 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Generalist Autonomous Research via Hypothesis-Tree Refinement
Jun 10, 2026Scientific progress depends on a repeated loop of exploration, experimentation, and abstraction. Researchers test candidate directions, interpret the evidence, and carry the resulting lessons into later attempts. We study how an AI agent can run this loop autonomously over long horizons. We introduce Arbor, a general framework for autonomous research that combines a long-lived coordinator, short-lived executors, and Hypothesis Tree Refinement (HTR), a persistent tree that links hypotheses, artifacts, evidence, and distilled insights across time. The coordinator manages global research strategy over the tree, while executors implement and test individual hypotheses in isolated worktrees. As results return, Arbor updates the tree, propagates reusable lessons, refines the search frontier, and admits verified improvements. This design turns autonomous research from a sequence of local attempts into a cumulative process in which strategy, execution, and evidence are carried across time. We evaluate Arbor under Autonomous Optimization (AO), an operational setting where an agent improves an initial research artifact through iterative experimentation without step-level human supervision. Across six real research tasks in model training, harness engineering, and data synthesis, Arbor achieves the best held-out result on all six tasks, attaining more than 2.5x the average relative held-out gain of Codex and Claude Code under the same task interface and resource budget. On MLE-Bench Lite, Arbor reaches 86.36% Any Medal with GPT-5.5, the strongest result in our comparison.
RE-TRAC: REcursive TRAjectory Compression for Deep Search Agents
Feb 02, 2026LLM-based deep research agents are largely built on the ReAct framework. This linear design makes it difficult to revisit earlier states, branch into alternative search directions, or maintain global awareness under long contexts, often leading to local optima, redundant exploration, and inefficient search. We propose Re-TRAC, an agentic framework that performs cross-trajectory exploration by generating a structured state representation after each trajectory to summarize evidence, uncertainties, failures, and future plans, and conditioning subsequent trajectories on this state representation. This enables iterative reflection and globally informed planning, reframing research as a progressive process. Empirical results show that Re-TRAC consistently outperforms ReAct by 15-20% on BrowseComp with frontier LLMs. For smaller models, we introduce Re-TRAC-aware supervised fine-tuning, achieving state-of-the-art performance at comparable scales. Notably, Re-TRAC shows a monotonic reduction in tool calls and token usage across rounds, indicating progressively targeted exploration driven by cross-trajectory reflection rather than redundant search.
LiViBench: An Omnimodal Benchmark for Interactive Livestream Video Understanding
Jan 21, 2026The development of multimodal large language models (MLLMs) has advanced general video understanding. However, existing video evaluation benchmarks primarily focus on non-interactive videos, such as movies and recordings. To fill this gap, this paper proposes the first omnimodal benchmark for interactive livestream videos, LiViBench. It features a diverse set of 24 tasks, highlighting the perceptual, reasoning, and livestream-specific challenges. To efficiently construct the dataset, we design a standardized semi-automatic annotation workflow that incorporates the human-in-the-loop at multiple stages. The workflow leverages multiple MLLMs to form a multi-agent system for comprehensive video description and uses a seed-question-driven method to construct high-quality annotations. All interactive videos in the benchmark include audio, speech, and real-time comments modalities. To enhance models' understanding of interactive videos, we design tailored two-stage instruction-tuning and propose a Video-to-Comment Retrieval (VCR) module to improve the model's ability to utilize real-time comments. Based on these advancements, we develop LiVi-LLM-7B, an MLLM with enhanced knowledge of interactive livestreams. Experiments show that our model outperforms larger open-source models with up to 72B parameters, narrows the gap with leading proprietary models on LiViBench, and achieves enhanced performance on general video benchmarks, including VideoMME, LongVideoBench, MLVU, and VideoEval-Pro.
A Study of Finetuning Video Transformers for Multi-view Geometry Tasks
Dec 21, 2025This paper presents an investigation of vision transformer learning for multi-view geometry tasks, such as optical flow estimation, by fine-tuning video foundation models. Unlike previous methods that involve custom architectural designs and task-specific pretraining, our research finds that general-purpose models pretrained on videos can be readily transferred to multi-view problems with minimal adaptation. The core insight is that general-purpose attention between patches learns temporal and spatial information for geometric reasoning. We demonstrate that appending a linear decoder to the Transformer backbone produces satisfactory results, and iterative refinement can further elevate performance to stateof-the-art levels. This conceptually simple approach achieves top cross-dataset generalization results for optical flow estimation with end-point error (EPE) of 0.69, 1.78, and 3.15 on the Sintel clean, Sintel final, and KITTI datasets, respectively. Our method additionally establishes a new record on the online test benchmark with EPE values of 0.79, 1.88, and F1 value of 3.79. Applications to 3D depth estimation and stereo matching also show strong performance, illustrating the versatility of video-pretrained models in addressing geometric vision tasks.
Logic-RL: Unleashing LLM Reasoning with Rule-Based Reinforcement Learning
Feb 20, 2025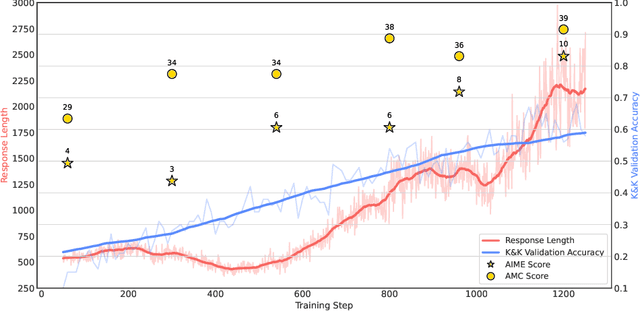



Inspired by the success of DeepSeek-R1, we explore the potential of rule-based reinforcement learning (RL) in large reasoning models. To analyze reasoning dynamics, we use synthetic logic puzzles as training data due to their controllable complexity and straightforward answer verification. We make some key technical contributions that lead to effective and stable RL training: a system prompt that emphasizes the thinking and answering process, a stringent format reward function that penalizes outputs for taking shortcuts, and a straightforward training recipe that achieves stable convergence. Our 7B model develops advanced reasoning skills-such as reflection, verification, and summarization-that are absent from the logic corpus. Remarkably, after training on just 5K logic problems, it demonstrates generalization abilities to the challenging math benchmarks AIME and AMC.
Exploring Transferability for Randomized Smoothing
Dec 14, 2023Training foundation models on extensive datasets and then finetuning them on specific tasks has emerged as the mainstream approach in artificial intelligence. However, the model robustness, which is a critical aspect for safety, is often optimized for each specific task rather than at the pretraining stage. In this paper, we propose a method for pretraining certifiably robust models that can be readily finetuned for adaptation to a particular task. A key challenge is dealing with the compromise between semantic learning and robustness. We address this with a simple yet highly effective strategy based on significantly broadening the pretraining data distribution, which is shown to greatly benefit finetuning for downstream tasks. Through pretraining on a mixture of clean and various noisy images, we find that surprisingly strong certified accuracy can be achieved even when finetuning on only clean images. Furthermore, this strategy requires just a single model to deal with various noise levels, thus substantially reducing computational costs in relation to previous works that employ multiple models. Despite using just one model, our method can still yield results that are on par with, or even superior to, existing multi-model methods.
NuTime: Numerically Multi-Scaled Embedding for Large-Scale Time Series Pretraining
Oct 12, 2023Recent research on time-series self-supervised models shows great promise in learning semantic representations. However, it has been limited to small-scale datasets, e.g., thousands of temporal sequences. In this work, we make key technical contributions that are tailored to the numerical properties of time-series data and allow the model to scale to large datasets, e.g., millions of temporal sequences. We adopt the Transformer architecture by first partitioning the input into non-overlapping windows. Each window is then characterized by its normalized shape and two scalar values denoting the mean and standard deviation within each window. To embed scalar values that may possess arbitrary numerical scales to high-dimensional vectors, we propose a numerically multi-scaled embedding module enumerating all possible scales for the scalar values. The model undergoes pretraining using the proposed numerically multi-scaled embedding with a simple contrastive objective on a large-scale dataset containing over a million sequences. We study its transfer performance on a number of univariate and multivariate classification benchmarks. Our method exhibits remarkable improvement against previous representation learning approaches and establishes the new state of the art, even compared with domain-specific non-learning-based methods.
Associative Transformer Is A Sparse Representation Learner
Sep 22, 2023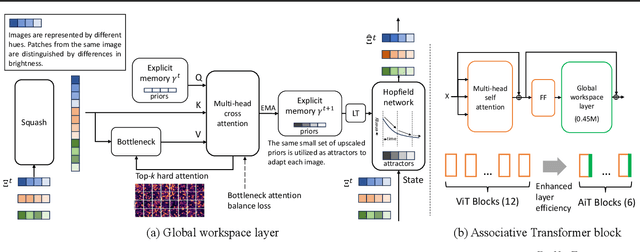
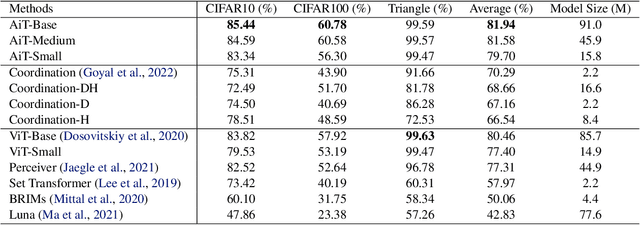
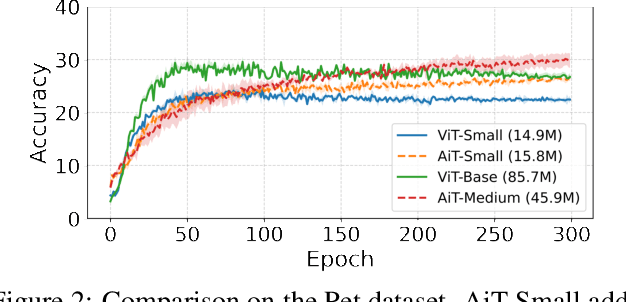
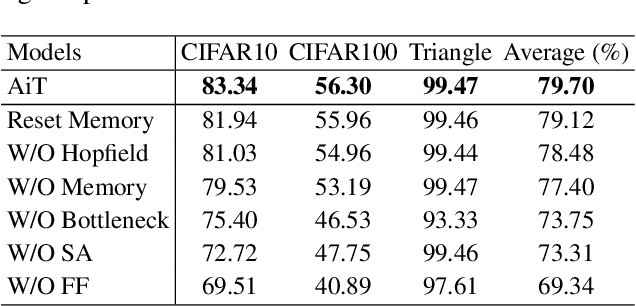
Emerging from the monolithic pairwise attention mechanism in conventional Transformer models, there is a growing interest in leveraging sparse interactions that align more closely with biological principles. Approaches including the Set Transformer and the Perceiver employ cross-attention consolidated with a latent space that forms an attention bottleneck with limited capacity. Building upon recent neuroscience studies of Global Workspace Theory and associative memory, we propose the Associative Transformer (AiT). AiT induces low-rank explicit memory that serves as both priors to guide bottleneck attention in the shared workspace and attractors within associative memory of a Hopfield network. Through joint end-to-end training, these priors naturally develop module specialization, each contributing a distinct inductive bias to form attention bottlenecks. A bottleneck can foster competition among inputs for writing information into the memory. We show that AiT is a sparse representation learner, learning distinct priors through the bottlenecks that are complexity-invariant to input quantities and dimensions. AiT demonstrates its superiority over methods such as the Set Transformer, Vision Transformer, and Coordination in various vision tasks.
Bootstrapping Objectness from Videos by Relaxed Common Fate and Visual Grouping
Apr 17, 2023



We study learning object segmentation from unlabeled videos. Humans can easily segment moving objects without knowing what they are. The Gestalt law of common fate, i.e., what move at the same speed belong together, has inspired unsupervised object discovery based on motion segmentation. However, common fate is not a reliable indicator of objectness: Parts of an articulated / deformable object may not move at the same speed, whereas shadows / reflections of an object always move with it but are not part of it. Our insight is to bootstrap objectness by first learning image features from relaxed common fate and then refining them based on visual appearance grouping within the image itself and across images statistically. Specifically, we learn an image segmenter first in the loop of approximating optical flow with constant segment flow plus small within-segment residual flow, and then by refining it for more coherent appearance and statistical figure-ground relevance. On unsupervised video object segmentation, using only ResNet and convolutional heads, our model surpasses the state-of-the-art by absolute gains of 7/9/5% on DAVIS16 / STv2 / FBMS59 respectively, demonstrating the effectiveness of our ideas. Our code is publicly available.
Randomized Quantization for Data Agnostic Representation Learning
Dec 19, 2022Self-supervised representation learning follows a paradigm of withholding some part of the data and tasking the network to predict it from the remaining part. Towards this end, masking has emerged as a generic and powerful tool where content is withheld along the sequential dimension, e.g., spatial in images, temporal in audio, and syntactic in language. In this paper, we explore the orthogonal channel dimension for generic data augmentation. The data for each channel is quantized through a non-uniform quantizer, with the quantized value sampled randomly within randomly sampled quantization bins. From another perspective, quantization is analogous to channel-wise masking, as it removes the information within each bin, but preserves the information across bins. We apply the randomized quantization in conjunction with sequential augmentations on self-supervised contrastive models. This generic approach achieves results on par with modality-specific augmentation on vision tasks, and state-of-the-art results on 3D point clouds as well as on audio. We also demonstrate this method to be applicable for augmenting intermediate embeddings in a deep neural network on the comprehensive DABS benchmark which is comprised of various data modalities. Code is availabel at http://www.github.com/microsoft/random_quantize.