 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeView-volume Network for Semantic Scene Completion from a Single Depth Image
Paper and Code
Jun 14, 2018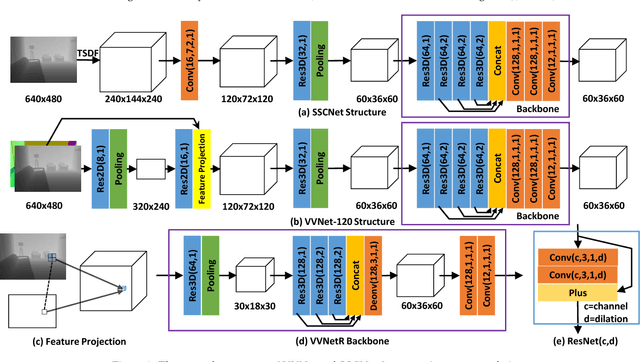
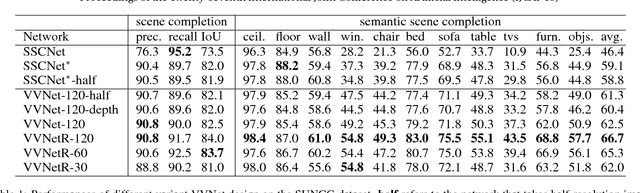
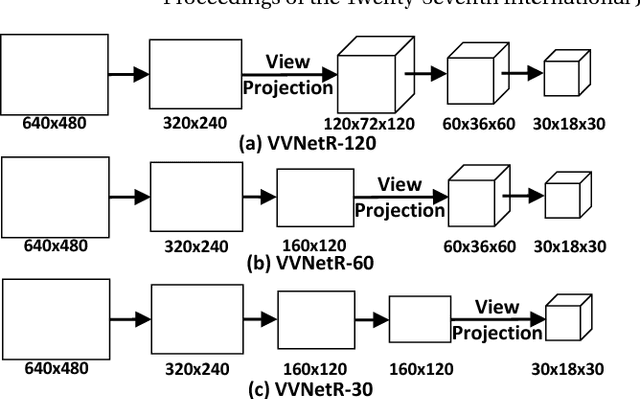
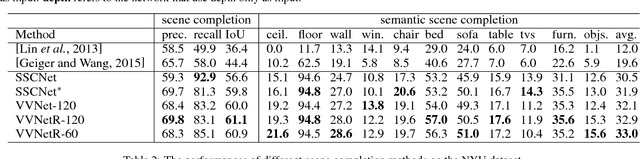
We introduce a View-Volume convolutional neural network (VVNet) for inferring the occupancy and semantic labels of a volumetric 3D scene from a single depth image. The VVNet concatenates a 2D view CNN and a 3D volume CNN with a differentiable projection layer. Given a single RGBD image, our method extracts the detailed geometric features from the input depth image with a 2D view CNN and then projects the features into a 3D volume according to the input depth map via a projection layer. After that, we learn the 3D context information of the scene with a 3D volume CNN for computing the result volumetric occupancy and semantic labels. With combined 2D and 3D representations, the VVNet efficiently reduces the computational cost, enables feature extraction from multi-channel high resolution inputs, and thus significantly improves the result accuracy. We validate our method and demonstrate its efficiency and effectiveness on both synthetic SUNCG and real NYU dataset.