 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOctFusion: Octree-based Diffusion Models for 3D Shape Generation
Aug 27, 2024



Diffusion models have emerged as a popular method for 3D generation. However, it is still challenging for diffusion models to efficiently generate diverse and high-quality 3D shapes. In this paper, we introduce OctFusion, which can generate 3D shapes with arbitrary resolutions in 2.5 seconds on a single Nvidia 4090 GPU, and the extracted meshes are guaranteed to be continuous and manifold. The key components of OctFusion are the octree-based latent representation and the accompanying diffusion models. The representation combines the benefits of both implicit neural representations and explicit spatial octrees and is learned with an octree-based variational autoencoder. The proposed diffusion model is a unified multi-scale U-Net that enables weights and computation sharing across different octree levels and avoids the complexity of widely used cascaded diffusion schemes. We verify the effectiveness of OctFusion on the ShapeNet and Objaverse datasets and achieve state-of-the-art performances on shape generation tasks. We demonstrate that OctFusion is extendable and flexible by generating high-quality color fields for textured mesh generation and high-quality 3D shapes conditioned on text prompts, sketches, or category labels. Our code and pre-trained models are available at \url{https://github.com/octree-nn/octfusion}.
MVD$^2$: Efficient Multiview 3D Reconstruction for Multiview Diffusion
Feb 22, 2024



As a promising 3D generation technique, multiview diffusion (MVD) has received a lot of attention due to its advantages in terms of generalizability, quality, and efficiency. By finetuning pretrained large image diffusion models with 3D data, the MVD methods first generate multiple views of a 3D object based on an image or text prompt and then reconstruct 3D shapes with multiview 3D reconstruction. However, the sparse views and inconsistent details in the generated images make 3D reconstruction challenging. We present MVD$^2$, an efficient 3D reconstruction method for multiview diffusion (MVD) images. MVD$^2$ aggregates image features into a 3D feature volume by projection and convolution and then decodes volumetric features into a 3D mesh. We train MVD$^2$ with 3D shape collections and MVD images prompted by rendered views of 3D shapes. To address the discrepancy between the generated multiview images and ground-truth views of the 3D shapes, we design a simple-yet-efficient view-dependent training scheme. MVD$^2$ improves the 3D generation quality of MVD and is fast and robust to various MVD methods. After training, it can efficiently decode 3D meshes from multiview images within one second. We train MVD$^2$ with Zero-123++ and ObjectVerse-LVIS 3D dataset and demonstrate its superior performance in generating 3D models from multiview images generated by different MVD methods, using both synthetic and real images as prompts.
Locally Attentional SDF Diffusion for Controllable 3D Shape Generation
May 09, 2023Although the recent rapid evolution of 3D generative neural networks greatly improves 3D shape generation, it is still not convenient for ordinary users to create 3D shapes and control the local geometry of generated shapes. To address these challenges, we propose a diffusion-based 3D generation framework -- locally attentional SDF diffusion, to model plausible 3D shapes, via 2D sketch image input. Our method is built on a two-stage diffusion model. The first stage, named occupancy-diffusion, aims to generate a low-resolution occupancy field to approximate the shape shell. The second stage, named SDF-diffusion, synthesizes a high-resolution signed distance field within the occupied voxels determined by the first stage to extract fine geometry. Our model is empowered by a novel view-aware local attention mechanism for image-conditioned shape generation, which takes advantage of 2D image patch features to guide 3D voxel feature learning, greatly improving local controllability and model generalizability. Through extensive experiments in sketch-conditioned and category-conditioned 3D shape generation tasks, we validate and demonstrate the ability of our method to provide plausible and diverse 3D shapes, as well as its superior controllability and generalizability over existing work. Our code and trained models are available at https://zhengxinyang.github.io/projects/LAS-Diffusion.html
* Accepted to SIGGRAPH 2023 (Journal version)
SDF-StyleGAN: Implicit SDF-Based StyleGAN for 3D Shape Generation
Jun 24, 2022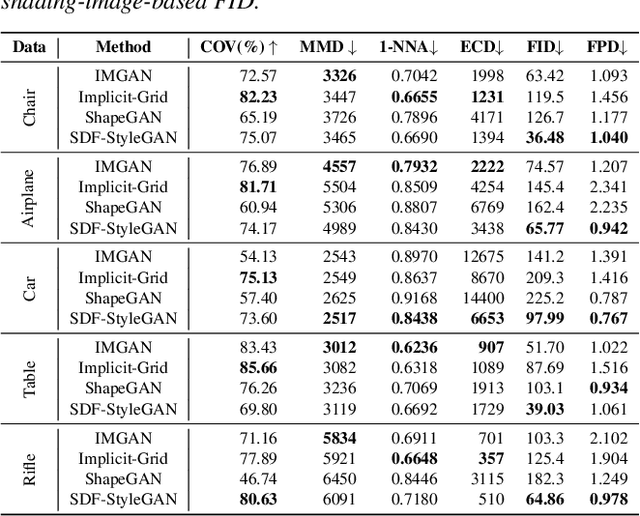

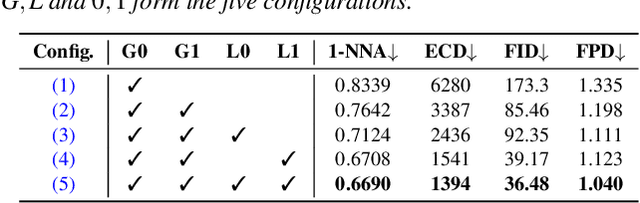
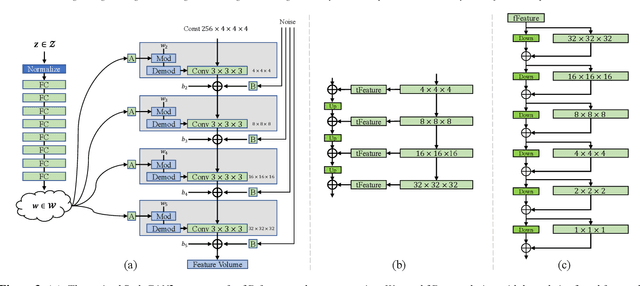
We present a StyleGAN2-based deep learning approach for 3D shape generation, called SDF-StyleGAN, with the aim of reducing visual and geometric dissimilarity between generated shapes and a shape collection. We extend StyleGAN2 to 3D generation and utilize the implicit signed distance function (SDF) as the 3D shape representation, and introduce two novel global and local shape discriminators that distinguish real and fake SDF values and gradients to significantly improve shape geometry and visual quality. We further complement the evaluation metrics of 3D generative models with the shading-image-based Fr\'echet inception distance (FID) scores to better assess visual quality and shape distribution of the generated shapes. Experiments on shape generation demonstrate the superior performance of SDF-StyleGAN over the state-of-the-art. We further demonstrate the efficacy of SDF-StyleGAN in various tasks based on GAN inversion, including shape reconstruction, shape completion from partial point clouds, single-view image-based shape generation, and shape style editing. Extensive ablation studies justify the efficacy of our framework design. Our code and trained models are available at https://github.com/Zhengxinyang/SDF-StyleGAN.