 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Nonvolatile Switchable-polarity EPM Valve
Mar 25, 2026Scalable control of pneumatic and fluidic networks remains fundamentally constrained by architectures that require continuous power input, dense external control hardware, and fixed routing topologies. Current valve arrays rely on such continuous actuation and mechanically fixed routing, imposing substantial thermal and architectural overhead. Here, we introduce the Switchable-polarity ElectroPermanent Magnet (S-EPM), a fundamentally new bistable magnetic architecture that deterministically reverses its external magnetic polarity through transient electrical excitation. By reconfiguring internal flux pathways within a composite magnet assembly, the S-EPM establishes two stable, opposing magnetic configurations without requiring sustained power. We integrate this architecture into a compact pinch-valve to robustly control pneumatic and liquid media. This state-encoded magnetic control enables logic-embedded fluidic networks, including decoders, hierarchical distribution modules, and a nonvolatile six-port routing array. These systems provide address-based routing and programmable compositional control, offering features like individual port isolation that are impossible with standard mechanically coupled rotary valves. By embedding functionality in persistent magnetic states rather than continuous power or static plumbing, this work establishes a scalable foundation for digital fluidics and autonomous laboratory platforms.
FASTC: A Fast Attentional Framework for Semantic Traversability Classification Using Point Cloud
Jun 24, 2024



Producing traversability maps and understanding the surroundings are crucial prerequisites for autonomous navigation. In this paper, we address the problem of traversability assessment using point clouds. We propose a novel pillar feature extraction module that utilizes PointNet to capture features from point clouds organized in vertical volume and a 2D encoder-decoder structure to conduct traversability classification instead of the widely used 3D convolutions. This results in less computational cost while even better performance is achieved at the same time. We then propose a new spatio-temporal attention module to fuse multi-frame information, which can properly handle the varying density problem of LIDAR point clouds, and this makes our module able to assess distant areas more accurately. Comprehensive experimental results on augmented Semantic KITTI and RELLIS-3D datasets show that our method is able to achieve superior performance over existing approaches both quantitatively and quantitatively.
ANGO: A Next-Level Evaluation Benchmark For Generation-Oriented Language Models In Chinese Domain
Jan 10, 2024Recently, various Large Language Models (LLMs) evaluation datasets have emerged, but most of them have issues with distorted rankings and difficulty in model capabilities analysis. Addressing these concerns, this paper introduces ANGO, a Chinese multi-choice question evaluation benchmark. ANGO proposes \textit{Keypoint} categorization standard for the first time, each question in ANGO can correspond to multiple keypoints, effectively enhancing interpretability of evaluation results. Base on performance of real humans, we build a quantifiable question difficulty standard and divide ANGO questions into 9 difficulty levels, which provide more precise guidance for model training. To minimize data leakage impact and fully leverage ANGO's innovative features, we have engineered exclusive sampling strategies and a new evaluation framework that support swift testset iteration. Our experiments demonstrate that ANGO poses a stronger challenge to models and reveals more details in evaluation result compared to existing benchmarks.
An Understanding-Oriented Robust Machine Reading Comprehension Model
Jul 01, 2022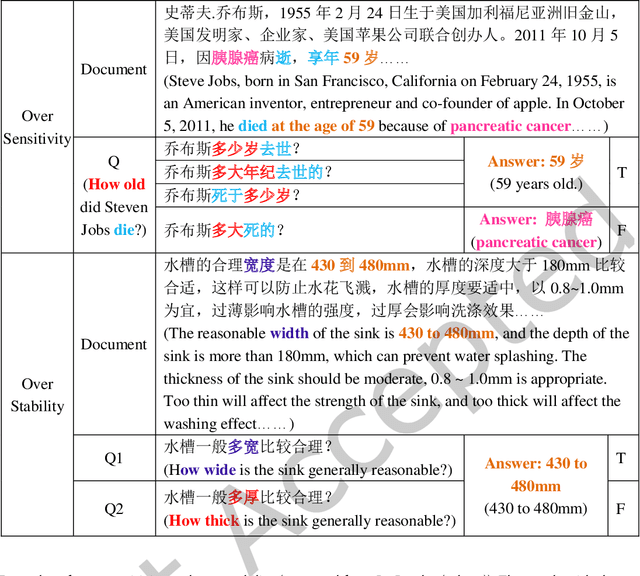
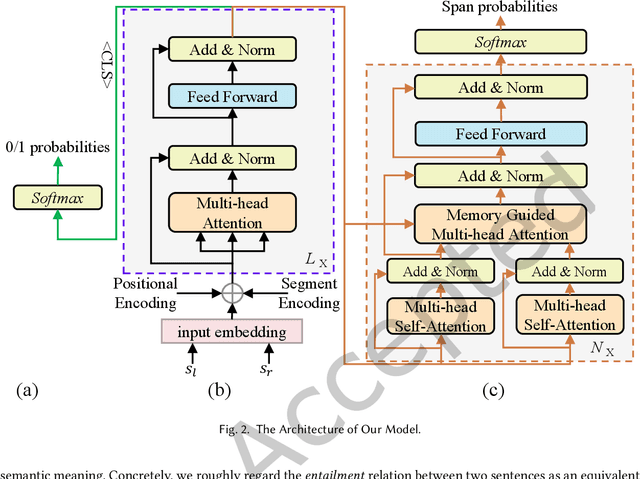
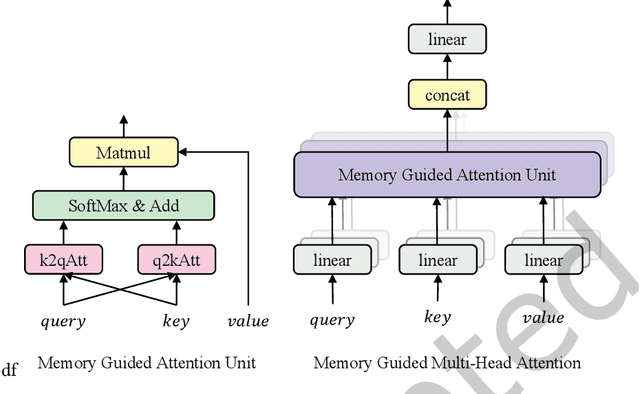
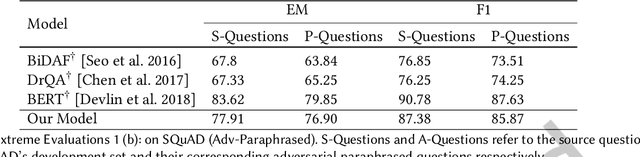
Although existing machine reading comprehension models are making rapid progress on many datasets, they are far from robust. In this paper, we propose an understanding-oriented machine reading comprehension model to address three kinds of robustness issues, which are over sensitivity, over stability and generalization. Specifically, we first use a natural language inference module to help the model understand the accurate semantic meanings of input questions so as to address the issues of over sensitivity and over stability. Then in the machine reading comprehension module, we propose a memory-guided multi-head attention method that can further well understand the semantic meanings of input questions and passages. Third, we propose a multilanguage learning mechanism to address the issue of generalization. Finally, these modules are integrated with a multi-task learning based method. We evaluate our model on three benchmark datasets that are designed to measure models robustness, including DuReader (robust) and two SQuAD-related datasets. Extensive experiments show that our model can well address the mentioned three kinds of robustness issues. And it achieves much better results than the compared state-of-the-art models on all these datasets under different evaluation metrics, even under some extreme and unfair evaluations. The source code of our work is available at: https://github.com/neukg/RobustMRC.
Deep Understanding based Multi-Document Machine Reading Comprehension
Feb 25, 2022
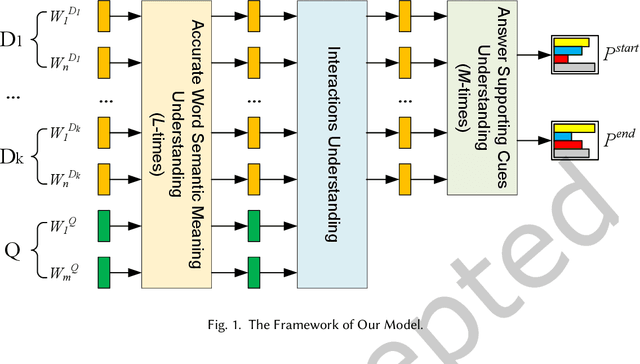
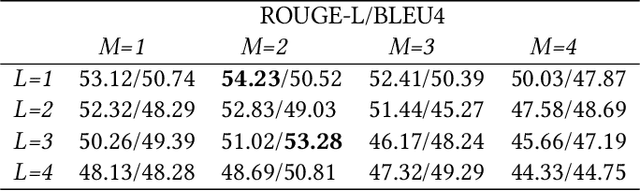
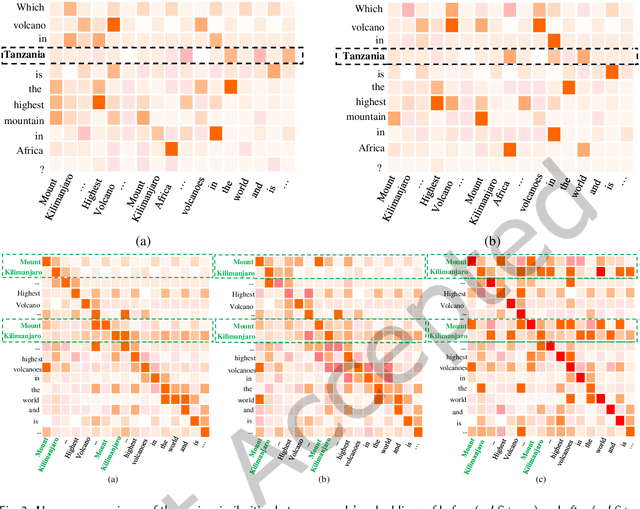
Most existing multi-document machine reading comprehension models mainly focus on understanding the interactions between the input question and documents, but ignore following two kinds of understandings. First, to understand the semantic meaning of words in the input question and documents from the perspective of each other. Second, to understand the supporting cues for a correct answer from the perspective of intra-document and inter-documents. Ignoring these two kinds of important understandings would make the models oversee some important information that may be helpful for inding correct answers. To overcome this deiciency, we propose a deep understanding based model for multi-document machine reading comprehension. It has three cascaded deep understanding modules which are designed to understand the accurate semantic meaning of words, the interactions between the input question and documents, and the supporting cues for the correct answer. We evaluate our model on two large scale benchmark datasets, namely TriviaQA Web and DuReader. Extensive experiments show that our model achieves state-of-the-art results on both datasets.