 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOctGPT: Octree-based Multiscale Autoregressive Models for 3D Shape Generation
Apr 15, 2025Autoregressive models have achieved remarkable success across various domains, yet their performance in 3D shape generation lags significantly behind that of diffusion models. In this paper, we introduce OctGPT, a novel multiscale autoregressive model for 3D shape generation that dramatically improves the efficiency and performance of prior 3D autoregressive approaches, while rivaling or surpassing state-of-the-art diffusion models. Our method employs a serialized octree representation to efficiently capture the hierarchical and spatial structures of 3D shapes. Coarse geometry is encoded via octree structures, while fine-grained details are represented by binary tokens generated using a vector quantized variational autoencoder (VQVAE), transforming 3D shapes into compact multiscale binary sequences suitable for autoregressive prediction. To address the computational challenges of handling long sequences, we incorporate octree-based transformers enhanced with 3D rotary positional encodings, scale-specific embeddings, and token-parallel generation schemes. These innovations reduce training time by 13 folds and generation time by 69 folds, enabling the efficient training of high-resolution 3D shapes, e.g.,$1024^3$, on just four NVIDIA 4090 GPUs only within days. OctGPT showcases exceptional versatility across various tasks, including text-, sketch-, and image-conditioned generation, as well as scene-level synthesis involving multiple objects. Extensive experiments demonstrate that OctGPT accelerates convergence and improves generation quality over prior autoregressive methods, offering a new paradigm for high-quality, scalable 3D content creation. Our code and trained models are available at https://github.com/octree-nn/octgpt.
Joint Point Cloud Upsampling and Cleaning with Octree-based CNNs
Oct 22, 2024Recovering dense and uniformly distributed point clouds from sparse or noisy data remains a significant challenge. Recently, great progress has been made on these tasks, but usually at the cost of increasingly intricate modules or complicated network architectures, leading to long inference time and huge resource consumption. Instead, we embrace simplicity and present a simple yet efficient method for jointly upsampling and cleaning point clouds. Our method leverages an off-the-shelf octree-based 3D U-Net (OUNet) with minor modifications, enabling the upsampling and cleaning tasks within a single network. Our network directly processes each input point cloud as a whole instead of processing each point cloud patch as in previous works, which significantly eases the implementation and brings at least 47 times faster inference. Extensive experiments demonstrate that our method achieves state-of-the-art performances under huge efficiency advantages on a series of benchmarks. We expect our method to serve simple baselines and inspire researchers to rethink the method design on point cloud upsampling and cleaning.
Neural Laplacian Operator for 3D Point Clouds
Sep 10, 2024



The discrete Laplacian operator holds a crucial role in 3D geometry processing, yet it is still challenging to define it on point clouds. Previous works mainly focused on constructing a local triangulation around each point to approximate the underlying manifold for defining the Laplacian operator, which may not be robust or accurate. In contrast, we simply use the K-nearest neighbors (KNN) graph constructed from the input point cloud and learn the Laplacian operator on the KNN graph with graph neural networks (GNNs). However, the ground-truth Laplacian operator is defined on a manifold mesh with a different connectivity from the KNN graph and thus cannot be directly used for training. To train the GNN, we propose a novel training scheme by imitating the behavior of the ground-truth Laplacian operator on a set of probe functions so that the learned Laplacian operator behaves similarly to the ground-truth Laplacian operator. We train our network on a subset of ShapeNet and evaluate it across a variety of point clouds. Compared with previous methods, our method reduces the error by an order of magnitude and excels in handling sparse point clouds with thin structures or sharp features. Our method also demonstrates a strong generalization ability to unseen shapes. With our learned Laplacian operator, we further apply a series of Laplacian-based geometry processing algorithms directly to point clouds and achieve accurate results, enabling many exciting possibilities for geometry processing on point clouds. The code and trained models are available at https://github.com/IntelligentGeometry/NeLo.
OctFusion: Octree-based Diffusion Models for 3D Shape Generation
Aug 27, 2024



Diffusion models have emerged as a popular method for 3D generation. However, it is still challenging for diffusion models to efficiently generate diverse and high-quality 3D shapes. In this paper, we introduce OctFusion, which can generate 3D shapes with arbitrary resolutions in 2.5 seconds on a single Nvidia 4090 GPU, and the extracted meshes are guaranteed to be continuous and manifold. The key components of OctFusion are the octree-based latent representation and the accompanying diffusion models. The representation combines the benefits of both implicit neural representations and explicit spatial octrees and is learned with an octree-based variational autoencoder. The proposed diffusion model is a unified multi-scale U-Net that enables weights and computation sharing across different octree levels and avoids the complexity of widely used cascaded diffusion schemes. We verify the effectiveness of OctFusion on the ShapeNet and Objaverse datasets and achieve state-of-the-art performances on shape generation tasks. We demonstrate that OctFusion is extendable and flexible by generating high-quality color fields for textured mesh generation and high-quality 3D shapes conditioned on text prompts, sketches, or category labels. Our code and pre-trained models are available at \url{https://github.com/octree-nn/octfusion}.
SinMPI: Novel View Synthesis from a Single Image with Expanded Multiplane Images
Dec 18, 2023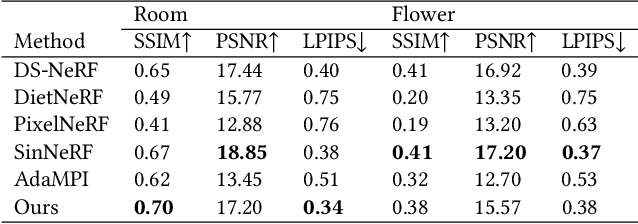
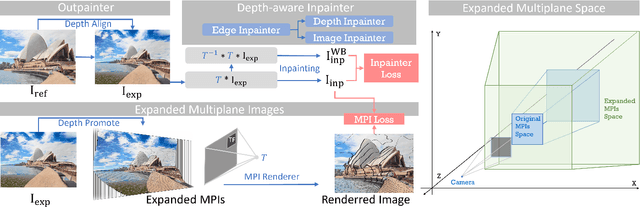
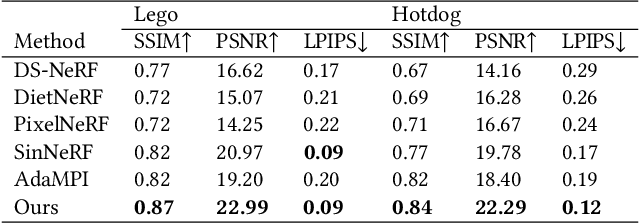
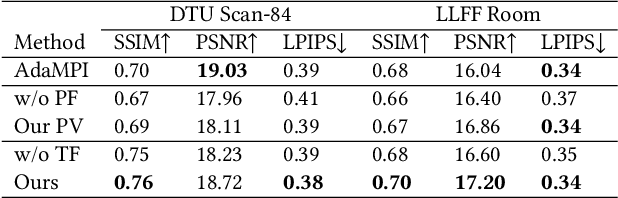
Single-image novel view synthesis is a challenging and ongoing problem that aims to generate an infinite number of consistent views from a single input image. Although significant efforts have been made to advance the quality of generated novel views, less attention has been paid to the expansion of the underlying scene representation, which is crucial to the generation of realistic novel view images. This paper proposes SinMPI, a novel method that uses an expanded multiplane image (MPI) as the 3D scene representation to significantly expand the perspective range of MPI and generate high-quality novel views from a large multiplane space. The key idea of our method is to use Stable Diffusion to generate out-of-view contents, project all scene contents into an expanded multiplane image according to depths predicted by monocular depth estimators, and then optimize the multiplane image under the supervision of pseudo multi-view data generated by a depth-aware warping and inpainting module. Both qualitative and quantitative experiments have been conducted to validate the superiority of our method to the state of the art. Our code and data are available at https://github.com/TrickyGo/SinMPI.
Point Transformer V3: Simpler, Faster, Stronger
Dec 15, 2023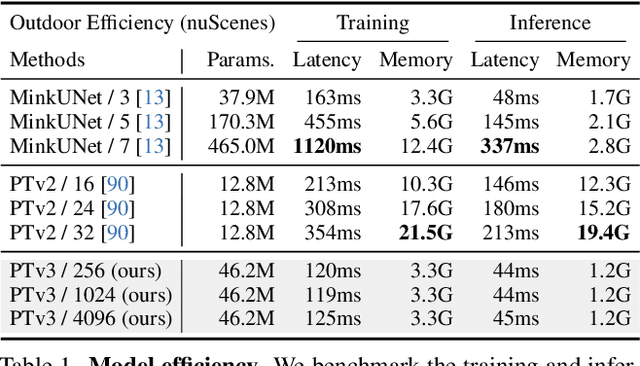


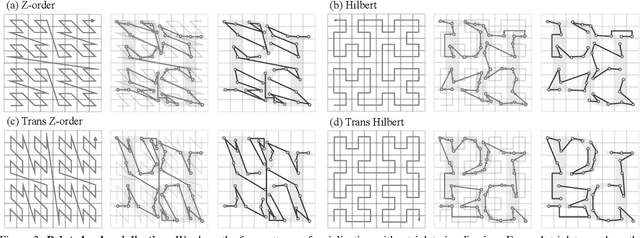
This paper is not motivated to seek innovation within the attention mechanism. Instead, it focuses on overcoming the existing trade-offs between accuracy and efficiency within the context of point cloud processing, leveraging the power of scale. Drawing inspiration from recent advances in 3D large-scale representation learning, we recognize that model performance is more influenced by scale than by intricate design. Therefore, we present Point Transformer V3 (PTv3), which prioritizes simplicity and efficiency over the accuracy of certain mechanisms that are minor to the overall performance after scaling, such as replacing the precise neighbor search by KNN with an efficient serialized neighbor mapping of point clouds organized with specific patterns. This principle enables significant scaling, expanding the receptive field from 16 to 1024 points while remaining efficient (a 3x increase in processing speed and a 10x improvement in memory efficiency compared with its predecessor, PTv2). PTv3 attains state-of-the-art results on over 20 downstream tasks that span both indoor and outdoor scenarios. Further enhanced with multi-dataset joint training, PTv3 pushes these results to a higher level.
Learning the Geodesic Embedding with Graph Neural Networks
Sep 11, 2023We present GeGnn, a learning-based method for computing the approximate geodesic distance between two arbitrary points on discrete polyhedra surfaces with constant time complexity after fast precomputation. Previous relevant methods either focus on computing the geodesic distance between a single source and all destinations, which has linear complexity at least or require a long precomputation time. Our key idea is to train a graph neural network to embed an input mesh into a high-dimensional embedding space and compute the geodesic distance between a pair of points using the corresponding embedding vectors and a lightweight decoding function. To facilitate the learning of the embedding, we propose novel graph convolution and graph pooling modules that incorporate local geodesic information and are verified to be much more effective than previous designs. After training, our method requires only one forward pass of the network per mesh as precomputation. Then, we can compute the geodesic distance between a pair of points using our decoding function, which requires only several matrix multiplications and can be massively parallelized on GPUs. We verify the efficiency and effectiveness of our method on ShapeNet and demonstrate that our method is faster than existing methods by orders of magnitude while achieving comparable or better accuracy. Additionally, our method exhibits robustness on noisy and incomplete meshes and strong generalization ability on out-of-distribution meshes. The code and pretrained model can be found on https://github.com/IntelligentGeometry/GeGnn.
Locally Attentional SDF Diffusion for Controllable 3D Shape Generation
May 09, 2023Although the recent rapid evolution of 3D generative neural networks greatly improves 3D shape generation, it is still not convenient for ordinary users to create 3D shapes and control the local geometry of generated shapes. To address these challenges, we propose a diffusion-based 3D generation framework -- locally attentional SDF diffusion, to model plausible 3D shapes, via 2D sketch image input. Our method is built on a two-stage diffusion model. The first stage, named occupancy-diffusion, aims to generate a low-resolution occupancy field to approximate the shape shell. The second stage, named SDF-diffusion, synthesizes a high-resolution signed distance field within the occupied voxels determined by the first stage to extract fine geometry. Our model is empowered by a novel view-aware local attention mechanism for image-conditioned shape generation, which takes advantage of 2D image patch features to guide 3D voxel feature learning, greatly improving local controllability and model generalizability. Through extensive experiments in sketch-conditioned and category-conditioned 3D shape generation tasks, we validate and demonstrate the ability of our method to provide plausible and diverse 3D shapes, as well as its superior controllability and generalizability over existing work. Our code and trained models are available at https://zhengxinyang.github.io/projects/LAS-Diffusion.html
* Accepted to SIGGRAPH 2023 (Journal version)
OctFormer: Octree-based Transformers for 3D Point Clouds
May 08, 2023We propose octree-based transformers, named OctFormer, for 3D point cloud learning. OctFormer can not only serve as a general and effective backbone for 3D point cloud segmentation and object detection but also have linear complexity and is scalable for large-scale point clouds. The key challenge in applying transformers to point clouds is reducing the quadratic, thus overwhelming, computation complexity of attentions. To combat this issue, several works divide point clouds into non-overlapping windows and constrain attentions in each local window. However, the point number in each window varies greatly, impeding the efficient execution on GPU. Observing that attentions are robust to the shapes of local windows, we propose a novel octree attention, which leverages sorted shuffled keys of octrees to partition point clouds into local windows containing a fixed number of points while permitting shapes of windows to change freely. And we also introduce dilated octree attention to expand the receptive field further. Our octree attention can be implemented in 10 lines of code with open-sourced libraries and runs 17 times faster than other point cloud attentions when the point number exceeds 200k. Built upon the octree attention, OctFormer can be easily scaled up and achieves state-of-the-art performances on a series of 3D segmentation and detection benchmarks, surpassing previous sparse-voxel-based CNNs and point cloud transformers in terms of both efficiency and effectiveness. Notably, on the challenging ScanNet200 dataset, OctFormer outperforms sparse-voxel-based CNNs by 7.3 in mIoU. Our code and trained models are available at https://wang-ps.github.io/octformer.
* SIGGRAPH 2023, Journal Track
Swin3D: A Pretrained Transformer Backbone for 3D Indoor Scene Understanding
Apr 24, 2023Pretrained backbones with fine-tuning have been widely adopted in 2D vision and natural language processing tasks and demonstrated significant advantages to task-specific networks. In this paper, we present a pretrained 3D backbone, named Swin3D, which first outperforms all state-of-the-art methods in downstream 3D indoor scene understanding tasks. Our backbone network is based on a 3D Swin transformer and carefully designed to efficiently conduct self-attention on sparse voxels with linear memory complexity and capture the irregularity of point signals via generalized contextual relative positional embedding. Based on this backbone design, we pretrained a large Swin3D model on a synthetic Structured3D dataset that is 10 times larger than the ScanNet dataset and fine-tuned the pretrained model in various downstream real-world indoor scene understanding tasks. The results demonstrate that our model pretrained on the synthetic dataset not only exhibits good generality in both downstream segmentation and detection on real 3D point datasets, but also surpasses the state-of-the-art methods on downstream tasks after fine-tuning with +2.3 mIoU and +2.2 mIoU on S3DIS Area5 and 6-fold semantic segmentation, +2.1 mIoU on ScanNet segmentation (val), +1.9 mAP@0.5 on ScanNet detection, +8.1 mAP@0.5 on S3DIS detection. Our method demonstrates the great potential of pretrained 3D backbones with fine-tuning for 3D understanding tasks. The code and models are available at https://github.com/microsoft/Swin3D .