 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRM-Depth: Unsupervised Learning of Recurrent Monocular Depth in Dynamic Scenes
Mar 08, 2023


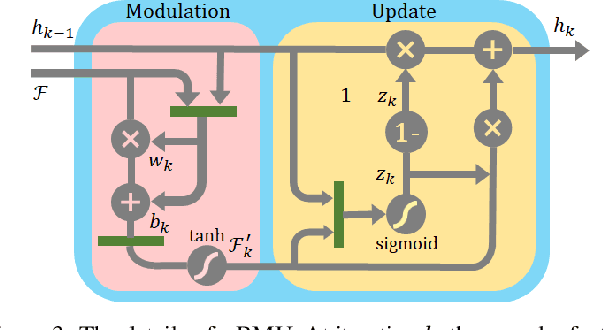
Unsupervised methods have showed promising results on monocular depth estimation. However, the training data must be captured in scenes without moving objects. To push the envelope of accuracy, recent methods tend to increase their model parameters. In this paper, an unsupervised learning framework is proposed to jointly predict monocular depth and complete 3D motion including the motions of moving objects and camera. (1) Recurrent modulation units are used to adaptively and iteratively fuse encoder and decoder features. This not only improves the single-image depth inference but also does not overspend model parameters. (2) Instead of using a single set of filters for upsampling, multiple sets of filters are devised for the residual upsampling. This facilitates the learning of edge-preserving filters and leads to the improved performance. (3) A warping-based network is used to estimate a motion field of moving objects without using semantic priors. This breaks down the requirement of scene rigidity and allows to use general videos for the unsupervised learning. The motion field is further regularized by an outlier-aware training loss. Despite the depth model just uses a single image in test time and 2.97M parameters, it achieves state-of-the-art results on the KITTI and Cityscapes benchmarks.
LiteFlowNet3: Resolving Correspondence Ambiguity for More Accurate Optical Flow Estimation
Jul 18, 2020



Deep learning approaches have achieved great success in addressing the problem of optical flow estimation. The keys to success lie in the use of cost volume and coarse-to-fine flow inference. However, the matching problem becomes ill-posed when partially occluded or homogeneous regions exist in images. This causes a cost volume to contain outliers and affects the flow decoding from it. Besides, the coarse-to-fine flow inference demands an accurate flow initialization. Ambiguous correspondence yields erroneous flow fields and affects the flow inferences in subsequent levels. In this paper, we introduce LiteFlowNet3, a deep network consisting of two specialized modules, to address the above challenges. (1) We ameliorate the issue of outliers in the cost volume by amending each cost vector through an adaptive modulation prior to the flow decoding. (2) We further improve the flow accuracy by exploring local flow consistency. To this end, each inaccurate optical flow is replaced with an accurate one from a nearby position through a novel warping of the flow field. LiteFlowNet3 not only achieves promising results on public benchmarks but also has a small model size and a fast runtime.
Inter-Region Affinity Distillation for Road Marking Segmentation
Apr 11, 2020

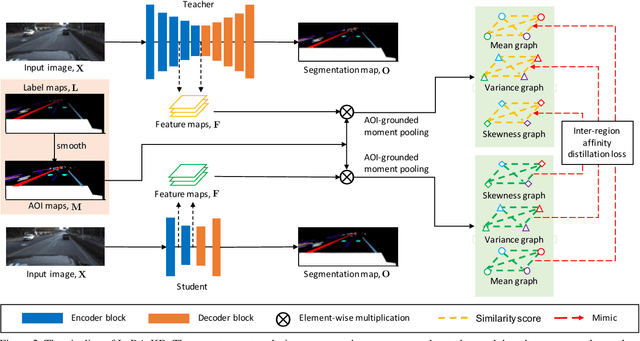

We study the problem of distilling knowledge from a large deep teacher network to a much smaller student network for the task of road marking segmentation. In this work, we explore a novel knowledge distillation (KD) approach that can transfer 'knowledge' on scene structure more effectively from a teacher to a student model. Our method is known as Inter-Region Affinity KD (IntRA-KD). It decomposes a given road scene image into different regions and represents each region as a node in a graph. An inter-region affinity graph is then formed by establishing pairwise relationships between nodes based on their similarity in feature distribution. To learn structural knowledge from the teacher network, the student is required to match the graph generated by the teacher. The proposed method shows promising results on three large-scale road marking segmentation benchmarks, i.e., ApolloScape, CULane and LLAMAS, by taking various lightweight models as students and ResNet-101 as the teacher. IntRA-KD consistently brings higher performance gains on all lightweight models, compared to previous distillation methods. Our code is available at https://github.com/cardwing/Codes-for-IntRA-KD.
Learning to Synthesize Fashion Textures
Nov 18, 2019

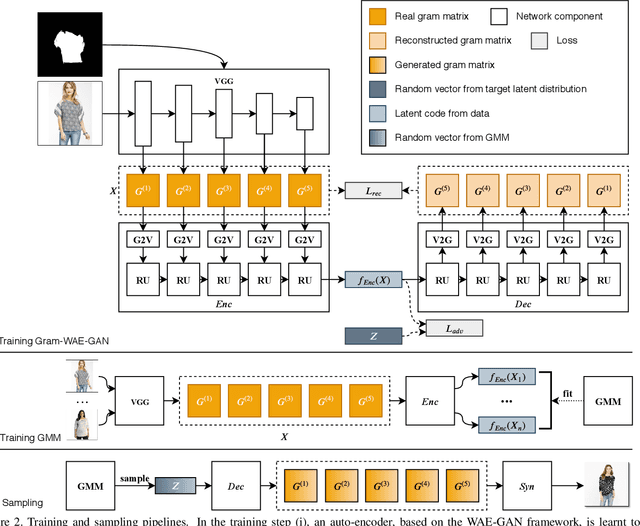

Existing unconditional generative models mainly focus on modeling general objects, such as faces and indoor scenes. Fashion textures, another important type of visual elements around us, have not been extensively studied. In this work, we propose an effective generative model for fashion textures and also comprehensively investigate the key components involved: internal representation, latent space sampling and the generator architecture. We use Gram matrix as a suitable internal representation for modeling realistic fashion textures, and further design two dedicated modules for modulating Gram matrix into a low-dimension vector. Since fashion textures are scale-dependent, we propose a recursive auto-encoder to capture the dependency between multiple granularity levels of texture feature. Another important observation is that fashion textures are multi-modal. We fit and sample from a Gaussian mixture model in the latent space to improve the diversity of the generated textures. Extensive experiments demonstrate that our approach is capable of synthesizing more realistic and diverse fashion textures over other state-of-the-art methods.
A Lightweight Optical Flow CNN - Revisiting Data Fidelity and Regularization
Mar 15, 2019

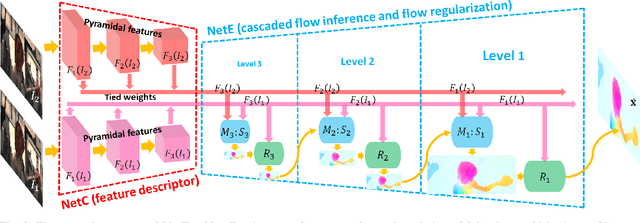
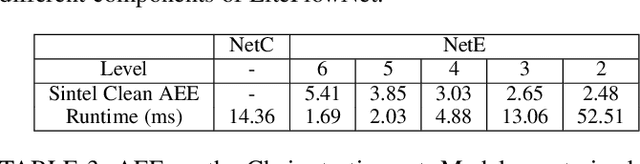
Over four decades, the majority addresses the problem of optical flow estimation using variational methods. With the advance of machine learning, some recent works have attempted to address the problem using convolutional neural network (CNN) and have showed promising results. FlowNet2, the state-of-the-art CNN, requires over 160M parameters to achieve accurate flow estimation. Our LiteFlowNet2 outperforms FlowNet2 on Sintel and KITTI benchmarks, while being 25.3 times smaller in the footprint and 3.1 times faster in the running speed. LiteFlowNet2 which is built on the foundation laid by conventional methods has marked a milestone to achieve the corresponding roles as data fidelity and regularization in variational methods. We present an effective flow inference approach at each pyramid level through a novel lightweight cascaded network. It provides high flow estimation accuracy through early correction with seamless incorporation of descriptor matching. A novel flow regularization layer is used to ameliorate the issue of outliers and vague flow boundaries through a novel feature-driven local convolution. Our network also owns an effective structure for pyramidal feature extraction and embraces feature warping rather than image warping as practiced in FlowNet2. Comparing to our earlier work, LiteFlowNet2 improves the optical flow accuracy on Sintel clean pass by 24%, Sintel final pass by 8.9%, KITTI 2012 by 16.8%, and KITTI 2015 by 17.5%. Our network protocol and trained models will be made publicly available on https://github.com/twhui/LiteFlowNet2 .
LiteFlowNet: A Lightweight Convolutional Neural Network for Optical Flow Estimation
May 18, 2018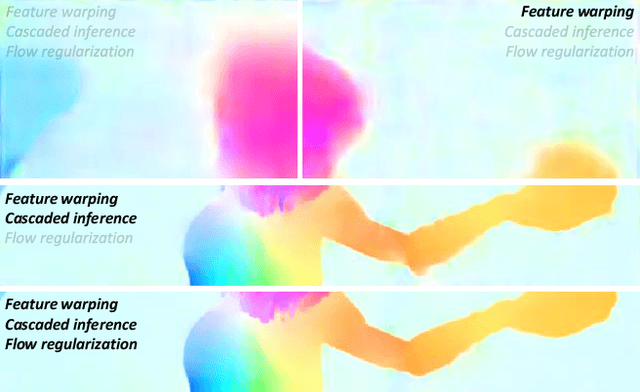
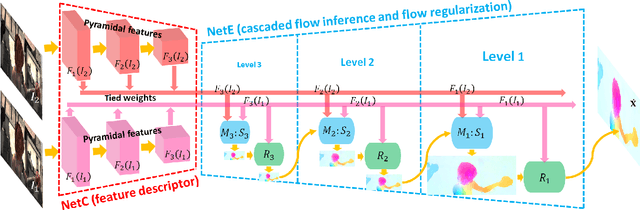


FlowNet2, the state-of-the-art convolutional neural network (CNN) for optical flow estimation, requires over 160M parameters to achieve accurate flow estimation. In this paper we present an alternative network that outperforms FlowNet2 on the challenging Sintel final pass and KITTI benchmarks, while being 30 times smaller in the model size and 1.36 times faster in the running speed. This is made possible by drilling down to architectural details that might have been missed in the current frameworks: (1) We present a more effective flow inference approach at each pyramid level through a lightweight cascaded network. It not only improves flow estimation accuracy through early correction, but also permits seamless incorporation of descriptor matching in our network. (2) We present a novel flow regularization layer to ameliorate the issue of outliers and vague flow boundaries by using a feature-driven local convolution. (3) Our network owns an effective structure for pyramidal feature extraction and embraces feature warping rather than image warping as practiced in FlowNet2. Our code and trained models are available at https://github.com/twhui/LiteFlowNet .