 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent VLMs Guided Self-Training with PNU Loss for Low-Resource Offensive Content Detection
Nov 14, 2025



Accurate detection of offensive content on social media demands high-quality labeled data; however, such data is often scarce due to the low prevalence of offensive instances and the high cost of manual annotation. To address this low-resource challenge, we propose a self-training framework that leverages abundant unlabeled data through collaborative pseudo-labeling. Starting with a lightweight classifier trained on limited labeled data, our method iteratively assigns pseudo-labels to unlabeled instances with the support of Multi-Agent Vision-Language Models (MA-VLMs). Un-labeled data on which the classifier and MA-VLMs agree are designated as the Agreed-Unknown set, while conflicting samples form the Disagreed-Unknown set. To enhance label reliability, MA-VLMs simulate dual perspectives, moderator and user, capturing both regulatory and subjective viewpoints. The classifier is optimized using a novel Positive-Negative-Unlabeled (PNU) loss, which jointly exploits labeled, Agreed-Unknown, and Disagreed-Unknown data while mitigating pseudo-label noise. Experiments on benchmark datasets demonstrate that our framework substantially outperforms baselines under limited supervision and approaches the performance of large-scale models
PhoCoLens: Photorealistic and Consistent Reconstruction in Lensless Imaging
Sep 26, 2024
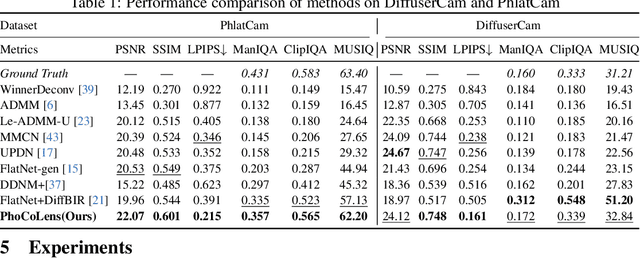

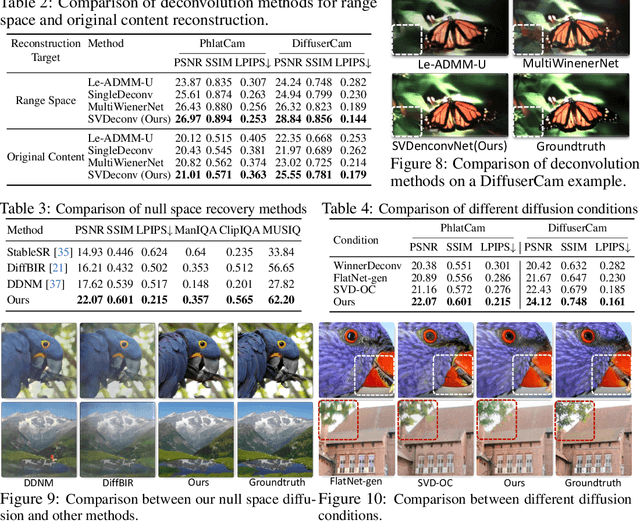
Lensless cameras offer significant advantages in size, weight, and cost compared to traditional lens-based systems. Without a focusing lens, lensless cameras rely on computational algorithms to recover the scenes from multiplexed measurements. However, current algorithms struggle with inaccurate forward imaging models and insufficient priors to reconstruct high-quality images. To overcome these limitations, we introduce a novel two-stage approach for consistent and photorealistic lensless image reconstruction. The first stage of our approach ensures data consistency by focusing on accurately reconstructing the low-frequency content with a spatially varying deconvolution method that adjusts to changes in the Point Spread Function (PSF) across the camera's field of view. The second stage enhances photorealism by incorporating a generative prior from pre-trained diffusion models. By conditioning on the low-frequency content retrieved in the first stage, the diffusion model effectively reconstructs the high-frequency details that are typically lost in the lensless imaging process, while also maintaining image fidelity. Our method achieves a superior balance between data fidelity and visual quality compared to existing methods, as demonstrated with two popular lensless systems, PhlatCam and DiffuserCam. Project website: https://phocolens.github.io/.
LenslessFace: An End-to-End Optimized Lensless System for Privacy-Preserving Face Verification
Jun 06, 2024



Lensless cameras, innovatively replacing traditional lenses for ultra-thin, flat optics, encode light directly onto sensors, producing images that are not immediately recognizable. This compact, lightweight, and cost-effective imaging solution offers inherent privacy advantages, making it attractive for privacy-sensitive applications like face verification. Typical lensless face verification adopts a two-stage process of reconstruction followed by verification, incurring privacy risks from reconstructed faces and high computational costs. This paper presents an end-to-end optimization approach for privacy-preserving face verification directly on encoded lensless captures, ensuring that the entire software pipeline remains encoded with no visible faces as intermediate results. To achieve this, we propose several techniques to address unique challenges from the lensless setup which precludes traditional face detection and alignment. Specifically, we propose a face center alignment scheme, an augmentation curriculum to build robustness against variations, and a knowledge distillation method to smooth optimization and enhance performance. Evaluations under both simulation and real environment demonstrate our method outperforms two-stage lensless verification while enhancing privacy and efficiency. Project website: \url{lenslessface.github.io}.
Stock and market index prediction using Informer network
May 22, 2023Applications of deep learning in financial market prediction has attracted huge attention from investors and researchers. In particular, intra-day prediction at the minute scale, the dramatically fluctuating volume and stock prices within short time periods have posed a great challenge for the convergence of networks result. Informer is a more novel network, improved on Transformer with smaller computational complexity, longer prediction length and global time stamp features. We have designed three experiments to compare Informer with the commonly used networks LSTM, Transformer and BERT on 1-minute and 5-minute frequencies for four different stocks/ market indices. The prediction results are measured by three evaluation criteria: MAE, RMSE and MAPE. Informer has obtained best performance among all the networks on every dataset. Network without the global time stamp mechanism has significantly lower prediction effect compared to the complete Informer; it is evident that this mechanism grants the time series to the characteristics and substantially improves the prediction accuracy of the networks. Finally, transfer learning capability experiment is conducted, Informer also achieves a good performance. Informer has good robustness and improved performance in market prediction, which can be exactly adapted to real trading.