 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStep 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
Feb 11, 2026We introduce Step 3.5 Flash, a sparse Mixture-of-Experts (MoE) model that bridges frontier-level agentic intelligence and computational efficiency. We focus on what matters most when building agents: sharp reasoning and fast, reliable execution. Step 3.5 Flash pairs a 196B-parameter foundation with 11B active parameters for efficient inference. It is optimized with interleaved 3:1 sliding-window/full attention and Multi-Token Prediction (MTP-3) to reduce the latency and cost of multi-round agentic interactions. To reach frontier-level intelligence, we design a scalable reinforcement learning framework that combines verifiable signals with preference feedback, while remaining stable under large-scale off-policy training, enabling consistent self-improvement across mathematics, code, and tool use. Step 3.5 Flash demonstrates strong performance across agent, coding, and math tasks, achieving 85.4% on IMO-AnswerBench, 86.4% on LiveCodeBench-v6 (2024.08-2025.05), 88.2% on tau2-Bench, 69.0% on BrowseComp (with context management), and 51.0% on Terminal-Bench 2.0, comparable to frontier models such as GPT-5.2 xHigh and Gemini 3.0 Pro. By redefining the efficiency frontier, Step 3.5 Flash provides a high-density foundation for deploying sophisticated agents in real-world industrial environments.
A Study of Finetuning Video Transformers for Multi-view Geometry Tasks
Dec 21, 2025This paper presents an investigation of vision transformer learning for multi-view geometry tasks, such as optical flow estimation, by fine-tuning video foundation models. Unlike previous methods that involve custom architectural designs and task-specific pretraining, our research finds that general-purpose models pretrained on videos can be readily transferred to multi-view problems with minimal adaptation. The core insight is that general-purpose attention between patches learns temporal and spatial information for geometric reasoning. We demonstrate that appending a linear decoder to the Transformer backbone produces satisfactory results, and iterative refinement can further elevate performance to stateof-the-art levels. This conceptually simple approach achieves top cross-dataset generalization results for optical flow estimation with end-point error (EPE) of 0.69, 1.78, and 3.15 on the Sintel clean, Sintel final, and KITTI datasets, respectively. Our method additionally establishes a new record on the online test benchmark with EPE values of 0.79, 1.88, and F1 value of 3.79. Applications to 3D depth estimation and stereo matching also show strong performance, illustrating the versatility of video-pretrained models in addressing geometric vision tasks.
Compete to Win: Enhancing Pseudo Labels for Barely-supervised Medical Image Segmentation
Apr 15, 2023
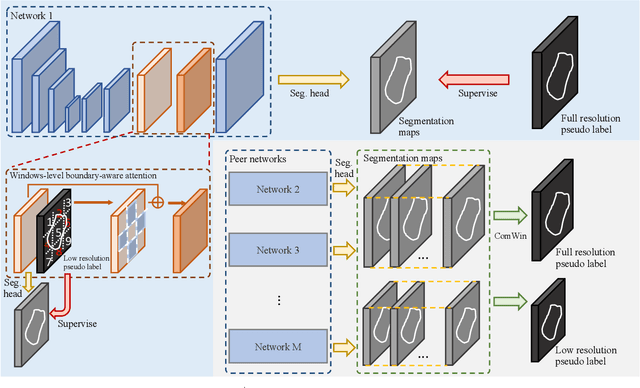
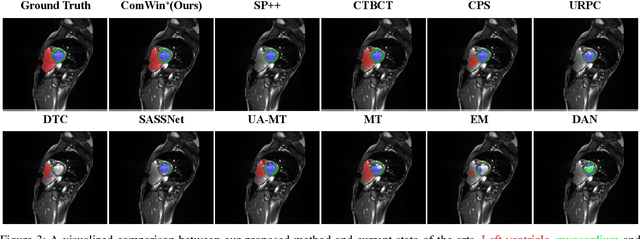

This study investigates barely-supervised medical image segmentation where only few labeled data, i.e., single-digit cases are available. We observe the key limitation of the existing state-of-the-art semi-supervised solution cross pseudo supervision is the unsatisfactory precision of foreground classes, leading to a degenerated result under barely-supervised learning. In this paper, we propose a novel Compete-to-Win method (ComWin) to enhance the pseudo label quality. In contrast to directly using one model's predictions as pseudo labels, our key idea is that high-quality pseudo labels should be generated by comparing multiple confidence maps produced by different networks to select the most confident one (a compete-to-win strategy). To further refine pseudo labels at near-boundary areas, an enhanced version of ComWin, namely, ComWin+, is proposed by integrating a boundary-aware enhancement module. Experiments show that our method can achieve the best performance on three public medical image datasets for cardiac structure segmentation, pancreas segmentation and colon tumor segmentation, respectively. The source code is now available at https://github.com/Huiimin5/comwin.
Randomized Quantization for Data Agnostic Representation Learning
Dec 19, 2022Self-supervised representation learning follows a paradigm of withholding some part of the data and tasking the network to predict it from the remaining part. Towards this end, masking has emerged as a generic and powerful tool where content is withheld along the sequential dimension, e.g., spatial in images, temporal in audio, and syntactic in language. In this paper, we explore the orthogonal channel dimension for generic data augmentation. The data for each channel is quantized through a non-uniform quantizer, with the quantized value sampled randomly within randomly sampled quantization bins. From another perspective, quantization is analogous to channel-wise masking, as it removes the information within each bin, but preserves the information across bins. We apply the randomized quantization in conjunction with sequential augmentations on self-supervised contrastive models. This generic approach achieves results on par with modality-specific augmentation on vision tasks, and state-of-the-art results on 3D point clouds as well as on audio. We also demonstrate this method to be applicable for augmenting intermediate embeddings in a deep neural network on the comprehensive DABS benchmark which is comprised of various data modalities. Code is availabel at http://www.github.com/microsoft/random_quantize.
Zeroth-Order Hard-Thresholding: Gradient Error vs. Expansivity
Oct 11, 2022

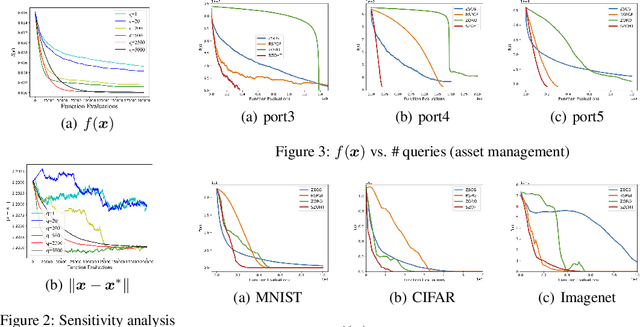
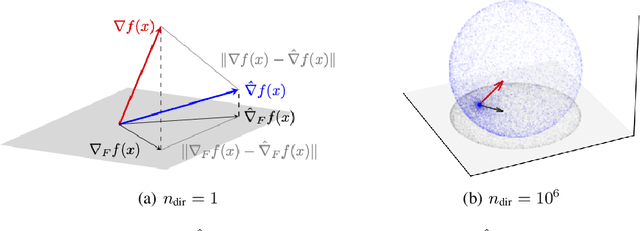
$\ell_0$ constrained optimization is prevalent in machine learning, particularly for high-dimensional problems, because it is a fundamental approach to achieve sparse learning. Hard-thresholding gradient descent is a dominant technique to solve this problem. However, first-order gradients of the objective function may be either unavailable or expensive to calculate in a lot of real-world problems, where zeroth-order (ZO) gradients could be a good surrogate. Unfortunately, whether ZO gradients can work with the hard-thresholding operator is still an unsolved problem. To solve this puzzle, in this paper, we focus on the $\ell_0$ constrained black-box stochastic optimization problems, and propose a new stochastic zeroth-order gradient hard-thresholding (SZOHT) algorithm with a general ZO gradient estimator powered by a novel random support sampling. We provide the convergence analysis of SZOHT under standard assumptions. Importantly, we reveal a conflict between the deviation of ZO estimators and the expansivity of the hard-thresholding operator, and provide a theoretical minimal value of the number of random directions in ZO gradients. In addition, we find that the query complexity of SZOHT is independent or weakly dependent on the dimensionality under different settings. Finally, we illustrate the utility of our method on a portfolio optimization problem as well as black-box adversarial attacks.
FedMix: Mixed Supervised Federated Learning for Medical Image Segmentation
May 04, 2022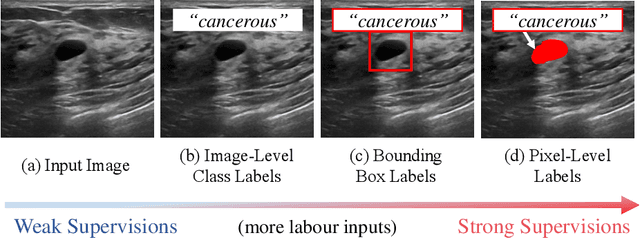
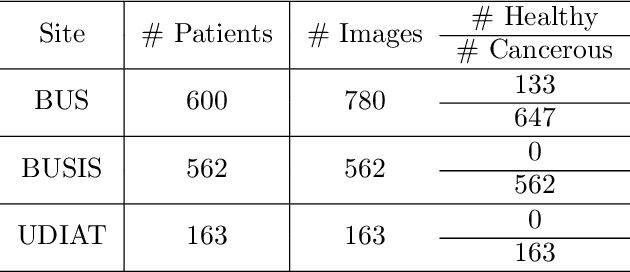
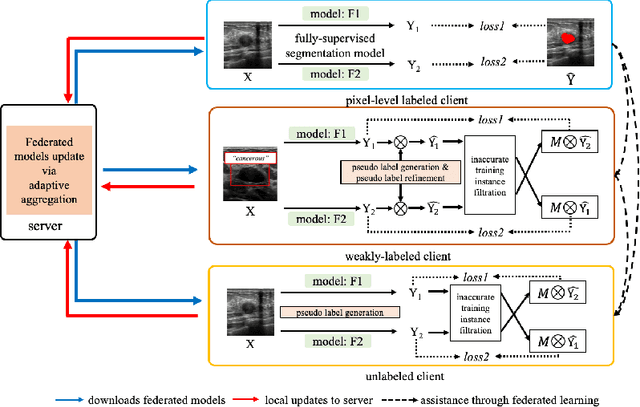
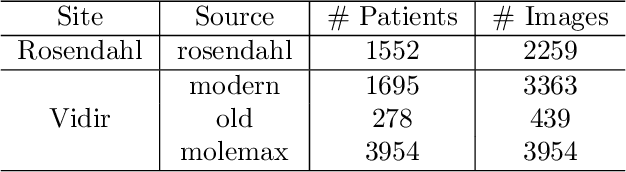
The purpose of federated learning is to enable multiple clients to jointly train a machine learning model without sharing data. However, the existing methods for training an image segmentation model have been based on an unrealistic assumption that the training set for each local client is annotated in a similar fashion and thus follows the same image supervision level. To relax this assumption, in this work, we propose a label-agnostic unified federated learning framework, named FedMix, for medical image segmentation based on mixed image labels. In FedMix, each client updates the federated model by integrating and effectively making use of all available labeled data ranging from strong pixel-level labels, weak bounding box labels, to weakest image-level class labels. Based on these local models, we further propose an adaptive weight assignment procedure across local clients, where each client learns an aggregation weight during the global model update. Compared to the existing methods, FedMix not only breaks through the constraint of a single level of image supervision, but also can dynamically adjust the aggregation weight of each local client, achieving rich yet discriminative feature representations. To evaluate its effectiveness, experiments have been carried out on two challenging medical image segmentation tasks, i.e., breast tumor segmentation and skin lesion segmentation. The results validate that our proposed FedMix outperforms the state-of-the-art method by a large margin.
Deep Understanding based Multi-Document Machine Reading Comprehension
Feb 25, 2022
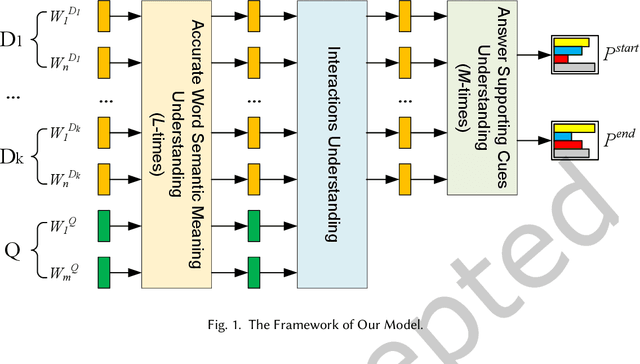
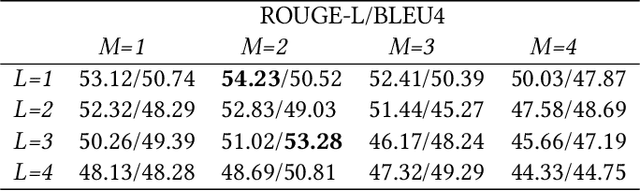
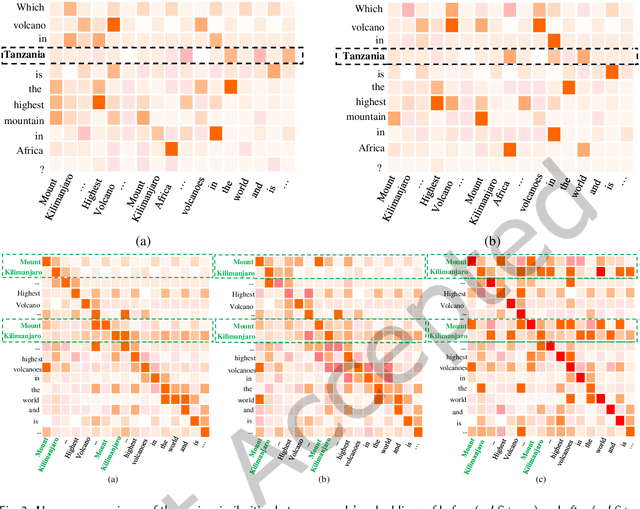
Most existing multi-document machine reading comprehension models mainly focus on understanding the interactions between the input question and documents, but ignore following two kinds of understandings. First, to understand the semantic meaning of words in the input question and documents from the perspective of each other. Second, to understand the supporting cues for a correct answer from the perspective of intra-document and inter-documents. Ignoring these two kinds of important understandings would make the models oversee some important information that may be helpful for inding correct answers. To overcome this deiciency, we propose a deep understanding based model for multi-document machine reading comprehension. It has three cascaded deep understanding modules which are designed to understand the accurate semantic meaning of words, the interactions between the input question and documents, and the supporting cues for the correct answer. We evaluate our model on two large scale benchmark datasets, namely TriviaQA Web and DuReader. Extensive experiments show that our model achieves state-of-the-art results on both datasets.
Exploring Feature Representation Learning for Semi-supervised Medical Image Segmentation
Nov 22, 2021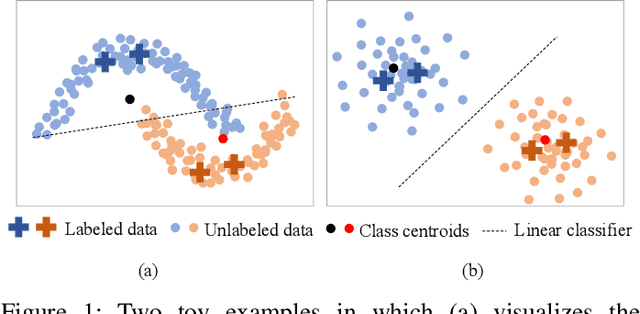



This paper presents a simple yet effective two-stage framework for semi-supervised medical image segmentation. Our key insight is to explore the feature representation learning with labeled and unlabeled (i.e., pseudo labeled) images to enhance the segmentation performance. In the first stage, we present an aleatoric uncertainty-aware method, namely AUA, to improve the segmentation performance for generating high-quality pseudo labels. Considering the inherent ambiguity of medical images, AUA adaptively regularizes the consistency on images with low ambiguity. To enhance the representation learning, we propose a stage-adaptive contrastive learning method, including a boundary-aware contrastive loss to regularize the labeled images in the first stage and a prototype-aware contrastive loss to optimize both labeled and pseudo labeled images in the second stage. The boundary-aware contrastive loss only optimizes pixels around the segmentation boundaries to reduce the computational cost. The prototype-aware contrastive loss fully leverages both labeled images and pseudo labeled images by building a centroid for each class to reduce computational cost for pair-wise comparison. Our method achieves the best results on two public medical image segmentation benchmarks. Notably, our method outperforms the prior state-of-the-art by 5.7% on Dice for colon tumor segmentation relying on just 5% labeled images.
Fast and Scalable Adversarial Training of Kernel SVM via Doubly Stochastic Gradients
Jul 21, 2021
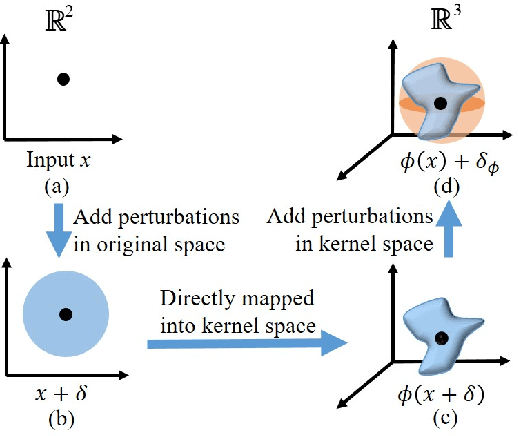
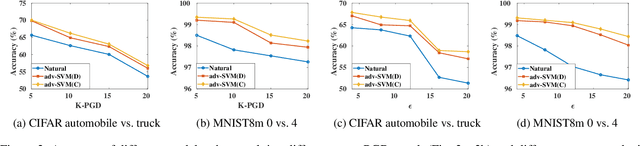

Adversarial attacks by generating examples which are almost indistinguishable from natural examples, pose a serious threat to learning models. Defending against adversarial attacks is a critical element for a reliable learning system. Support vector machine (SVM) is a classical yet still important learning algorithm even in the current deep learning era. Although a wide range of researches have been done in recent years to improve the adversarial robustness of learning models, but most of them are limited to deep neural networks (DNNs) and the work for kernel SVM is still vacant. In this paper, we aim at kernel SVM and propose adv-SVM to improve its adversarial robustness via adversarial training, which has been demonstrated to be the most promising defense techniques. To the best of our knowledge, this is the first work that devotes to the fast and scalable adversarial training of kernel SVM. Specifically, we first build connection of perturbations of samples between original and kernel spaces, and then give a reduced and equivalent formulation of adversarial training of kernel SVM based on the connection. Next, doubly stochastic gradients (DSG) based on two unbiased stochastic approximations (i.e., one is on training points and another is on random features) are applied to update the solution of our objective function. Finally, we prove that our algorithm optimized by DSG converges to the optimal solution at the rate of O(1/t) under the constant and diminishing stepsizes. Comprehensive experimental results show that our adversarial training algorithm enjoys robustness against various attacks and meanwhile has the similar efficiency and scalability with classical DSG algorithm.