 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLPA3D: 3D Room-Level Scene Generation from In-the-Wild Images
Apr 03, 2025Generating realistic, room-level indoor scenes with semantically plausible and detailed appearances from in-the-wild images is crucial for various applications in VR, AR, and robotics. The success of NeRF-based generative methods indicates a promising direction to address this challenge. However, unlike their success at the object level, existing scene-level generative methods require additional information, such as multiple views, depth images, or semantic guidance, rather than relying solely on RGB images. This is because NeRF-based methods necessitate prior knowledge of camera poses, which is challenging to approximate for indoor scenes due to the complexity of defining alignment and the difficulty of globally estimating poses from a single image, given the unseen parts behind the camera. To address this challenge, we redefine global poses within the framework of Local-Pose-Alignment (LPA) -- an anchor-based multi-local-coordinate system that uses a selected number of anchors as the roots of these coordinates. Building on this foundation, we introduce LPA-GAN, a novel NeRF-based generative approach that incorporates specific modifications to estimate the priors of camera poses under LPA. It also co-optimizes the pose predictor and scene generation processes. Our ablation study and comparisons with straightforward extensions of NeRF-based object generative methods demonstrate the effectiveness of our approach. Furthermore, visual comparisons with other techniques reveal that our method achieves superior view-to-view consistency and semantic normality.
VASA-1: Lifelike Audio-Driven Talking Faces Generated in Real Time
Apr 16, 2024



We introduce VASA, a framework for generating lifelike talking faces with appealing visual affective skills (VAS) given a single static image and a speech audio clip. Our premiere model, VASA-1, is capable of not only producing lip movements that are exquisitely synchronized with the audio, but also capturing a large spectrum of facial nuances and natural head motions that contribute to the perception of authenticity and liveliness. The core innovations include a holistic facial dynamics and head movement generation model that works in a face latent space, and the development of such an expressive and disentangled face latent space using videos. Through extensive experiments including evaluation on a set of new metrics, we show that our method significantly outperforms previous methods along various dimensions comprehensively. Our method not only delivers high video quality with realistic facial and head dynamics but also supports the online generation of 512x512 videos at up to 40 FPS with negligible starting latency. It paves the way for real-time engagements with lifelike avatars that emulate human conversational behaviors.
MVD$^2$: Efficient Multiview 3D Reconstruction for Multiview Diffusion
Feb 22, 2024



As a promising 3D generation technique, multiview diffusion (MVD) has received a lot of attention due to its advantages in terms of generalizability, quality, and efficiency. By finetuning pretrained large image diffusion models with 3D data, the MVD methods first generate multiple views of a 3D object based on an image or text prompt and then reconstruct 3D shapes with multiview 3D reconstruction. However, the sparse views and inconsistent details in the generated images make 3D reconstruction challenging. We present MVD$^2$, an efficient 3D reconstruction method for multiview diffusion (MVD) images. MVD$^2$ aggregates image features into a 3D feature volume by projection and convolution and then decodes volumetric features into a 3D mesh. We train MVD$^2$ with 3D shape collections and MVD images prompted by rendered views of 3D shapes. To address the discrepancy between the generated multiview images and ground-truth views of the 3D shapes, we design a simple-yet-efficient view-dependent training scheme. MVD$^2$ improves the 3D generation quality of MVD and is fast and robust to various MVD methods. After training, it can efficiently decode 3D meshes from multiview images within one second. We train MVD$^2$ with Zero-123++ and ObjectVerse-LVIS 3D dataset and demonstrate its superior performance in generating 3D models from multiview images generated by different MVD methods, using both synthetic and real images as prompts.
Swin3D++: Effective Multi-Source Pretraining for 3D Indoor Scene Understanding
Feb 22, 2024



Data diversity and abundance are essential for improving the performance and generalization of models in natural language processing and 2D vision. However, 3D vision domain suffers from the lack of 3D data, and simply combining multiple 3D datasets for pretraining a 3D backbone does not yield significant improvement, due to the domain discrepancies among different 3D datasets that impede effective feature learning. In this work, we identify the main sources of the domain discrepancies between 3D indoor scene datasets, and propose Swin3D++, an enhanced architecture based on Swin3D for efficient pretraining on multi-source 3D point clouds. Swin3D++ introduces domain-specific mechanisms to Swin3D's modules to address domain discrepancies and enhance the network capability on multi-source pretraining. Moreover, we devise a simple source-augmentation strategy to increase the pretraining data scale and facilitate supervised pretraining. We validate the effectiveness of our design, and demonstrate that Swin3D++ surpasses the state-of-the-art 3D pretraining methods on typical indoor scene understanding tasks. Our code and models will be released at https://github.com/microsoft/Swin3D
Swin3D: A Pretrained Transformer Backbone for 3D Indoor Scene Understanding
Apr 24, 2023Pretrained backbones with fine-tuning have been widely adopted in 2D vision and natural language processing tasks and demonstrated significant advantages to task-specific networks. In this paper, we present a pretrained 3D backbone, named Swin3D, which first outperforms all state-of-the-art methods in downstream 3D indoor scene understanding tasks. Our backbone network is based on a 3D Swin transformer and carefully designed to efficiently conduct self-attention on sparse voxels with linear memory complexity and capture the irregularity of point signals via generalized contextual relative positional embedding. Based on this backbone design, we pretrained a large Swin3D model on a synthetic Structured3D dataset that is 10 times larger than the ScanNet dataset and fine-tuned the pretrained model in various downstream real-world indoor scene understanding tasks. The results demonstrate that our model pretrained on the synthetic dataset not only exhibits good generality in both downstream segmentation and detection on real 3D point datasets, but also surpasses the state-of-the-art methods on downstream tasks after fine-tuning with +2.3 mIoU and +2.2 mIoU on S3DIS Area5 and 6-fold semantic segmentation, +2.1 mIoU on ScanNet segmentation (val), +1.9 mAP@0.5 on ScanNet detection, +8.1 mAP@0.5 on S3DIS detection. Our method demonstrates the great potential of pretrained 3D backbones with fine-tuning for 3D understanding tasks. The code and models are available at https://github.com/microsoft/Swin3D .
Indoor Scene Generation from a Collection of Semantic-Segmented Depth Images
Aug 20, 2021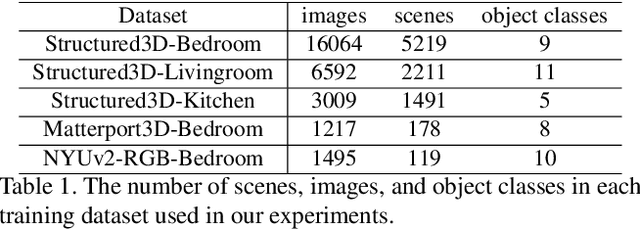
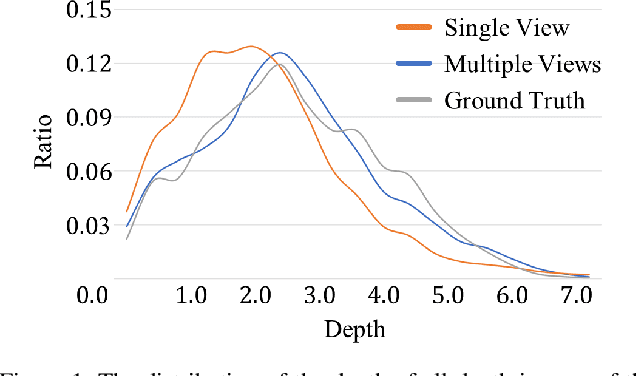
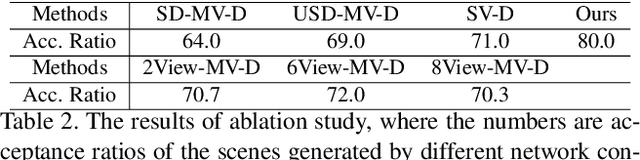
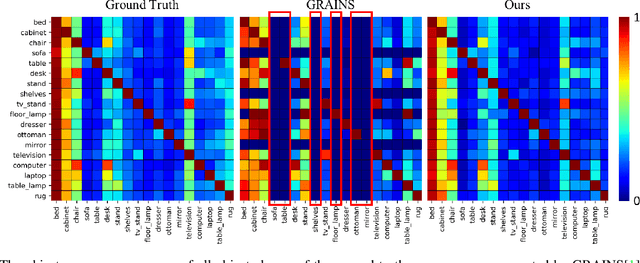
We present a method for creating 3D indoor scenes with a generative model learned from a collection of semantic-segmented depth images captured from different unknown scenes. Given a room with a specified size, our method automatically generates 3D objects in a room from a randomly sampled latent code. Different from existing methods that represent an indoor scene with the type, location, and other properties of objects in the room and learn the scene layout from a collection of complete 3D indoor scenes, our method models each indoor scene as a 3D semantic scene volume and learns a volumetric generative adversarial network (GAN) from a collection of 2.5D partial observations of 3D scenes. To this end, we apply a differentiable projection layer to project the generated 3D semantic scene volumes into semantic-segmented depth images and design a new multiple-view discriminator for learning the complete 3D scene volume from 2.5D semantic-segmented depth images. Compared to existing methods, our method not only efficiently reduces the workload of modeling and acquiring 3D scenes for training, but also produces better object shapes and their detailed layouts in the scene. We evaluate our method with different indoor scene datasets and demonstrate the advantages of our method. We also extend our method for generating 3D indoor scenes from semantic-segmented depth images inferred from RGB images of real scenes.
View-volume Network for Semantic Scene Completion from a Single Depth Image
Jun 14, 2018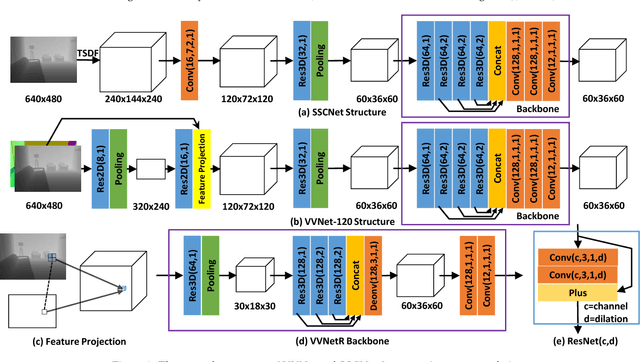
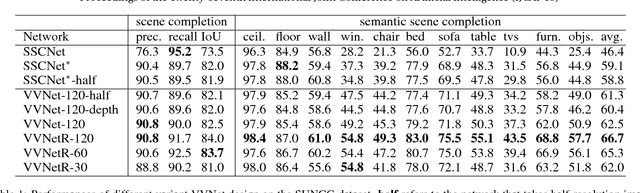
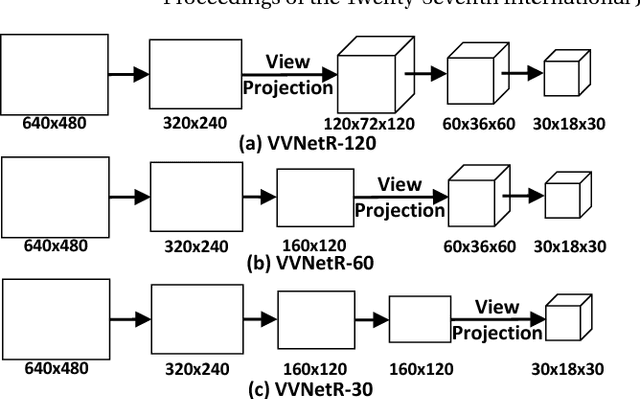
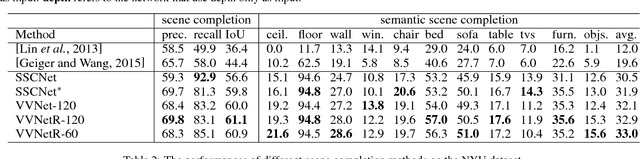
We introduce a View-Volume convolutional neural network (VVNet) for inferring the occupancy and semantic labels of a volumetric 3D scene from a single depth image. The VVNet concatenates a 2D view CNN and a 3D volume CNN with a differentiable projection layer. Given a single RGBD image, our method extracts the detailed geometric features from the input depth image with a 2D view CNN and then projects the features into a 3D volume according to the input depth map via a projection layer. After that, we learn the 3D context information of the scene with a 3D volume CNN for computing the result volumetric occupancy and semantic labels. With combined 2D and 3D representations, the VVNet efficiently reduces the computational cost, enables feature extraction from multi-channel high resolution inputs, and thus significantly improves the result accuracy. We validate our method and demonstrate its efficiency and effectiveness on both synthetic SUNCG and real NYU dataset.
O-CNN: Octree-based Convolutional Neural Networks for 3D Shape Analysis
Dec 05, 2017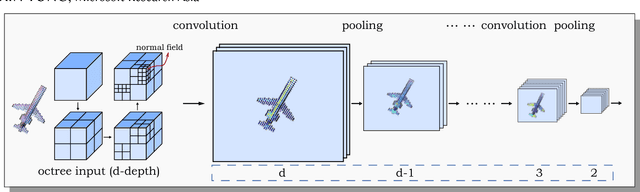
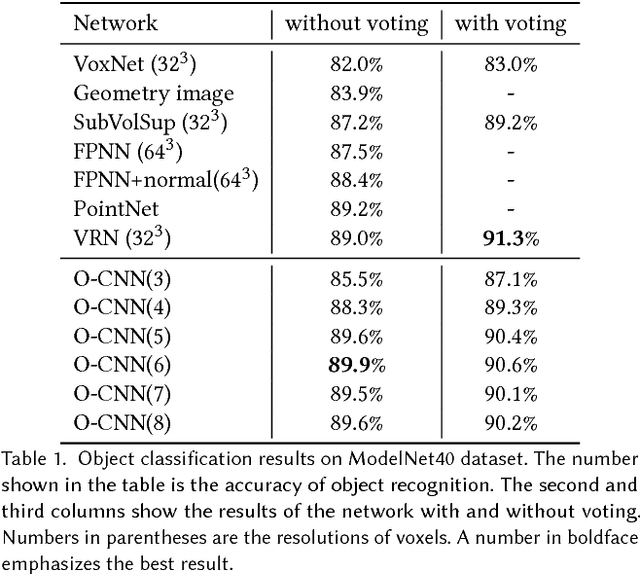
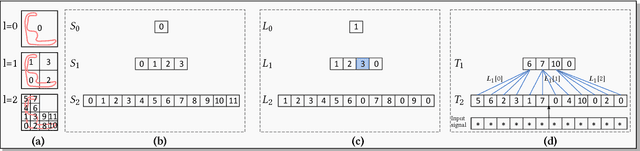
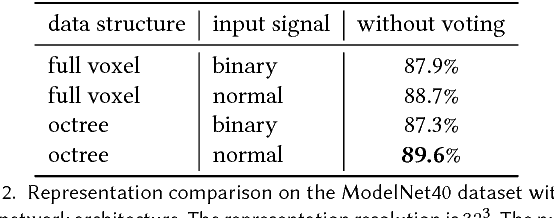
We present O-CNN, an Octree-based Convolutional Neural Network (CNN) for 3D shape analysis. Built upon the octree representation of 3D shapes, our method takes the average normal vectors of a 3D model sampled in the finest leaf octants as input and performs 3D CNN operations on the octants occupied by the 3D shape surface. We design a novel octree data structure to efficiently store the octant information and CNN features into the graphics memory and execute the entire O-CNN training and evaluation on the GPU. O-CNN supports various CNN structures and works for 3D shapes in different representations. By restraining the computations on the octants occupied by 3D surfaces, the memory and computational costs of the O-CNN grow quadratically as the depth of the octree increases, which makes the 3D CNN feasible for high-resolution 3D models. We compare the performance of the O-CNN with other existing 3D CNN solutions and demonstrate the efficiency and efficacy of O-CNN in three shape analysis tasks, including object classification, shape retrieval, and shape segmentation.