 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLPA3D: 3D Room-Level Scene Generation from In-the-Wild Images
Apr 03, 2025Generating realistic, room-level indoor scenes with semantically plausible and detailed appearances from in-the-wild images is crucial for various applications in VR, AR, and robotics. The success of NeRF-based generative methods indicates a promising direction to address this challenge. However, unlike their success at the object level, existing scene-level generative methods require additional information, such as multiple views, depth images, or semantic guidance, rather than relying solely on RGB images. This is because NeRF-based methods necessitate prior knowledge of camera poses, which is challenging to approximate for indoor scenes due to the complexity of defining alignment and the difficulty of globally estimating poses from a single image, given the unseen parts behind the camera. To address this challenge, we redefine global poses within the framework of Local-Pose-Alignment (LPA) -- an anchor-based multi-local-coordinate system that uses a selected number of anchors as the roots of these coordinates. Building on this foundation, we introduce LPA-GAN, a novel NeRF-based generative approach that incorporates specific modifications to estimate the priors of camera poses under LPA. It also co-optimizes the pose predictor and scene generation processes. Our ablation study and comparisons with straightforward extensions of NeRF-based object generative methods demonstrate the effectiveness of our approach. Furthermore, visual comparisons with other techniques reveal that our method achieves superior view-to-view consistency and semantic normality.
Indoor Scene Generation from a Collection of Semantic-Segmented Depth Images
Aug 20, 2021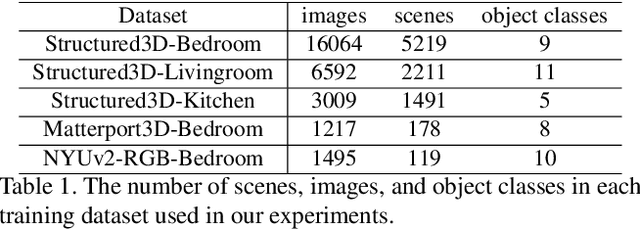
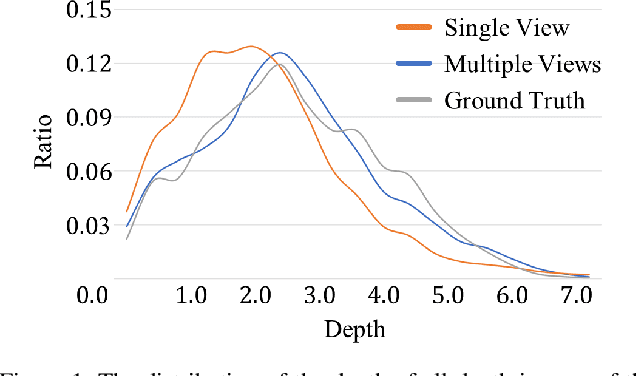
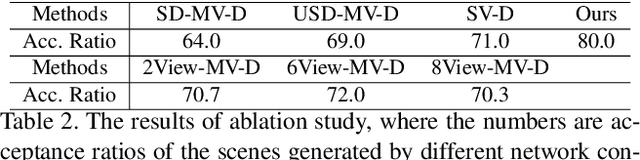
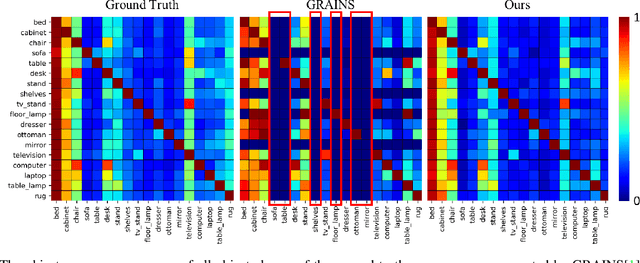
We present a method for creating 3D indoor scenes with a generative model learned from a collection of semantic-segmented depth images captured from different unknown scenes. Given a room with a specified size, our method automatically generates 3D objects in a room from a randomly sampled latent code. Different from existing methods that represent an indoor scene with the type, location, and other properties of objects in the room and learn the scene layout from a collection of complete 3D indoor scenes, our method models each indoor scene as a 3D semantic scene volume and learns a volumetric generative adversarial network (GAN) from a collection of 2.5D partial observations of 3D scenes. To this end, we apply a differentiable projection layer to project the generated 3D semantic scene volumes into semantic-segmented depth images and design a new multiple-view discriminator for learning the complete 3D scene volume from 2.5D semantic-segmented depth images. Compared to existing methods, our method not only efficiently reduces the workload of modeling and acquiring 3D scenes for training, but also produces better object shapes and their detailed layouts in the scene. We evaluate our method with different indoor scene datasets and demonstrate the advantages of our method. We also extend our method for generating 3D indoor scenes from semantic-segmented depth images inferred from RGB images of real scenes.