 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint Transformer V3: Simpler, Faster, Stronger
Paper and Code
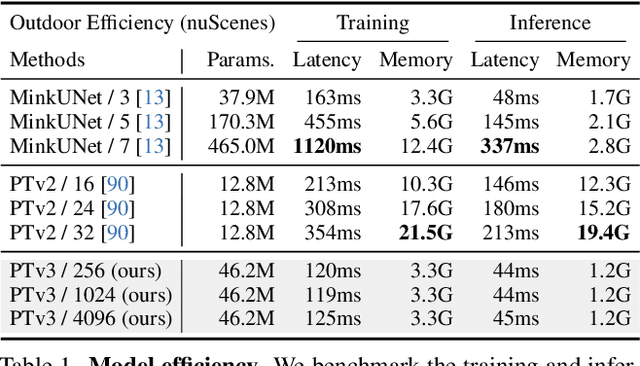


This paper is not motivated to seek innovation within the attention mechanism. Instead, it focuses on overcoming the existing trade-offs between accuracy and efficiency within the context of point cloud processing, leveraging the power of scale. Drawing inspiration from recent advances in 3D large-scale representation learning, we recognize that model performance is more influenced by scale than by intricate design. Therefore, we present Point Transformer V3 (PTv3), which prioritizes simplicity and efficiency over the accuracy of certain mechanisms that are minor to the overall performance after scaling, such as replacing the precise neighbor search by KNN with an efficient serialized neighbor mapping of point clouds organized with specific patterns. This principle enables significant scaling, expanding the receptive field from 16 to 1024 points while remaining efficient (a 3x increase in processing speed and a 10x improvement in memory efficiency compared with its predecessor, PTv2). PTv3 attains state-of-the-art results on over 20 downstream tasks that span both indoor and outdoor scenarios. Further enhanced with multi-dataset joint training, PTv3 pushes these results to a higher level.