high dynamic range (HDR) fusion is often limited by the availability of training data, as collecting large-scale HDR images from dynamic scenes is both costly and technically challenging. To address these challenges, we propose S2R-HDR, the first large-scale high-quality synthetic dataset for HDR fusion, with 24,000 HDR samples. Using Unreal Engine 5, we design a diverse set of realistic HDR scenes that encompass various dynamic elements, motion types, high dynamic range scenes, and lighting. Additionally, we develop an efficient rendering pipeline to generate realistic HDR images. To further mitigate the domain gap between synthetic and real-world data, we introduce S2R-Adapter, a domain adaptation designed to bridge this gap and enhance the generalization ability of models. Experimental results on real-world datasets demonstrate that our approach achieves state-of-the-art HDR reconstruction performance. Dataset and code will be available at https://openimaginglab.github.io/S2R-HDR.
EGVD: Event-Guided Video Diffusion Model for Physically Realistic Large-Motion Frame Interpolation
Mar 26, 2025Video frame interpolation (VFI) in scenarios with large motion remains challenging due to motion ambiguity between frames. While event cameras can capture high temporal resolution motion information, existing event-based VFI methods struggle with limited training data and complex motion patterns. In this paper, we introduce Event-Guided Video Diffusion Model (EGVD), a novel framework that leverages the powerful priors of pre-trained stable video diffusion models alongside the precise temporal information from event cameras. Our approach features a Multi-modal Motion Condition Generator (MMCG) that effectively integrates RGB frames and event signals to guide the diffusion process, producing physically realistic intermediate frames. We employ a selective fine-tuning strategy that preserves spatial modeling capabilities while efficiently incorporating event-guided temporal information. We incorporate input-output normalization techniques inspired by recent advances in diffusion modeling to enhance training stability across varying noise levels. To improve generalization, we construct a comprehensive dataset combining both real and simulated event data across diverse scenarios. Extensive experiments on both real and simulated datasets demonstrate that EGVD significantly outperforms existing methods in handling large motion and challenging lighting conditions, achieving substantial improvements in perceptual quality metrics (27.4% better LPIPS on Prophesee and 24.1% on BSRGB) while maintaining competitive fidelity measures. Code and datasets available at: https://github.com/OpenImagingLab/EGVD.
RAD: Retrieval-Augmented Decision-Making of Meta-Actions with Vision-Language Models in Autonomous Driving
Mar 18, 2025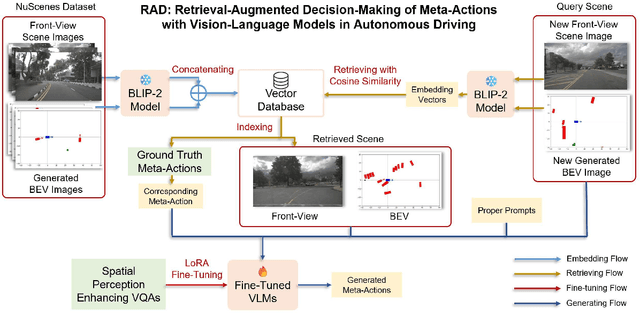
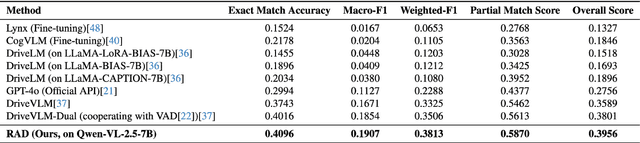
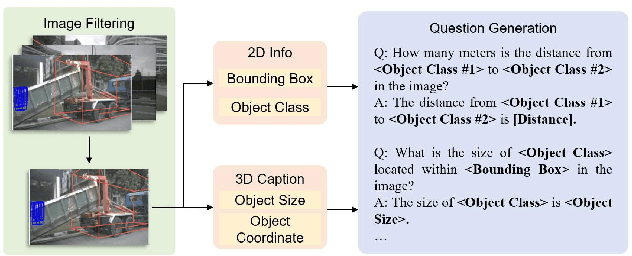
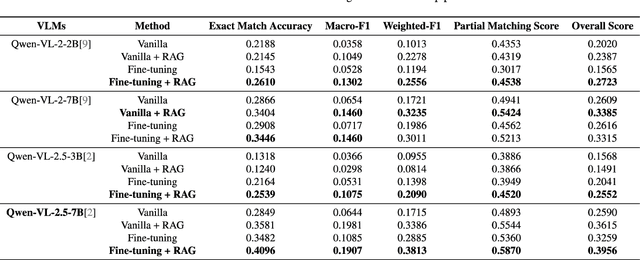
Accurately understanding and deciding high-level meta-actions is essential for ensuring reliable and safe autonomous driving systems. While vision-language models (VLMs) have shown significant potential in various autonomous driving tasks, they often suffer from limitations such as inadequate spatial perception and hallucination, reducing their effectiveness in complex autonomous driving scenarios. To address these challenges, we propose a retrieval-augmented decision-making (RAD) framework, a novel architecture designed to enhance VLMs' capabilities to reliably generate meta-actions in autonomous driving scenes. RAD leverages a retrieval-augmented generation (RAG) pipeline to dynamically improve decision accuracy through a three-stage process consisting of the embedding flow, retrieving flow, and generating flow. Additionally, we fine-tune VLMs on a specifically curated dataset derived from the NuScenes dataset to enhance their spatial perception and bird's-eye view image comprehension capabilities. Extensive experimental evaluations on the curated NuScenes-based dataset demonstrate that RAD outperforms baseline methods across key evaluation metrics, including match accuracy, and F1 score, and self-defined overall score, highlighting its effectiveness in improving meta-action decision-making for autonomous driving tasks.
KAPPA: A Generic Patent Analysis Framework with Keyphrase-Based Portraits
Feb 18, 2025
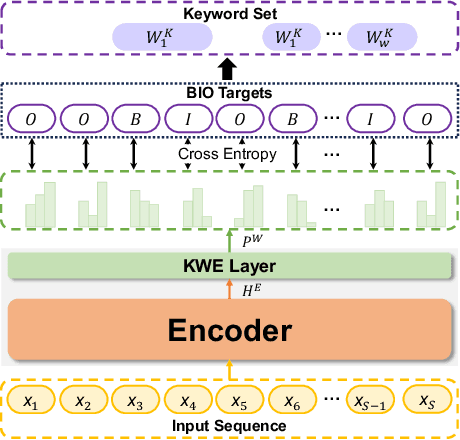
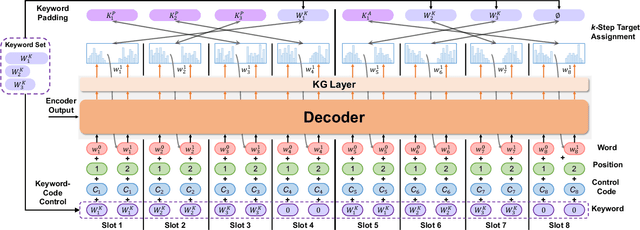
Patent analysis highly relies on concise and interpretable document representations, referred to as patent portraits. Keyphrases, both present and absent, are ideal candidates for patent portraits due to their brevity, representativeness, and clarity. In this paper, we introduce KAPPA, an integrated framework designed to construct keyphrase-based patent portraits and enhance patent analysis. KAPPA operates in two phases: patent portrait construction and portrait-based analysis. To ensure effective portrait construction, we propose a semantic-calibrated keyphrase generation paradigm that integrates pre-trained language models with a prompt-based hierarchical decoding strategy to leverage the multi-level structural characteristics of patents. For portrait-based analysis, we develop a comprehensive framework that employs keyphrase-based patent portraits to enable efficient and accurate patent analysis. Extensive experiments on benchmark datasets of keyphrase generation, the proposed model achieves significant improvements compared to state-of-the-art baselines. Further experiments conducted on real-world patent applications demonstrate that our keyphrase-based portraits effectively capture domain-specific knowledge and enrich semantic representation for patent analysis tasks.
UltraFusion: Ultra High Dynamic Imaging using Exposure Fusion
Jan 20, 2025



Capturing high dynamic range (HDR) scenes is one of the most important issues in camera design. Majority of cameras use exposure fusion technique, which fuses images captured by different exposure levels, to increase dynamic range. However, this approach can only handle images with limited exposure difference, normally 3-4 stops. When applying to very high dynamic scenes where a large exposure difference is required, this approach often fails due to incorrect alignment or inconsistent lighting between inputs, or tone mapping artifacts. In this work, we propose UltraFusion, the first exposure fusion technique that can merge input with 9 stops differences. The key idea is that we model the exposure fusion as a guided inpainting problem, where the under-exposed image is used as a guidance to fill the missing information of over-exposed highlight in the over-exposed region. Using under-exposed image as a soft guidance, instead of a hard constrain, our model is robust to potential alignment issue or lighting variations. Moreover, utilizing the image prior of the generative model, our model also generates natural tone mapping, even for very high-dynamic range scene. Our approach outperforms HDR-Transformer on latest HDR benchmarks. Moreover, to test its performance in ultra high dynamic range scene, we capture a new real-world exposure fusion benchmark, UltraFusion Dataset, with exposure difference up to 9 stops, and experiments show that \model~can generate beautiful and high-quality fusion results under various scenarios. An online demo is provided at https://openimaginglab.github.io/UltraFusion/.
RAC3: Retrieval-Augmented Corner Case Comprehension for Autonomous Driving with Vision-Language Models
Dec 15, 2024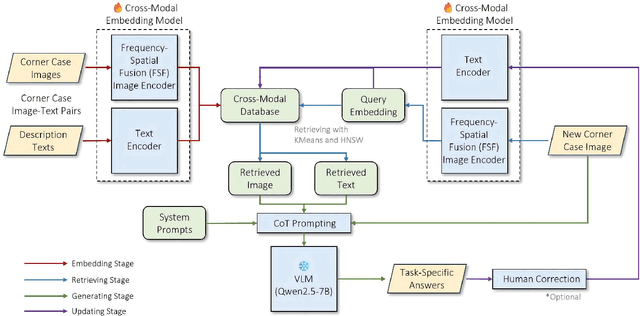
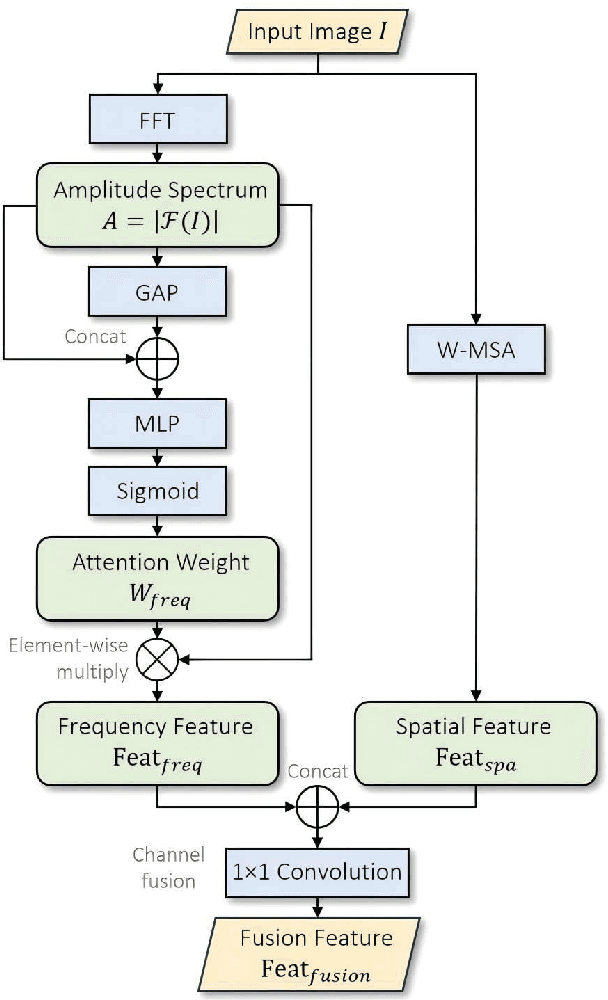
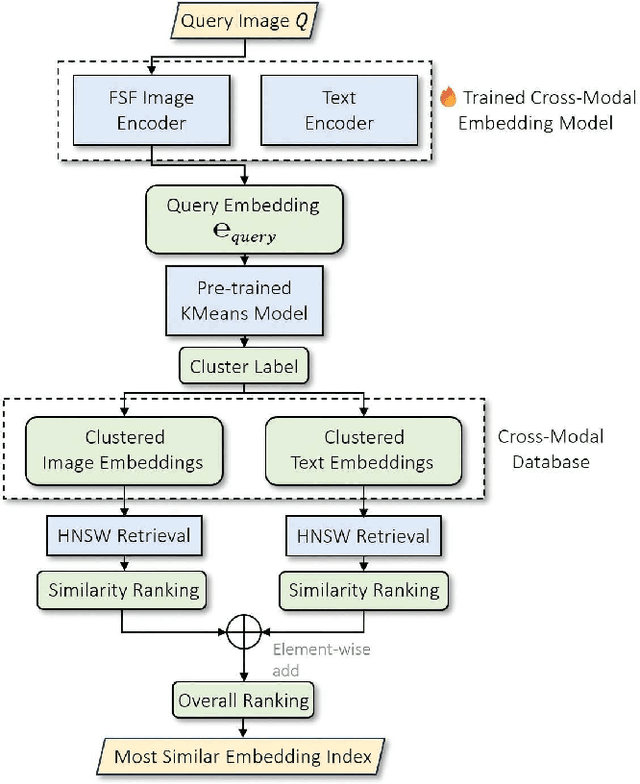

Understanding and addressing corner cases is essential for ensuring the safety and reliability of autonomous driving systems. Vision-Language Models (VLMs) play a crucial role in enhancing scenario comprehension, yet they face significant challenges, such as hallucination and insufficient real-world grounding, which compromise their performance in critical driving scenarios. In this work, we propose RAC3, a novel framework designed to improve VLMs' ability to handle corner cases effectively. The framework integrates Retrieval-Augmented Generation (RAG) to mitigate hallucination by dynamically incorporating context-specific external knowledge. A cornerstone of RAC3 is its cross-modal alignment fine-tuning, which utilizes contrastive learning to embed image-text pairs into a unified semantic space, enabling robust retrieval of similar scenarios. We evaluate RAC3 through extensive experiments using a curated dataset of corner case scenarios, demonstrating its ability to enhance semantic alignment, improve hallucination mitigation, and achieve superior performance metrics, such as Cosine Similarity and ROUGE-L scores. For example, for the LLaVA-v1.6-34B VLM, the cosine similarity between the generated text and the reference text has increased by 5.22\%. The F1-score in ROUGE-L has increased by 39.91\%, the Precision has increased by 55.80\%, and the Recall has increased by 13.74\%. This work underscores the potential of retrieval-augmented VLMs to advance the robustness and safety of autonomous driving in complex environments.
AdaptiveISP: Learning an Adaptive Image Signal Processor for Object Detection
Oct 30, 2024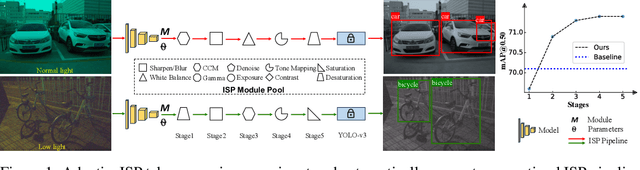
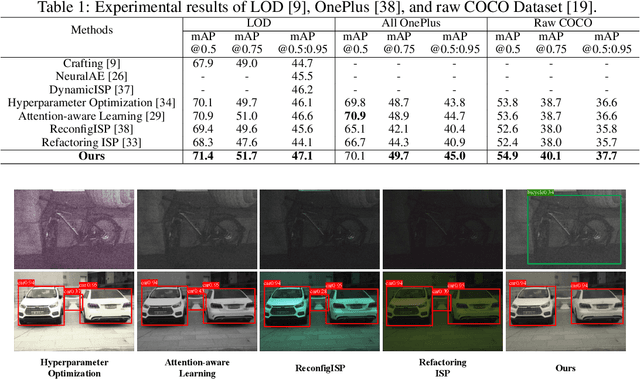
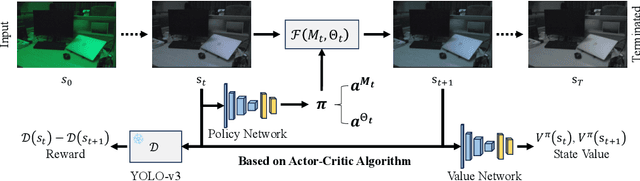
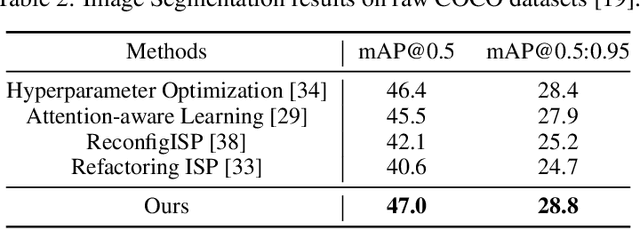
Image Signal Processors (ISPs) convert raw sensor signals into digital images, which significantly influence the image quality and the performance of downstream computer vision tasks. Designing ISP pipeline and tuning ISP parameters are two key steps for building an imaging and vision system. To find optimal ISP configurations, recent works use deep neural networks as a proxy to search for ISP parameters or ISP pipelines. However, these methods are primarily designed to maximize the image quality, which are sub-optimal in the performance of high-level computer vision tasks such as detection, recognition, and tracking. Moreover, after training, the learned ISP pipelines are mostly fixed at the inference time, whose performance degrades in dynamic scenes. To jointly optimize ISP structures and parameters, we propose AdaptiveISP, a task-driven and scene-adaptive ISP. One key observation is that for the majority of input images, only a few processing modules are needed to improve the performance of downstream recognition tasks, and only a few inputs require more processing. Based on this, AdaptiveISP utilizes deep reinforcement learning to automatically generate an optimal ISP pipeline and the associated ISP parameters to maximize the detection performance. Experimental results show that AdaptiveISP not only surpasses the prior state-of-the-art methods for object detection but also dynamically manages the trade-off between detection performance and computational cost, especially suitable for scenes with large dynamic range variations. Project website: https://openimaginglab.github.io/AdaptiveISP/.
DualDn: Dual-domain Denoising via Differentiable ISP
Sep 27, 2024
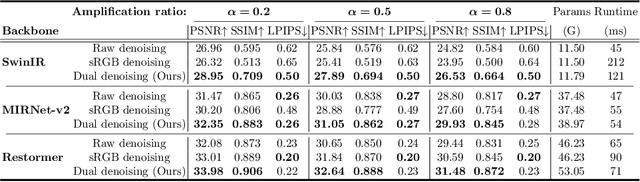
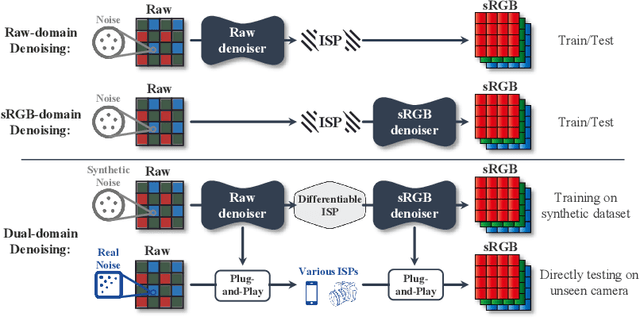
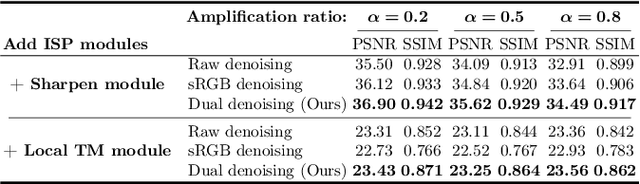
Image denoising is a critical component in a camera's Image Signal Processing (ISP) pipeline. There are two typical ways to inject a denoiser into the ISP pipeline: applying a denoiser directly to captured raw frames (raw domain) or to the ISP's output sRGB images (sRGB domain). However, both approaches have their limitations. Residual noise from raw-domain denoising can be amplified by the subsequent ISP processing, and the sRGB domain struggles to handle spatially varying noise since it only sees noise distorted by the ISP. Consequently, most raw or sRGB domain denoising works only for specific noise distributions and ISP configurations. To address these challenges, we propose DualDn, a novel learning-based dual-domain denoising. Unlike previous single-domain denoising, DualDn consists of two denoising networks: one in the raw domain and one in the sRGB domain. The raw domain denoising adapts to sensor-specific noise as well as spatially varying noise levels, while the sRGB domain denoising adapts to ISP variations and removes residual noise amplified by the ISP. Both denoising networks are connected with a differentiable ISP, which is trained end-to-end and discarded during the inference stage. With this design, DualDn achieves greater generalizability compared to most learning-based denoising methods, as it can adapt to different unseen noises, ISP parameters, and even novel ISP pipelines. Experiments show that DualDn achieves state-of-the-art performance and can adapt to different denoising architectures. Moreover, DualDn can be used as a plug-and-play denoising module with real cameras without retraining, and still demonstrate better performance than commercial on-camera denoising. The project website is available at: https://openimaginglab.github.io/DualDn/
HDRFlow: Real-Time HDR Video Reconstruction with Large Motions
Mar 06, 2024
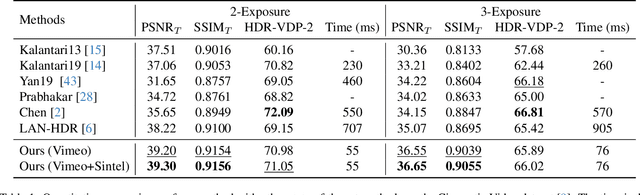

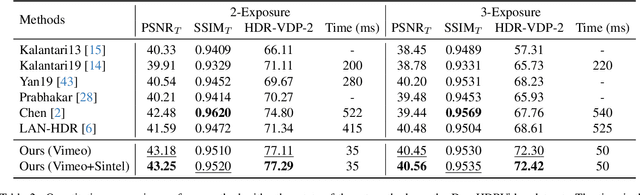
Reconstructing High Dynamic Range (HDR) video from image sequences captured with alternating exposures is challenging, especially in the presence of large camera or object motion. Existing methods typically align low dynamic range sequences using optical flow or attention mechanism for deghosting. However, they often struggle to handle large complex motions and are computationally expensive. To address these challenges, we propose a robust and efficient flow estimator tailored for real-time HDR video reconstruction, named HDRFlow. HDRFlow has three novel designs: an HDR-domain alignment loss (HALoss), an efficient flow network with a multi-size large kernel (MLK), and a new HDR flow training scheme. The HALoss supervises our flow network to learn an HDR-oriented flow for accurate alignment in saturated and dark regions. The MLK can effectively model large motions at a negligible cost. In addition, we incorporate synthetic data, Sintel, into our training dataset, utilizing both its provided forward flow and backward flow generated by us to supervise our flow network, enhancing our performance in large motion regions. Extensive experiments demonstrate that our HDRFlow outperforms previous methods on standard benchmarks. To the best of our knowledge, HDRFlow is the first real-time HDR video reconstruction method for video sequences captured with alternating exposures, capable of processing 720p resolution inputs at 25ms.