 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwin3D++: Effective Multi-Source Pretraining for 3D Indoor Scene Understanding
Feb 22, 2024



Data diversity and abundance are essential for improving the performance and generalization of models in natural language processing and 2D vision. However, 3D vision domain suffers from the lack of 3D data, and simply combining multiple 3D datasets for pretraining a 3D backbone does not yield significant improvement, due to the domain discrepancies among different 3D datasets that impede effective feature learning. In this work, we identify the main sources of the domain discrepancies between 3D indoor scene datasets, and propose Swin3D++, an enhanced architecture based on Swin3D for efficient pretraining on multi-source 3D point clouds. Swin3D++ introduces domain-specific mechanisms to Swin3D's modules to address domain discrepancies and enhance the network capability on multi-source pretraining. Moreover, we devise a simple source-augmentation strategy to increase the pretraining data scale and facilitate supervised pretraining. We validate the effectiveness of our design, and demonstrate that Swin3D++ surpasses the state-of-the-art 3D pretraining methods on typical indoor scene understanding tasks. Our code and models will be released at https://github.com/microsoft/Swin3D
Swin3D: A Pretrained Transformer Backbone for 3D Indoor Scene Understanding
Apr 24, 2023Pretrained backbones with fine-tuning have been widely adopted in 2D vision and natural language processing tasks and demonstrated significant advantages to task-specific networks. In this paper, we present a pretrained 3D backbone, named Swin3D, which first outperforms all state-of-the-art methods in downstream 3D indoor scene understanding tasks. Our backbone network is based on a 3D Swin transformer and carefully designed to efficiently conduct self-attention on sparse voxels with linear memory complexity and capture the irregularity of point signals via generalized contextual relative positional embedding. Based on this backbone design, we pretrained a large Swin3D model on a synthetic Structured3D dataset that is 10 times larger than the ScanNet dataset and fine-tuned the pretrained model in various downstream real-world indoor scene understanding tasks. The results demonstrate that our model pretrained on the synthetic dataset not only exhibits good generality in both downstream segmentation and detection on real 3D point datasets, but also surpasses the state-of-the-art methods on downstream tasks after fine-tuning with +2.3 mIoU and +2.2 mIoU on S3DIS Area5 and 6-fold semantic segmentation, +2.1 mIoU on ScanNet segmentation (val), +1.9 mAP@0.5 on ScanNet detection, +8.1 mAP@0.5 on S3DIS detection. Our method demonstrates the great potential of pretrained 3D backbones with fine-tuning for 3D understanding tasks. The code and models are available at https://github.com/microsoft/Swin3D .
Semi-supervised 3D shape segmentation with multilevel consistency and part substitution
Apr 20, 2022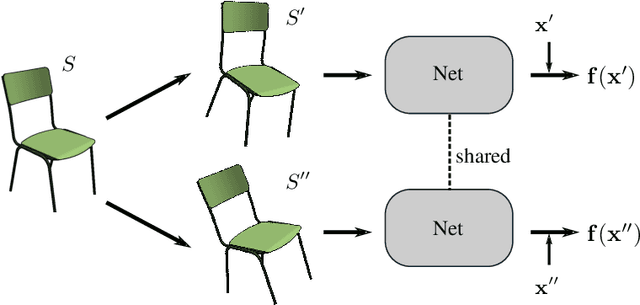
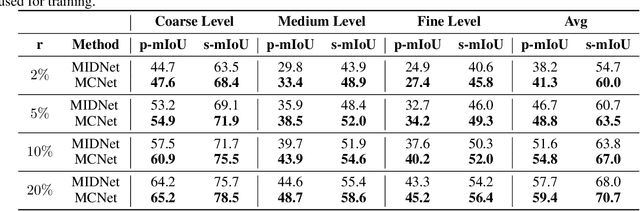
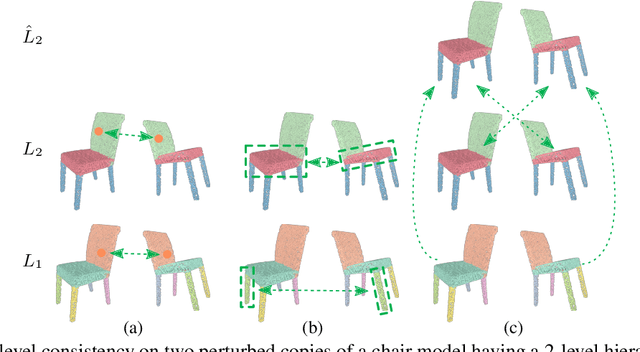
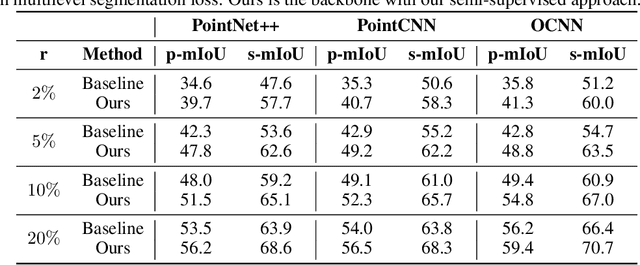
The lack of fine-grained 3D shape segmentation data is the main obstacle to developing learning-based 3D segmentation techniques. We propose an effective semi-supervised method for learning 3D segmentations from a few labeled 3D shapes and a large amount of unlabeled 3D data. For the unlabeled data, we present a novel multilevel consistency loss to enforce consistency of network predictions between perturbed copies of a 3D shape at multiple levels: point-level, part-level, and hierarchical level. For the labeled data, we develop a simple yet effective part substitution scheme to augment the labeled 3D shapes with more structural variations to enhance training. Our method has been extensively validated on the task of 3D object semantic segmentation on PartNet and ShapeNetPart, and indoor scene semantic segmentation on ScanNet. It exhibits superior performance to existing semi-supervised and unsupervised pre-training 3D approaches. Our code and trained models are publicly available at https://github.com/isunchy/semi_supervised_3d_segmentation.
Interpolation-Aware Padding for 3D Sparse Convolutional Neural Networks
Aug 16, 2021



Sparse voxel-based 3D convolutional neural networks (CNNs) are widely used for various 3D vision tasks. Sparse voxel-based 3D CNNs create sparse non-empty voxels from the 3D input and perform 3D convolution operations on them only. We propose a simple yet effective padding scheme --- interpolation-aware padding to pad a few empty voxels adjacent to the non-empty voxels and involve them in the 3D CNN computation so that all neighboring voxels exist when computing point-wise features via the trilinear interpolation. For fine-grained 3D vision tasks where point-wise features are essential, like semantic segmentation and 3D detection, our network achieves higher prediction accuracy than the existing networks using the nearest neighbor interpolation or the normalized trilinear interpolation with the zero-padding or the octree-padding scheme. Through extensive comparisons on various 3D segmentation and detection tasks, we demonstrate the superiority of 3D sparse CNNs with our padding scheme in conjunction with feature interpolation.
Spline Positional Encoding for Learning 3D Implicit Signed Distance Fields
Jun 03, 2021



Multilayer perceptrons (MLPs) have been successfully used to represent 3D shapes implicitly and compactly, by mapping 3D coordinates to the corresponding signed distance values or occupancy values. In this paper, we propose a novel positional encoding scheme, called Spline Positional Encoding, to map the input coordinates to a high dimensional space before passing them to MLPs, for helping to recover 3D signed distance fields with fine-scale geometric details from unorganized 3D point clouds. We verified the superiority of our approach over other positional encoding schemes on tasks of 3D shape reconstruction from input point clouds and shape space learning. The efficacy of our approach extended to image reconstruction is also demonstrated and evaluated.
Unsupervised 3D Learning for Shape Analysis via Multiresolution Instance Discrimination
Aug 03, 2020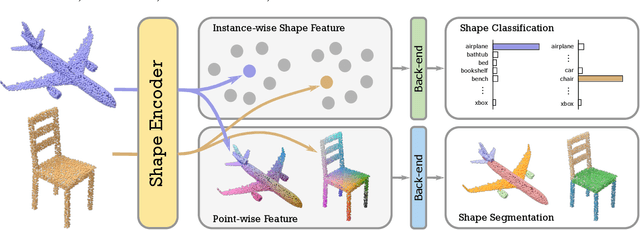
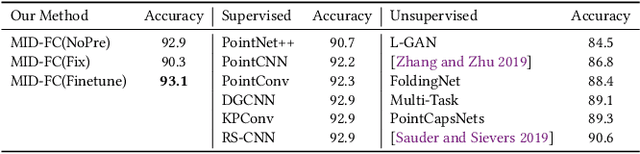
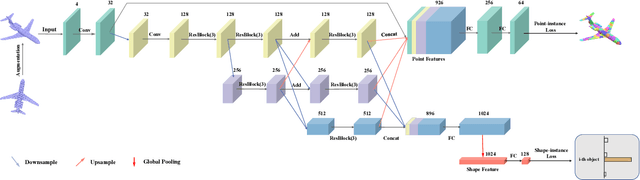

Although unsupervised feature learning has demonstrated its advantages to reducing the workload of data labeling and network design in many fields, existing unsupervised 3D learning methods still cannot offer a generic network for various shape analysis tasks with competitive performance to supervised methods. In this paper, we propose an unsupervised method for learning a generic and efficient shape encoding network for different shape analysis tasks. The key idea of our method is to jointly encode and learn shape and point features from unlabeled 3D point clouds. For this purpose, we adapt HR-Net to octree-based convolutional neural networks for jointly encoding shape and point features with fused multiresolution subnetworks and design a simple-yet-efficient \emph{Multiresolution Instance Discrimination} (MID) loss for jointly learning the shape and point features. Our network takes a 3D point cloud as input and output both shape and point features. After training, the network is concatenated with simple task-specific back-end layers and fine-tuned for different shape analysis tasks. We evaluate the efficacy and generality of our method and validate our network and loss design with a set of shape analysis tasks, including shape classification, semantic shape segmentation, as well as shape registration tasks. With simple back-ends, our network demonstrates the best performance among all unsupervised methods and achieves competitive performance to supervised methods, especially in tasks with a small labeled dataset. For fine-grained shape segmentation, our method even surpasses existing supervised methods by a large margin.