 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntrinsic Computational Functionalism and Simulated Consciousness
Jun 13, 2026A common objection to artificial or simulated consciousness is that a simulated brain is no more conscious than simulated water is wet. We address this from the perspective of Intrinsic Computational Functionalism (ICF): if consciousness is computationally constituted, it depends not on externally imposed descriptions but on the computational structures a system physically realizes in virtue of its own causal-dynamical organization. In previous work we developed Canonical Functionalism as a mathematically precise special case of this anti-interpretivist program, identifying functional states by their complete future input-output roles under a fixed interface. Here we argue that this input-output construction, though important, is incomplete: as a behavioral boundary case of ICF, it makes lookup tables and unfolded systems that preserve the same boundary behavior canonically equivalent. A consciousness-relevant canonical representation must instead include internal mechanisms, interventions, and joint readouts belonging to the relevant intrinsic organization. We therefore define a mechanism-enriched canonical structure and use it to formulate Intrinsic Causal-Computational Realization (ICCR), a realization relation preserving physical implementation, intrinsic state individuation, transition structure, intervention profiles, and the relevant agent-body-world boundary. The central result is conditional: if conscious properties are invariants of intrinsic causal-computational organization, then any system satisfying ICCR realizes the same consciousness-relevant properties, whether biological, artificial, or simulated. We discuss objections including biological naturalism and integrated information theory. We conclude that to deny consciousness to a simulation, one must identify a consciousness-relevant intrinsic causal-computational structure that the simulation fails to realize.
Decoding Vision Transformers: the Diffusion Steering Lens
Apr 18, 2025



Logit Lens is a widely adopted method for mechanistic interpretability of transformer-based language models, enabling the analysis of how internal representations evolve across layers by projecting them into the output vocabulary space. Although applying Logit Lens to Vision Transformers (ViTs) is technically straightforward, its direct use faces limitations in capturing the richness of visual representations. Building on the work of Toker et al. (2024)~\cite{Toker2024-ve}, who introduced Diffusion Lens to visualize intermediate representations in the text encoders of text-to-image diffusion models, we demonstrate that while Diffusion Lens can effectively visualize residual stream representations in image encoders, it fails to capture the direct contributions of individual submodules. To overcome this limitation, we propose \textbf{Diffusion Steering Lens} (DSL), a novel, training-free approach that steers submodule outputs and patches subsequent indirect contributions. We validate our method through interventional studies, showing that DSL provides an intuitive and reliable interpretation of the internal processing in ViTs.
ProcBench: Benchmark for Multi-Step Reasoning and Following Procedure
Oct 04, 2024


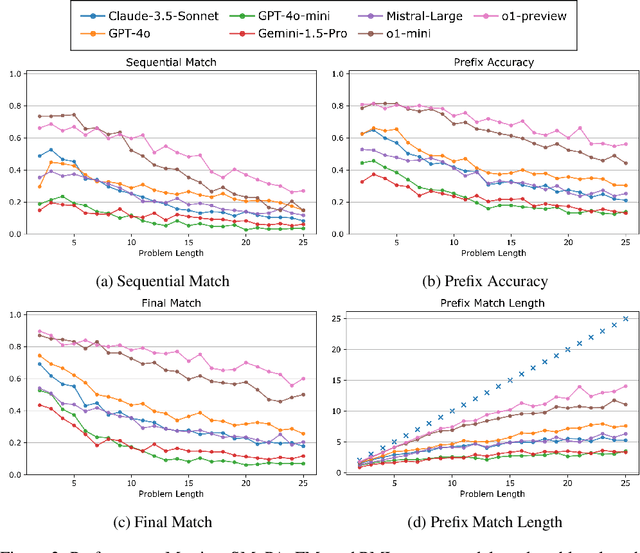
Reasoning is central to a wide range of intellectual activities, and while the capabilities of large language models (LLMs) continue to advance, their performance in reasoning tasks remains limited. The processes and mechanisms underlying reasoning are not yet fully understood, but key elements include path exploration, selection of relevant knowledge, and multi-step inference. Problems are solved through the synthesis of these components. In this paper, we propose a benchmark that focuses on a specific aspect of reasoning ability: the direct evaluation of multi-step inference. To this end, we design a special reasoning task where multi-step inference is specifically focused by largely eliminating path exploration and implicit knowledge utilization. Our dataset comprises pairs of explicit instructions and corresponding questions, where the procedures necessary for solving the questions are entirely detailed within the instructions. This setup allows models to solve problems solely by following the provided directives. By constructing problems that require varying numbers of steps to solve and evaluating responses at each step, we enable a thorough assessment of state-of-the-art LLMs' ability to follow instructions. To ensure the robustness of our evaluation, we include multiple distinct tasks. Furthermore, by comparing accuracy across tasks, utilizing step-aware metrics, and applying separately defined measures of complexity, we conduct experiments that offer insights into the capabilities and limitations of LLMs in reasoning tasks. Our findings have significant implications for the development of LLMs and highlight areas for future research in advancing their reasoning abilities. Our dataset is available at \url{https://huggingface.co/datasets/ifujisawa/procbench} and code at \url{https://github.com/ifujisawa/proc-bench}.
Scaling Law in Neural Data: Non-Invasive Speech Decoding with 175 Hours of EEG Data
Jul 10, 2024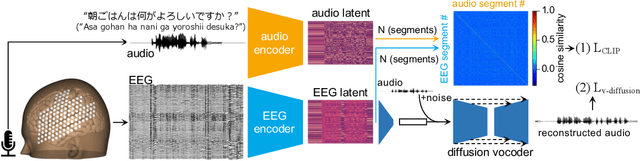

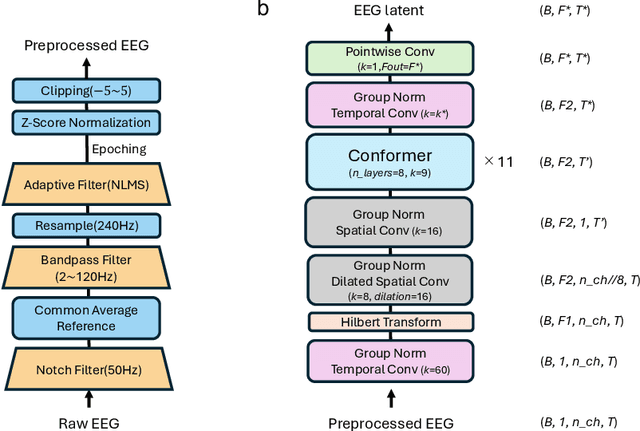

Brain-computer interfaces (BCIs) hold great potential for aiding individuals with speech impairments. Utilizing electroencephalography (EEG) to decode speech is particularly promising due to its non-invasive nature. However, recordings are typically short, and the high variability in EEG data has led researchers to focus on classification tasks with a few dozen classes. To assess its practical applicability for speech neuroprostheses, we investigate the relationship between the size of EEG data and decoding accuracy in the open vocabulary setting. We collected extensive EEG data from a single participant (175 hours) and conducted zero-shot speech segment classification using self-supervised representation learning. The model trained on the entire dataset achieved a top-1 accuracy of 48\% and a top-10 accuracy of 76\%, while mitigating the effects of myopotential artifacts. Conversely, when the data was limited to the typical amount used in practice ($\sim$10 hours), the top-1 accuracy dropped to 2.5\%, revealing a significant scaling effect. Additionally, as the amount of training data increased, the EEG latent representation progressively exhibited clearer temporal structures of spoken phrases. This indicates that the decoder can recognize speech segments in a data-driven manner without explicit measurements of word recognition. This research marks a significant step towards the practical realization of EEG-based speech BCIs.
Remembering Transformer for Continual Learning
Apr 11, 2024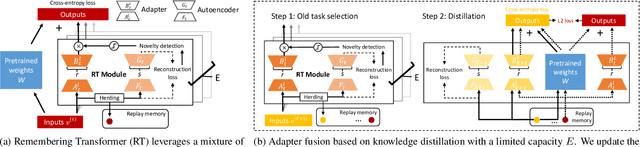
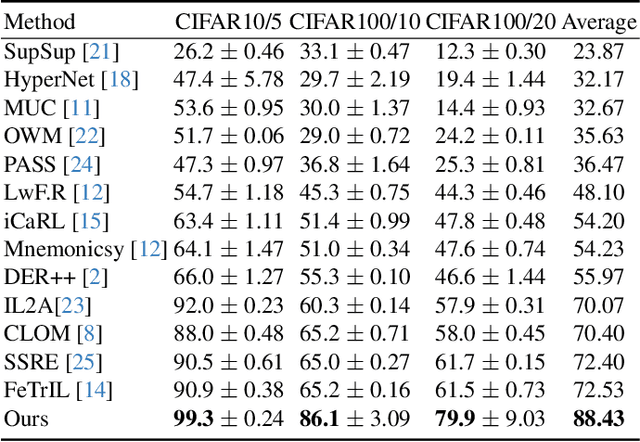
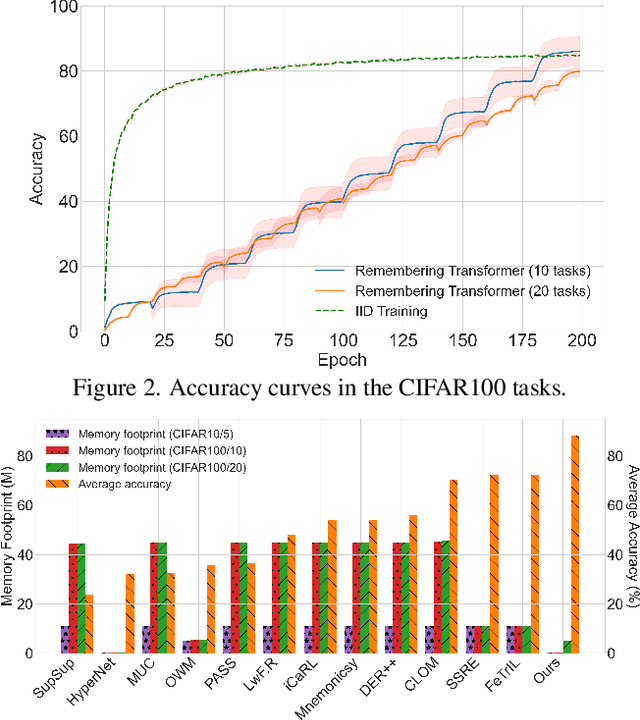

Neural networks encounter the challenge of Catastrophic Forgetting (CF) in continual learning, where new task knowledge interferes with previously learned knowledge. We propose Remembering Transformer, inspired by the brain's Complementary Learning Systems (CLS), to tackle this issue. Remembering Transformer employs a mixture-of-adapters and a generative model-based routing mechanism to alleviate CF by dynamically routing task data to relevant adapters. Our approach demonstrated a new SOTA performance in various vision continual learning tasks and great parameter efficiency.
Associative Transformer Is A Sparse Representation Learner
Sep 22, 2023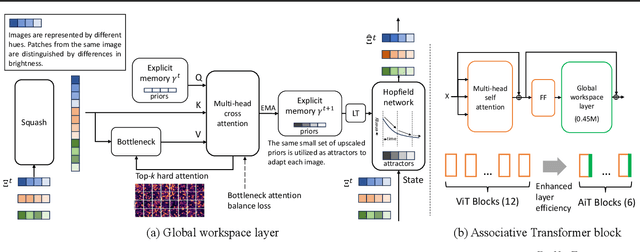
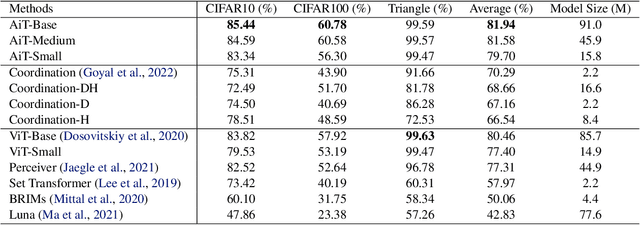
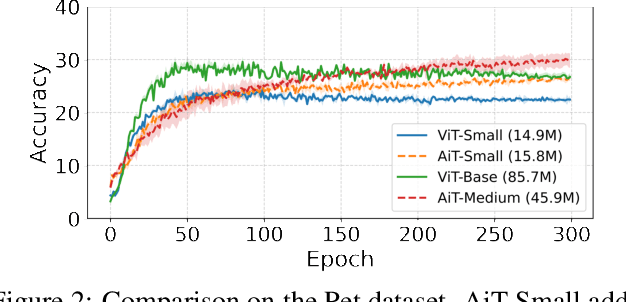
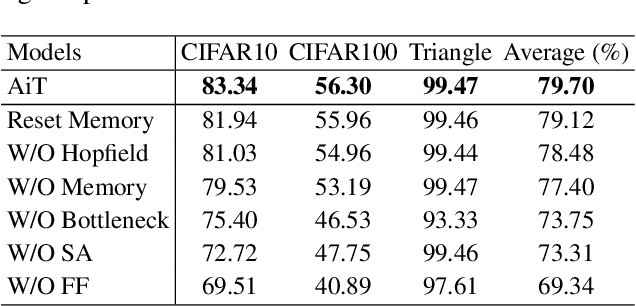
Emerging from the monolithic pairwise attention mechanism in conventional Transformer models, there is a growing interest in leveraging sparse interactions that align more closely with biological principles. Approaches including the Set Transformer and the Perceiver employ cross-attention consolidated with a latent space that forms an attention bottleneck with limited capacity. Building upon recent neuroscience studies of Global Workspace Theory and associative memory, we propose the Associative Transformer (AiT). AiT induces low-rank explicit memory that serves as both priors to guide bottleneck attention in the shared workspace and attractors within associative memory of a Hopfield network. Through joint end-to-end training, these priors naturally develop module specialization, each contributing a distinct inductive bias to form attention bottlenecks. A bottleneck can foster competition among inputs for writing information into the memory. We show that AiT is a sparse representation learner, learning distinct priors through the bottlenecks that are complexity-invariant to input quantities and dimensions. AiT demonstrates its superiority over methods such as the Set Transformer, Vision Transformer, and Coordination in various vision tasks.
Consciousness in Artificial Intelligence: Insights from the Science of Consciousness
Aug 22, 2023
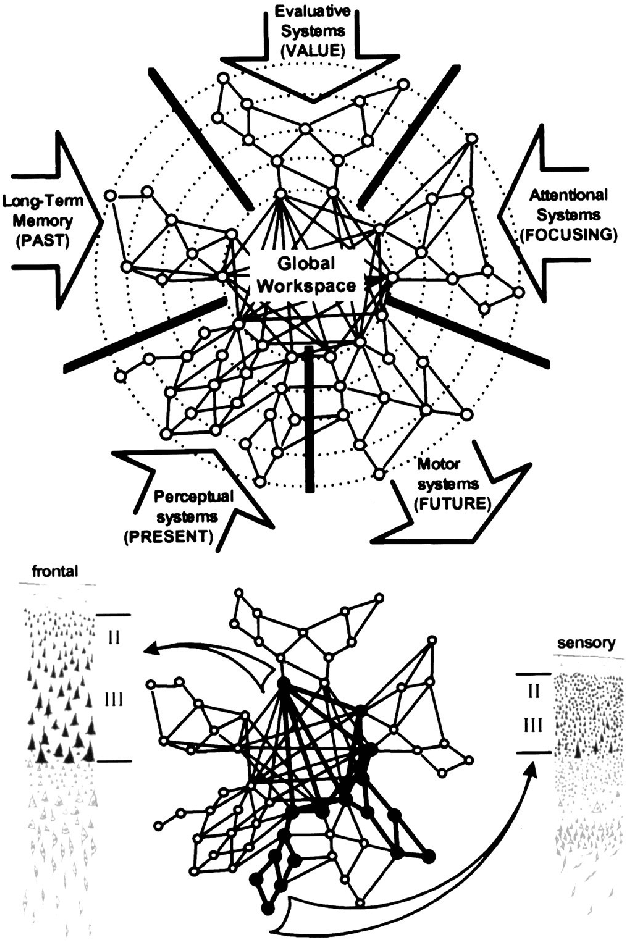

Whether current or near-term AI systems could be conscious is a topic of scientific interest and increasing public concern. This report argues for, and exemplifies, a rigorous and empirically grounded approach to AI consciousness: assessing existing AI systems in detail, in light of our best-supported neuroscientific theories of consciousness. We survey several prominent scientific theories of consciousness, including recurrent processing theory, global workspace theory, higher-order theories, predictive processing, and attention schema theory. From these theories we derive "indicator properties" of consciousness, elucidated in computational terms that allow us to assess AI systems for these properties. We use these indicator properties to assess several recent AI systems, and we discuss how future systems might implement them. Our analysis suggests that no current AI systems are conscious, but also suggests that there are no obvious technical barriers to building AI systems which satisfy these indicators.
Logical Tasks for Measuring Extrapolation and Rule Comprehension
Nov 14, 2022



Logical reasoning is essential in a variety of human activities. A representative example of a logical task is mathematics. Recent large-scale models trained on large datasets have been successful in various fields, but their reasoning ability in arithmetic tasks is limited, which we reproduce experimentally. Here, we recast this limitation as not unique to mathematics but common to tasks that require logical operations. We then propose a new set of tasks, termed logical tasks, which will be the next challenge to address. This higher point of view helps the development of inductive biases that have broad impact beyond the solution of individual tasks. We define and characterize logical tasks and discuss system requirements for their solution. Furthermore, we discuss the relevance of logical tasks to concepts such as extrapolation, explainability, and inductive bias. Finally, we provide directions for solving logical tasks.
On the link between conscious function and general intelligence in humans and machines
Mar 24, 2022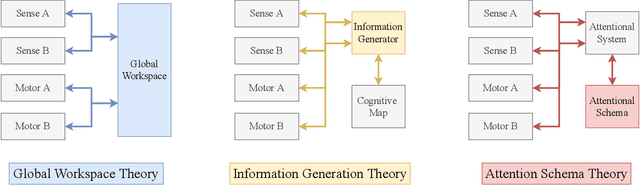
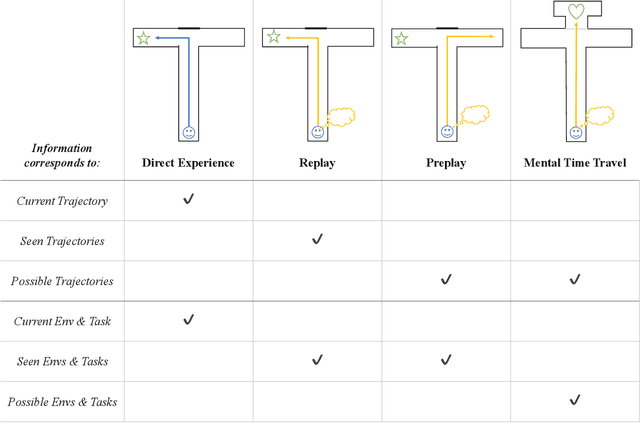
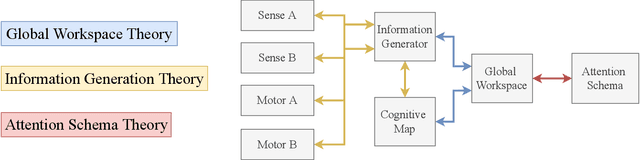
In popular media, there is often a connection drawn between the advent of awareness in artificial agents and those same agents simultaneously achieving human or superhuman level intelligence. In this work, we explore the validity and potential application of this seemingly intuitive link between consciousness and intelligence. We do so by examining the cognitive abilities associated with three contemporary theories of conscious function: Global Workspace Theory (GWT), Information Generation Theory (IGT), and Attention Schema Theory (AST). We find that all three theories specifically relate conscious function to some aspect of domain-general intelligence in humans. With this insight, we turn to the field of Artificial Intelligence (AI) and find that, while still far from demonstrating general intelligence, many state-of-the-art deep learning methods have begun to incorporate key aspects of each of the three functional theories. Given this apparent trend, we use the motivating example of mental time travel in humans to propose ways in which insights from each of the three theories may be combined into a unified model. We believe that doing so can enable the development of artificial agents which are not only more generally intelligent but are also consistent with multiple current theories of conscious function.
AI agents for facilitating social interactions and wellbeing
Feb 26, 2022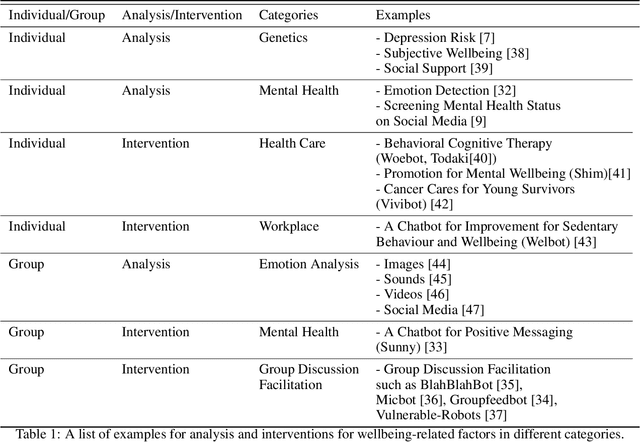
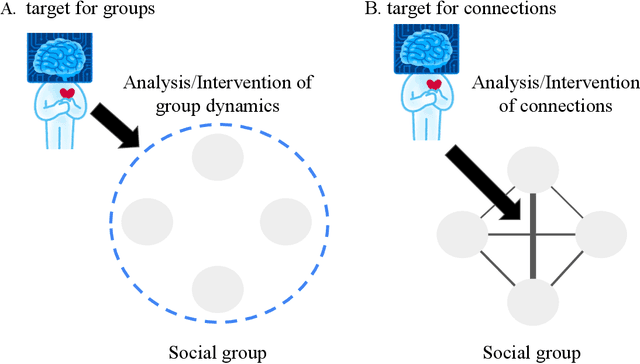
Wellbeing AI has been becoming a new trend in individuals' mental health, organizational health, and flourishing our societies. Various applications of wellbeing AI have been introduced to our daily lives. While social relationships within groups are a critical factor for wellbeing, the development of wellbeing AI for social interactions remains relatively scarce. In this paper, we provide an overview of the mediative role of AI-augmented agents for social interactions. First, we discuss the two-dimensional framework for classifying wellbeing AI: individual/group and analysis/intervention. Furthermore, wellbeing AI touches on intervening social relationships between human-human interactions since positive social relationships are key to human wellbeing. This intervention may raise technical and ethical challenges. We discuss opportunities and challenges of the relational approach with wellbeing AI to promote wellbeing in our societies.