 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterFaceGAN: Interpreting the Disentangled Face Representation Learned by GANs
Paper and Code

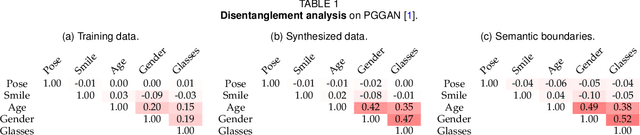
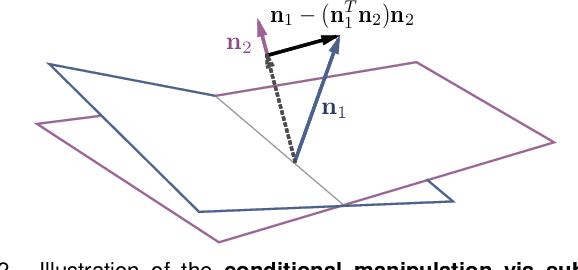
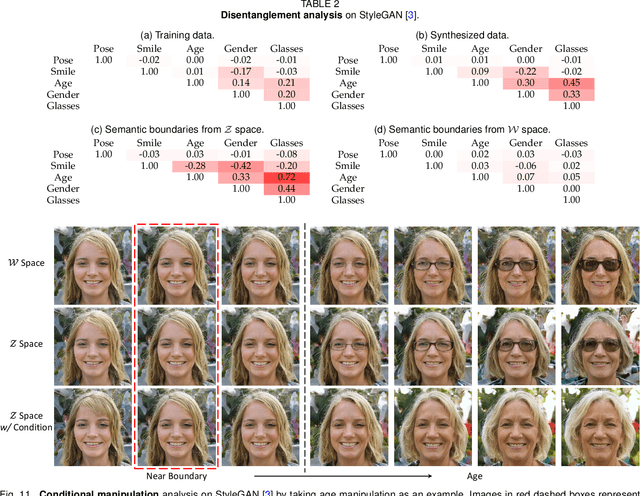
Although Generative Adversarial Networks (GANs) have made significant progress in face synthesis, there lacks enough understanding of what GANs have learned in the latent representation to map a randomly sampled code to a photo-realistic face image. In this work, we propose a framework, called InterFaceGAN, to interpret the disentangled face representation learned by the state-of-the-art GAN models and thoroughly analyze the properties of the facial semantics in the latent space. We first find that GANs actually learn various semantics in some linear subspaces of the latent space when being trained to synthesize high-quality faces. After identifying the subspaces of the corresponding latent semantics, we are able to realistically manipulate the facial attributes occurring in the synthesized images without retraining the model. We then conduct a detailed study on the correlation between different semantics and manage to better disentangle them via subspace projection, resulting in more precise control of the attribute manipulation. Besides manipulating gender, age, expression, and the presence of eyeglasses, we can even alter the face pose as well as fix the artifacts accidentally generated by GANs. Furthermore, we perform in-depth face identity analysis and layer-wise analysis to quantitatively evaluate the editing results. Finally, we apply our approach to real face editing by involving GAN inversion approaches as well as explicitly training additional feed-forward models based on the synthetic data established by InterFaceGAN. Extensive experimental results suggest that learning to synthesize faces spontaneously brings a disentangled and controllable face representation.