 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-frame Collaboration for Effective Endoscopic Video Polyp Detection via Spatial-Temporal Feature Transformation
Paper and Code

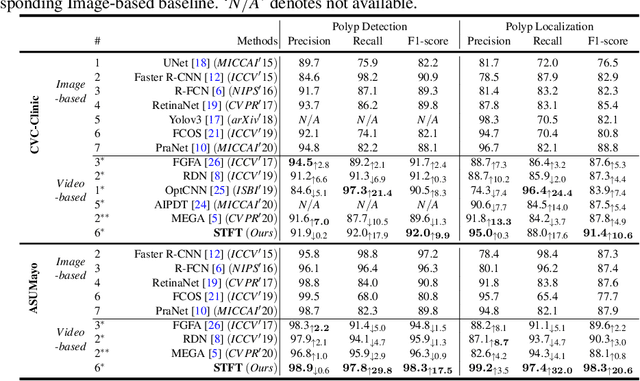
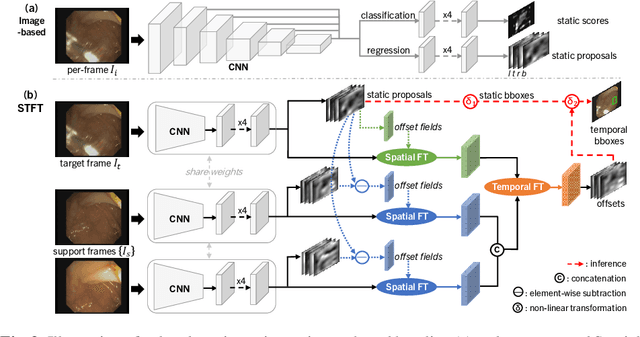

Precise localization of polyp is crucial for early cancer screening in gastrointestinal endoscopy. Videos given by endoscopy bring both richer contextual information as well as more challenges than still images. The camera-moving situation, instead of the common camera-fixed-object-moving one, leads to significant background variation between frames. Severe internal artifacts (e.g. water flow in the human body, specular reflection by tissues) can make the quality of adjacent frames vary considerately. These factors hinder a video-based model to effectively aggregate features from neighborhood frames and give better predictions. In this paper, we present Spatial-Temporal Feature Transformation (STFT), a multi-frame collaborative framework to address these issues. Spatially, STFT mitigates inter-frame variations in the camera-moving situation with feature alignment by proposal-guided deformable convolutions. Temporally, STFT proposes a channel-aware attention module to simultaneously estimate the quality and correlation of adjacent frames for adaptive feature aggregation. Empirical studies and superior results demonstrate the effectiveness and stability of our method. For example, STFT improves the still image baseline FCOS by 10.6% and 20.6% on the comprehensive F1-score of the polyp localization task in CVC-Clinic and ASUMayo datasets, respectively, and outperforms the state-of-the-art video-based method by 3.6% and 8.0%, respectively. Code is available at \url{https://github.com/lingyunwu14/STFT}.