 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-frame Collaboration for Effective Endoscopic Video Polyp Detection via Spatial-Temporal Feature Transformation
Jul 08, 2021
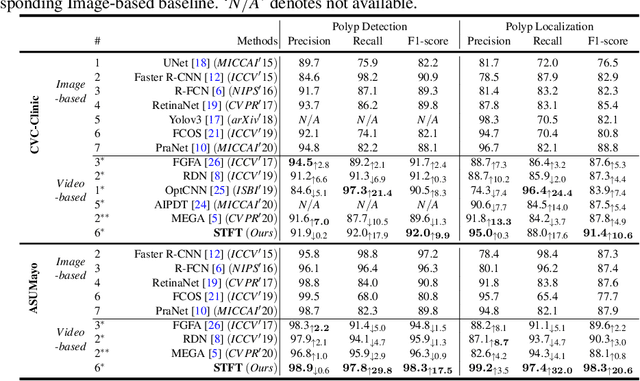
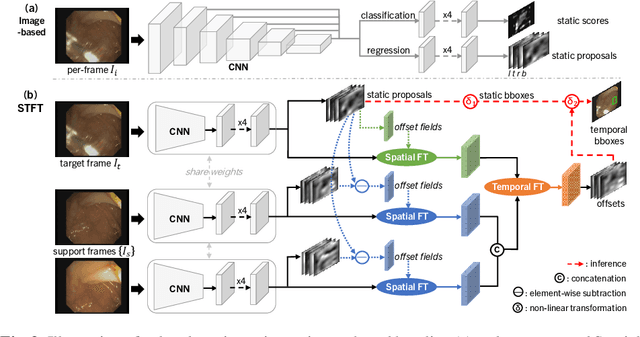

Precise localization of polyp is crucial for early cancer screening in gastrointestinal endoscopy. Videos given by endoscopy bring both richer contextual information as well as more challenges than still images. The camera-moving situation, instead of the common camera-fixed-object-moving one, leads to significant background variation between frames. Severe internal artifacts (e.g. water flow in the human body, specular reflection by tissues) can make the quality of adjacent frames vary considerately. These factors hinder a video-based model to effectively aggregate features from neighborhood frames and give better predictions. In this paper, we present Spatial-Temporal Feature Transformation (STFT), a multi-frame collaborative framework to address these issues. Spatially, STFT mitigates inter-frame variations in the camera-moving situation with feature alignment by proposal-guided deformable convolutions. Temporally, STFT proposes a channel-aware attention module to simultaneously estimate the quality and correlation of adjacent frames for adaptive feature aggregation. Empirical studies and superior results demonstrate the effectiveness and stability of our method. For example, STFT improves the still image baseline FCOS by 10.6% and 20.6% on the comprehensive F1-score of the polyp localization task in CVC-Clinic and ASUMayo datasets, respectively, and outperforms the state-of-the-art video-based method by 3.6% and 8.0%, respectively. Code is available at \url{https://github.com/lingyunwu14/STFT}.
Multi-Compound Transformer for Accurate Biomedical Image Segmentation
Jun 28, 2021
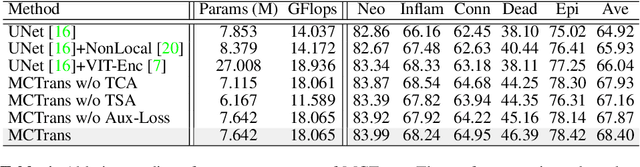
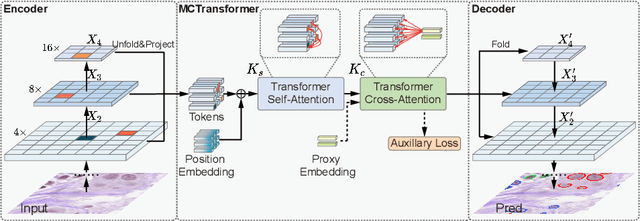
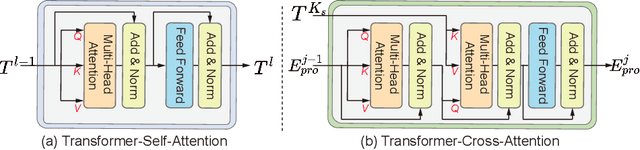
The recent vision transformer(i.e.for image classification) learns non-local attentive interaction of different patch tokens. However, prior arts miss learning the cross-scale dependencies of different pixels, the semantic correspondence of different labels, and the consistency of the feature representations and semantic embeddings, which are critical for biomedical segmentation. In this paper, we tackle the above issues by proposing a unified transformer network, termed Multi-Compound Transformer (MCTrans), which incorporates rich feature learning and semantic structure mining into a unified framework. Specifically, MCTrans embeds the multi-scale convolutional features as a sequence of tokens and performs intra- and inter-scale self-attention, rather than single-scale attention in previous works. In addition, a learnable proxy embedding is also introduced to model semantic relationship and feature enhancement by using self-attention and cross-attention, respectively. MCTrans can be easily plugged into a UNet-like network and attains a significant improvement over the state-of-the-art methods in biomedical image segmentation in six standard benchmarks. For example, MCTrans outperforms UNet by 3.64%, 3.71%, 4.34%, 2.8%, 1.88%, 1.57% in Pannuke, CVC-Clinic, CVC-Colon, Etis, Kavirs, ISIC2018 dataset, respectively. Code is available at https://github.com/JiYuanFeng/MCTrans.
Exemplar Normalization for Learning Deep Representation
Mar 20, 2020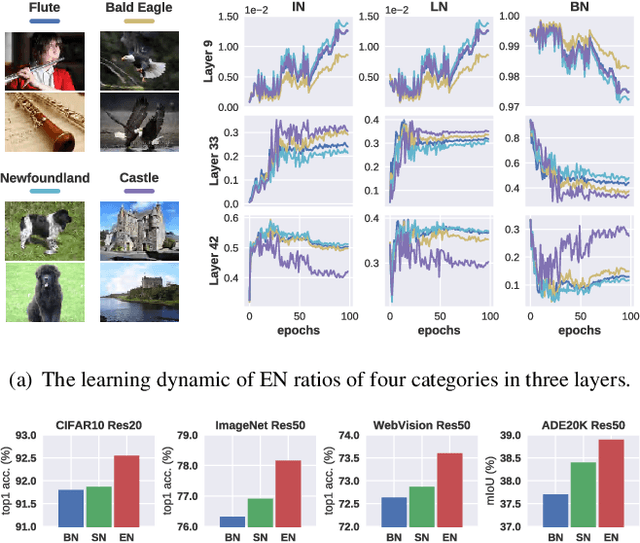
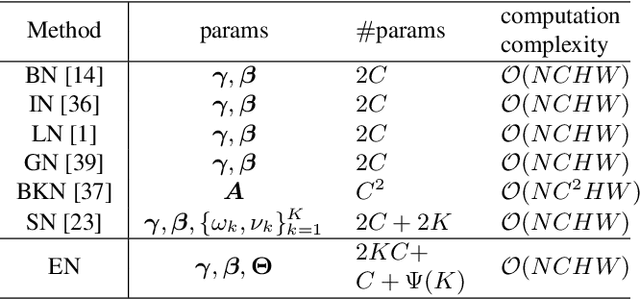
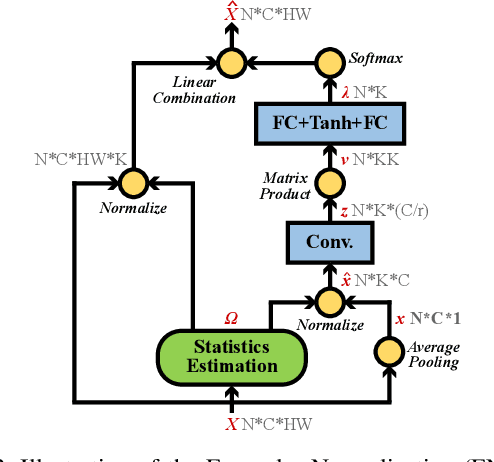
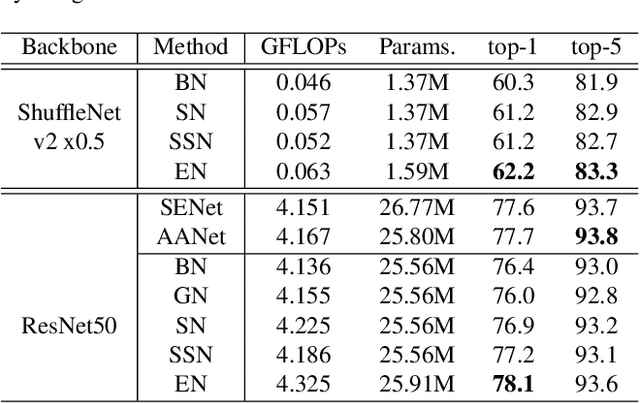
Normalization techniques are important in different advanced neural networks and different tasks. This work investigates a novel dynamic learning-to-normalize (L2N) problem by proposing Exemplar Normalization (EN), which is able to learn different normalization methods for different convolutional layers and image samples of a deep network. EN significantly improves flexibility of the recently proposed switchable normalization (SN), which solves a static L2N problem by linearly combining several normalizers in each normalization layer (the combination is the same for all samples). Instead of directly employing a multi-layer perceptron (MLP) to learn data-dependent parameters as conditional batch normalization (cBN) did, the internal architecture of EN is carefully designed to stabilize its optimization, leading to many appealing benefits. (1) EN enables different convolutional layers, image samples, categories, benchmarks, and tasks to use different normalization methods, shedding light on analyzing them in a holistic view. (2) EN is effective for various network architectures and tasks. (3) It could replace any normalization layers in a deep network and still produce stable model training. Extensive experiments demonstrate the effectiveness of EN in a wide spectrum of tasks including image recognition, noisy label learning, and semantic segmentation. For example, by replacing BN in the ordinary ResNet50, improvement produced by EN is 300% more than that of SN on both ImageNet and the noisy WebVision dataset.
MaskGAN: Towards Diverse and Interactive Facial Image Manipulation
Jul 27, 2019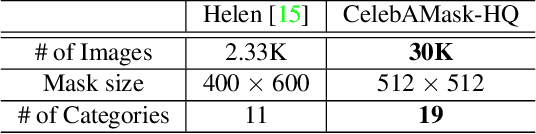
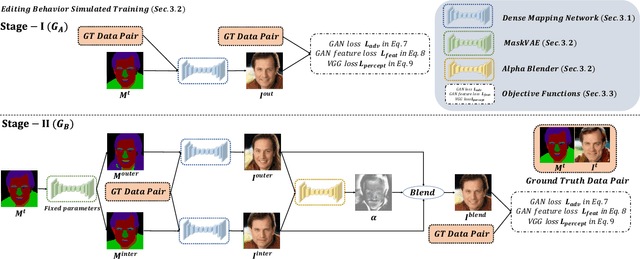
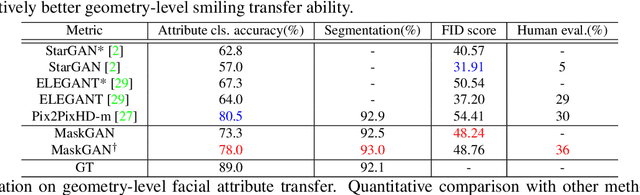
Facial image manipulation has achieved great progresses in recent years. However, previous methods either operate on a predefined set of face attributes or leave users little freedom to interactively manipulate images. To overcome these drawbacks, we propose a novel framework termed MaskGAN, enabling diverse and interactive face manipulation. Our key insight is that semantic masks serve as a suitable intermediate representation for flexible face manipulation with fidelity preservation. MaskGAN has two main components: 1) Dense Mapping Network, and 2) Editing Behavior Simulated Training. Specifically, Dense mapping network learns style mapping between a free-form user modified mask and a target image, enabling diverse generation results. Editing behavior simulated training models the user editing behavior on the source mask, making the overall framework more robust to various manipulated inputs. To facilitate extensive studies, we construct a large-scale high-resolution face dataset with fine-grained mask annotations named CelebAMask-HQ. MaskGAN is comprehensively evaluated on two challenging tasks: attribute transfer and style copy, demonstrating superior performance over other state-of-the-art methods. The code, models and dataset are available at \url{https://github.com/switchablenorms/CelebAMask-HQ}.
DeepFashion2: A Versatile Benchmark for Detection, Pose Estimation, Segmentation and Re-Identification of Clothing Images
Jan 23, 2019
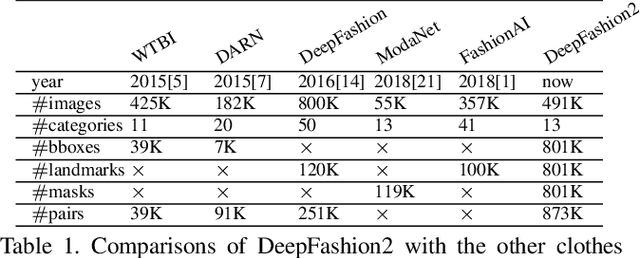


Understanding fashion images has been advanced by benchmarks with rich annotations such as DeepFashion, whose labels include clothing categories, landmarks, and consumer-commercial image pairs. However, DeepFashion has nonnegligible issues such as single clothing-item per image, sparse landmarks (4~8 only), and no per-pixel masks, making it had significant gap from real-world scenarios. We fill in the gap by presenting DeepFashion2 to address these issues. It is a versatile benchmark of four tasks including clothes detection, pose estimation, segmentation, and retrieval. It has 801K clothing items where each item has rich annotations such as style, scale, viewpoint, occlusion, bounding box, dense landmarks and masks. There are also 873K Commercial-Consumer clothes pairs. A strong baseline is proposed, called Match R-CNN, which builds upon Mask R-CNN to solve the above four tasks in an end-to-end manner. Extensive evaluations are conducted with different criterions in DeepFashion2.
Fine-grained Recurrent Neural Networks for Automatic Prostate Segmentation in Ultrasound Images
Dec 06, 2016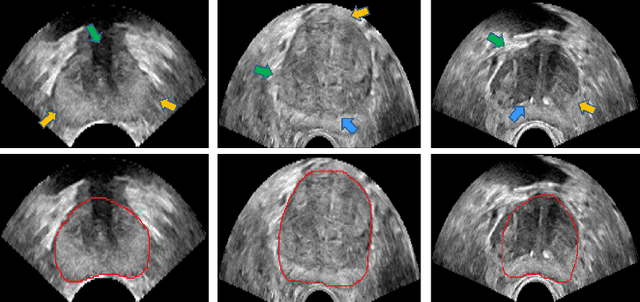
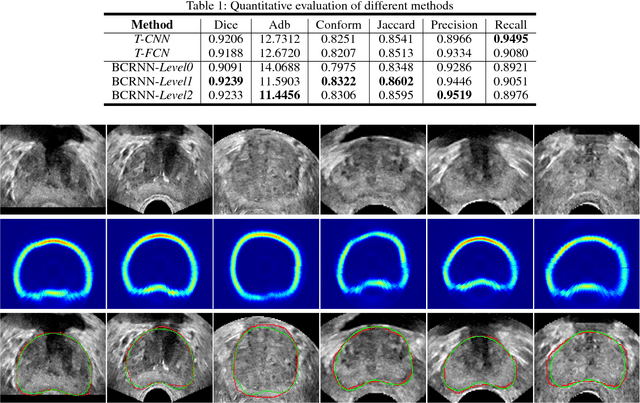
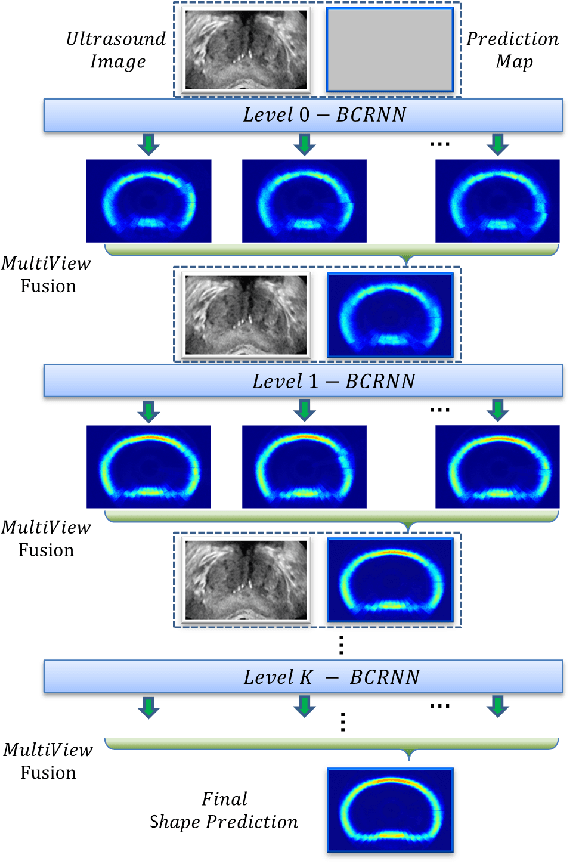
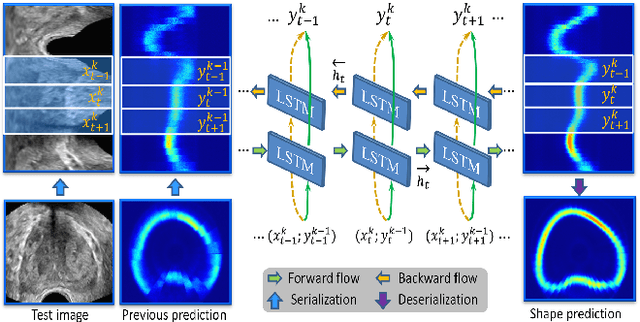
Boundary incompleteness raises great challenges to automatic prostate segmentation in ultrasound images. Shape prior can provide strong guidance in estimating the missing boundary, but traditional shape models often suffer from hand-crafted descriptors and local information loss in the fitting procedure. In this paper, we attempt to address those issues with a novel framework. The proposed framework can seamlessly integrate feature extraction and shape prior exploring, and estimate the complete boundary with a sequential manner. Our framework is composed of three key modules. Firstly, we serialize the static 2D prostate ultrasound images into dynamic sequences and then predict prostate shapes by sequentially exploring shape priors. Intuitively, we propose to learn the shape prior with the biologically plausible Recurrent Neural Networks (RNNs). This module is corroborated to be effective in dealing with the boundary incompleteness. Secondly, to alleviate the bias caused by different serialization manners, we propose a multi-view fusion strategy to merge shape predictions obtained from different perspectives. Thirdly, we further implant the RNN core into a multiscale Auto-Context scheme to successively refine the details of the shape prediction map. With extensive validation on challenging prostate ultrasound images, our framework bridges severe boundary incompleteness and achieves the best performance in prostate boundary delineation when compared with several advanced methods. Additionally, our approach is general and can be extended to other medical image segmentation tasks, where boundary incompleteness is one of the main challenges.