 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAC3: Retrieval-Augmented Corner Case Comprehension for Autonomous Driving with Vision-Language Models
Dec 15, 2024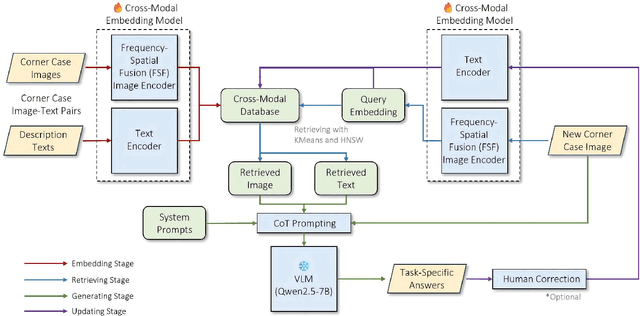
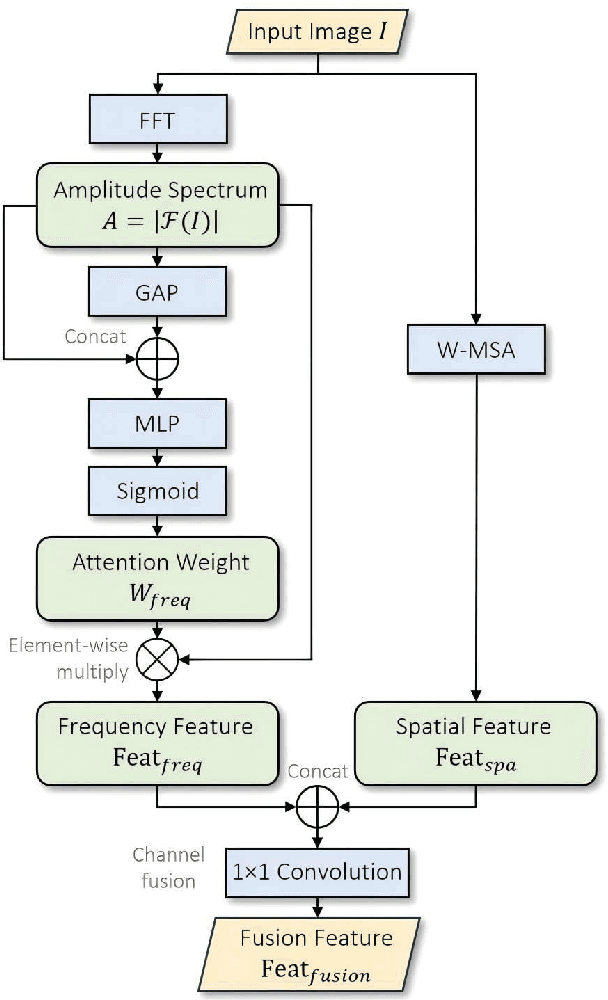
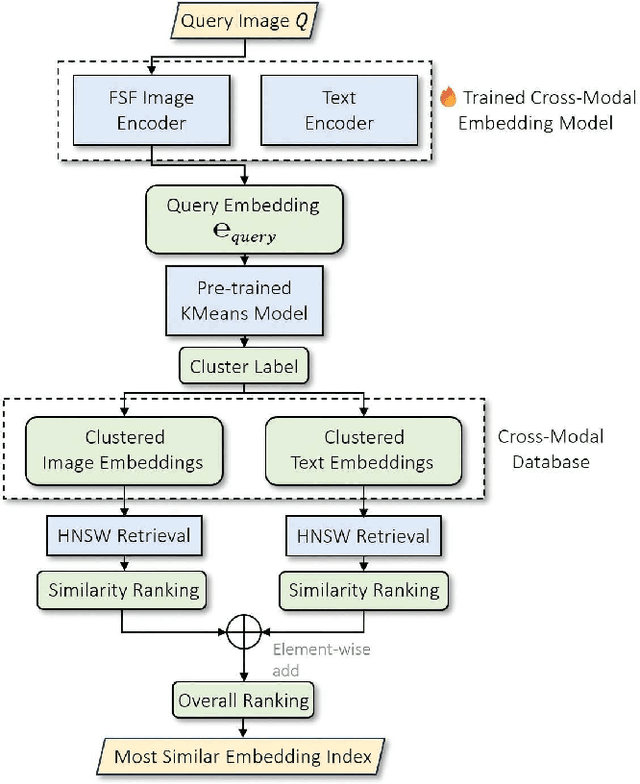

Understanding and addressing corner cases is essential for ensuring the safety and reliability of autonomous driving systems. Vision-Language Models (VLMs) play a crucial role in enhancing scenario comprehension, yet they face significant challenges, such as hallucination and insufficient real-world grounding, which compromise their performance in critical driving scenarios. In this work, we propose RAC3, a novel framework designed to improve VLMs' ability to handle corner cases effectively. The framework integrates Retrieval-Augmented Generation (RAG) to mitigate hallucination by dynamically incorporating context-specific external knowledge. A cornerstone of RAC3 is its cross-modal alignment fine-tuning, which utilizes contrastive learning to embed image-text pairs into a unified semantic space, enabling robust retrieval of similar scenarios. We evaluate RAC3 through extensive experiments using a curated dataset of corner case scenarios, demonstrating its ability to enhance semantic alignment, improve hallucination mitigation, and achieve superior performance metrics, such as Cosine Similarity and ROUGE-L scores. For example, for the LLaVA-v1.6-34B VLM, the cosine similarity between the generated text and the reference text has increased by 5.22\%. The F1-score in ROUGE-L has increased by 39.91\%, the Precision has increased by 55.80\%, and the Recall has increased by 13.74\%. This work underscores the potential of retrieval-augmented VLMs to advance the robustness and safety of autonomous driving in complex environments.