 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetection of Global Anomalies on Distributed IoT Edges with Device-to-Device Communication
Jul 16, 2024



Anomaly detection is an important function in IoT applications for finding outliers caused by abnormal events. Anomaly detection sometimes comes with high-frequency data sampling which should be carried out at Edge devices rather than Cloud. In this paper, we consider the case that multiple IoT devices are installed in a single remote site and that they collaboratively detect anomalies from the observations with device-to-device communications. For this, we propose a fully distributed collaborative scheme for training distributed anomaly detectors with Wireless Ad Hoc Federated Learning, namely "WAFL-Autoencoder". We introduce the concept of Global Anomaly which sample is not only rare to the local device but rare to all the devices in the target domain. We also propose a distributed threshold-finding algorithm for Global Anomaly detection. With our standard benchmark-based evaluation, we have confirmed that our scheme trained anomaly detectors perfectly across the devices. We have also confirmed that the devices collaboratively found thresholds for Global Anomaly detection with low false positive rates while achieving high true positive rates with few exceptions.
Associative Transformer Is A Sparse Representation Learner
Sep 22, 2023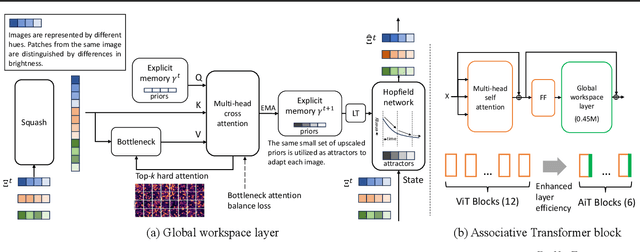
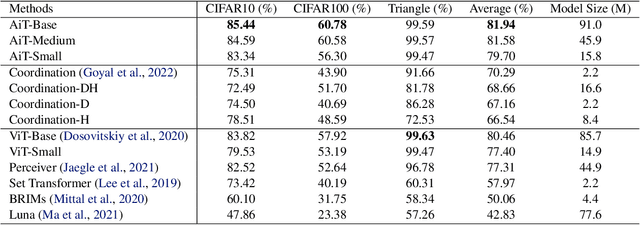
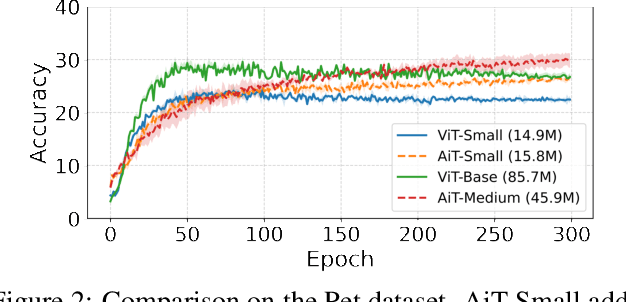
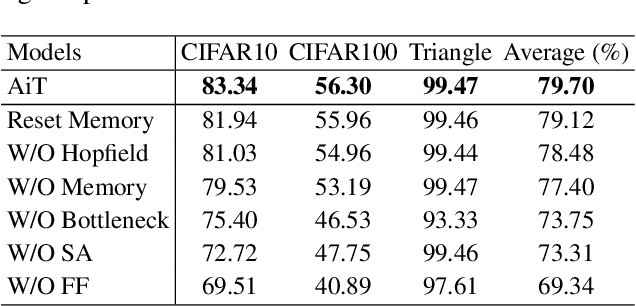
Emerging from the monolithic pairwise attention mechanism in conventional Transformer models, there is a growing interest in leveraging sparse interactions that align more closely with biological principles. Approaches including the Set Transformer and the Perceiver employ cross-attention consolidated with a latent space that forms an attention bottleneck with limited capacity. Building upon recent neuroscience studies of Global Workspace Theory and associative memory, we propose the Associative Transformer (AiT). AiT induces low-rank explicit memory that serves as both priors to guide bottleneck attention in the shared workspace and attractors within associative memory of a Hopfield network. Through joint end-to-end training, these priors naturally develop module specialization, each contributing a distinct inductive bias to form attention bottlenecks. A bottleneck can foster competition among inputs for writing information into the memory. We show that AiT is a sparse representation learner, learning distinct priors through the bottlenecks that are complexity-invariant to input quantities and dimensions. AiT demonstrates its superiority over methods such as the Set Transformer, Vision Transformer, and Coordination in various vision tasks.
Instance-level Trojan Attacks on Visual Question Answering via Adversarial Learning in Neuron Activation Space
Apr 02, 2023Malicious perturbations embedded in input data, known as Trojan attacks, can cause neural networks to misbehave. However, the impact of a Trojan attack is reduced during fine-tuning of the model, which involves transferring knowledge from a pretrained large-scale model like visual question answering (VQA) to the target model. To mitigate the effects of a Trojan attack, replacing and fine-tuning multiple layers of the pretrained model is possible. This research focuses on sample efficiency, stealthiness and variation, and robustness to model fine-tuning. To address these challenges, we propose an instance-level Trojan attack that generates diverse Trojans across input samples and modalities. Adversarial learning establishes a correlation between a specified perturbation layer and the misbehavior of the fine-tuned model. We conducted extensive experiments on the VQA-v2 dataset using a range of metrics. The results show that our proposed method can effectively adapt to a fine-tuned model with minimal samples. Specifically, we found that a model with a single fine-tuning layer can be compromised using a single shot of adversarial samples, while a model with more fine-tuning layers can be compromised using only a few shots.
Resilience of Wireless Ad Hoc Federated Learning against Model Poisoning Attacks
Nov 07, 2022Wireless ad hoc federated learning (WAFL) is a fully decentralized collaborative machine learning framework organized by opportunistically encountered mobile nodes. Compared to conventional federated learning, WAFL performs model training by weakly synchronizing the model parameters with others, and this shows great resilience to a poisoned model injected by an attacker. In this paper, we provide our theoretical analysis of the WAFL's resilience against model poisoning attacks, by formulating the force balance between the poisoned model and the legitimate model. According to our experiments, we confirmed that the nodes directly encountered the attacker has been somehow compromised to the poisoned model but other nodes have shown great resilience. More importantly, after the attacker has left the network, all the nodes have finally found stronger model parameters combined with the poisoned model. Most of the attack-experienced cases achieved higher accuracy than the no-attack-experienced cases.
UniCon: Unidirectional Split Learning with Contrastive Loss for Visual Question Answering
Aug 24, 2022

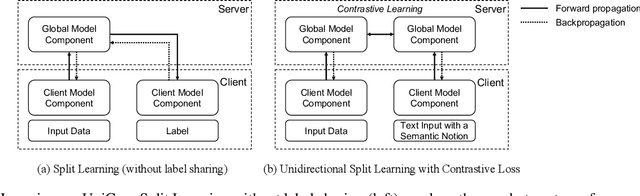
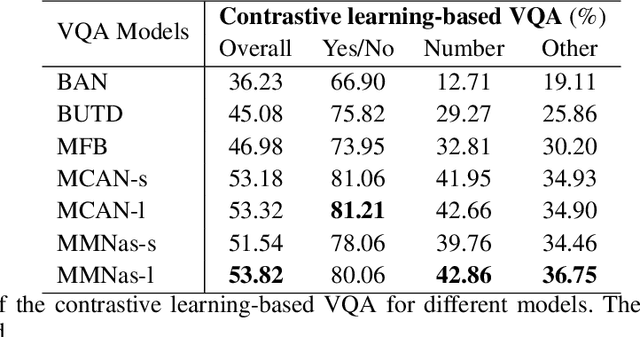
Visual question answering (VQA) that leverages multi-modality data has attracted intensive interest in real-life applications, such as home robots and clinic diagnoses. Nevertheless, one of the challenges is to design robust learning for different client tasks. This work aims to bridge the gap between the prerequisite of large-scale training data and the constraint of client data sharing mainly due to confidentiality. We propose the Unidirectional Split Learning with Contrastive Loss (UniCon) to tackle VQA tasks training on distributed data silos. In particular, UniCon trains a global model over the entire data distribution of different clients learning refined cross-modal representations via contrastive learning. The learned representations of the global model aggregate knowledge from different local tasks. Moreover, we devise a unidirectional split learning framework to enable more efficient knowledge sharing. The comprehensive experiments with five state-of-the-art VQA models on the VQA-v2 dataset demonstrated the efficacy of UniCon, achieving an accuracy of 49.89% in the validation set of VQA-v2. This work is the first study of VQA under the constraint of data confidentiality using self-supervised Split Learning.
Wireless Ad Hoc Federated Learning: A Fully Distributed Cooperative Machine Learning
May 24, 2022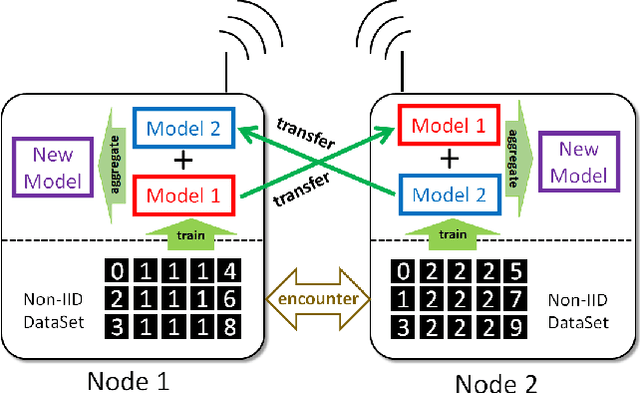
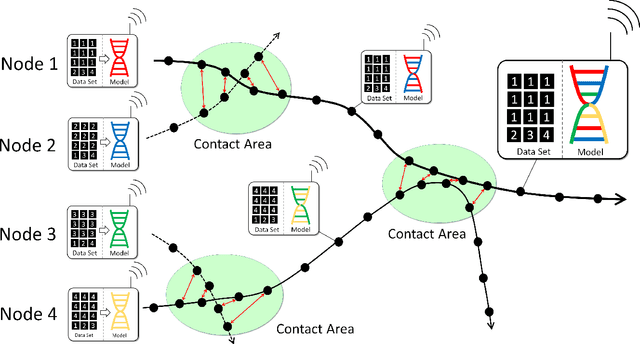
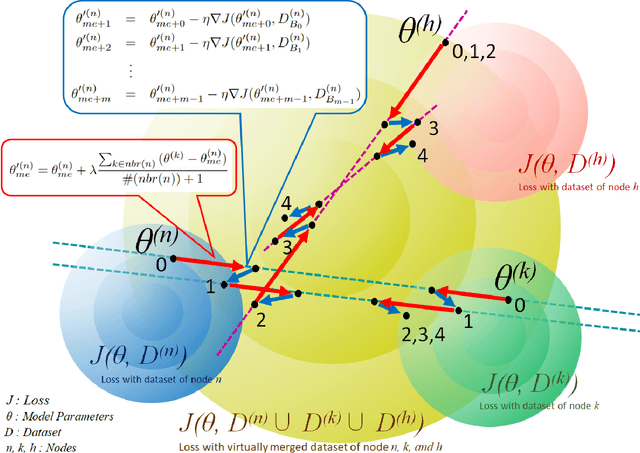
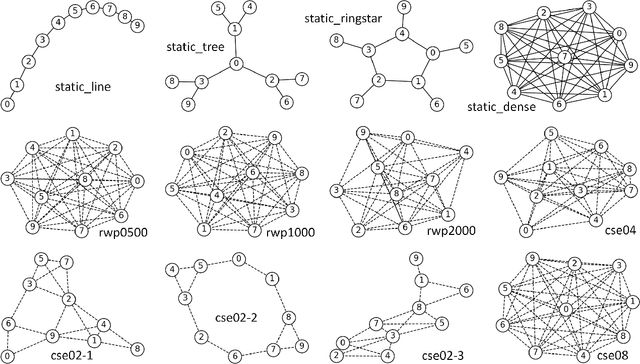
Federated learning has allowed training of a global model by aggregating local models trained on local nodes. However, it still takes client-server model, which can be further distributed, fully decentralized, or even partially connected, or totally opportunistic. In this paper, we propose a wireless ad hoc federated learning (WAFL) -- a fully distributed cooperative machine learning organized by the nodes physically nearby. Here, each node has a wireless interface and can communicate with each other when they are within the radio range. The nodes are expected to move with people, vehicles, or robots, producing opportunistic contacts with each other. In WAFL, each node trains a model individually with the local data it has. When a node encounter with others, they exchange their trained models, and generate new aggregated models, which are expected to be more general compared to the locally trained models on Non-IID data. For evaluation, we have prepared four static communication networks and two types of dynamic and opportunistic communication networks based on random waypoint mobility and community-structured environment, and then studied the training process of a fully connected neural network with 90% Non-IID MNIST dataset. The evaluation results indicate that WAFL allowed the convergence of model parameters among the nodes toward generalization, even with opportunistic node contact scenarios -- whereas in self-training (or lonely training) case, they have diverged. This WAFL's model generalization contributed to achieving higher accuracy 94.7-96.2% to the testing IID dataset compared to the self-training case 84.7%.
Semi-Targeted Model Poisoning Attack on Federated Learning via Backward Error Analysis
Mar 22, 2022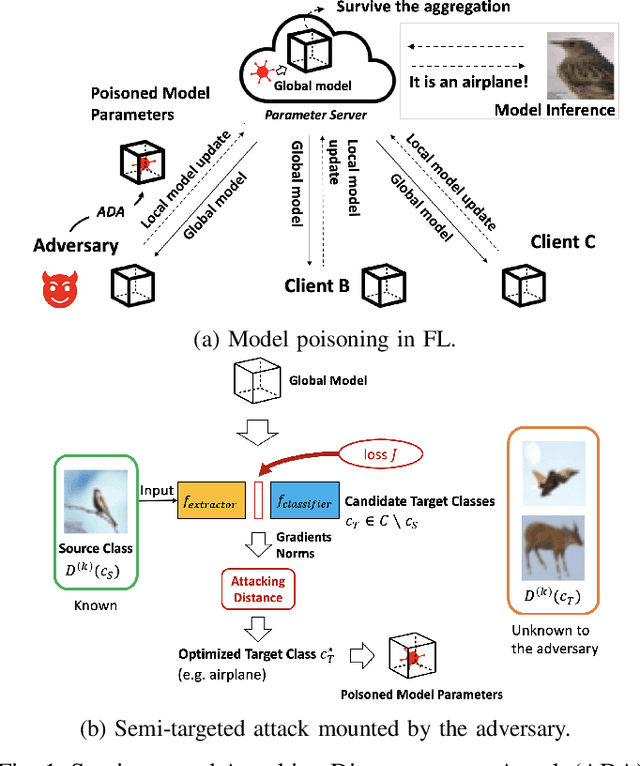
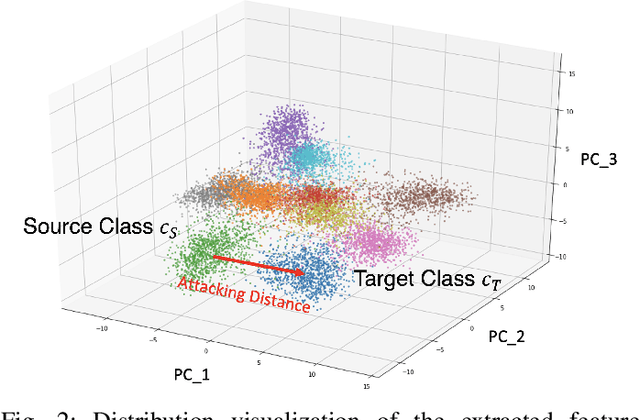
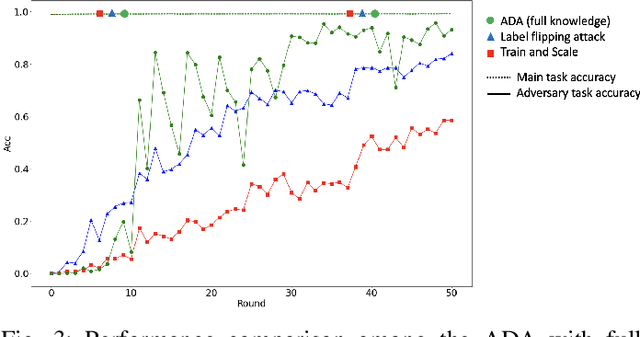
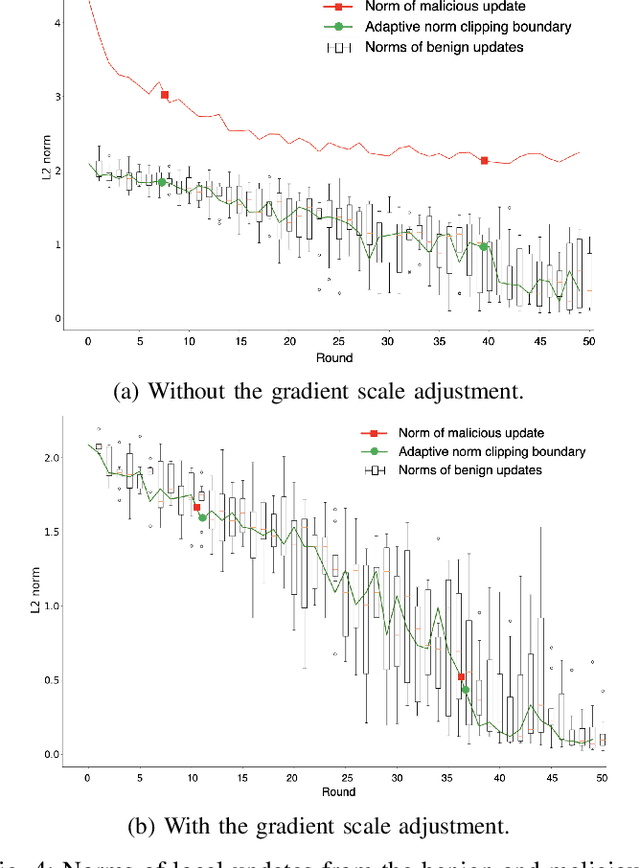
Model poisoning attacks on federated learning (FL) intrude in the entire system via compromising an edge model, resulting in malfunctioning of machine learning models. Such compromised models are tampered with to perform adversary-desired behaviors. In particular, we considered a semi-targeted situation where the source class is predetermined however the target class is not. The goal is to cause the global classifier to misclassify data of the source class. Though approaches such as label flipping have been adopted to inject poisoned parameters into FL, it has been shown that their performances are usually class-sensitive varying with different target classes applied. Typically, an attack can become less effective when shifting to a different target class. To overcome this challenge, we propose the Attacking Distance-aware Attack (ADA) to enhance a poisoning attack by finding the optimized target class in the feature space. Moreover, we studied a more challenging situation where an adversary had limited prior knowledge about a client's data. To tackle this problem, ADA deduces pair-wise distances between different classes in the latent feature space from shared model parameters based on the backward error analysis. We performed extensive empirical evaluations on ADA by varying the factor of attacking frequency in three different image classification tasks. As a result, ADA succeeded in increasing the attack performance by 1.8 times in the most challenging case with an attacking frequency of 0.01.
Privacy-Preserving Phishing Email Detection Based on Federated Learning and LSTM
Oct 12, 2021
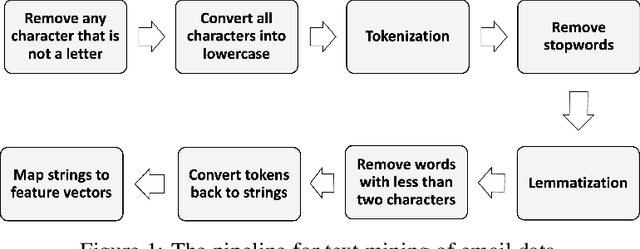
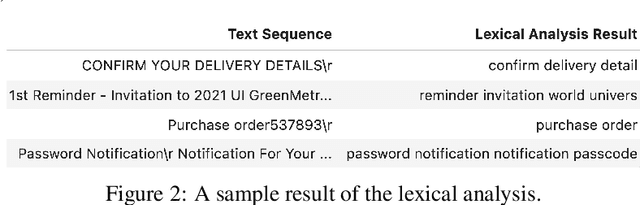
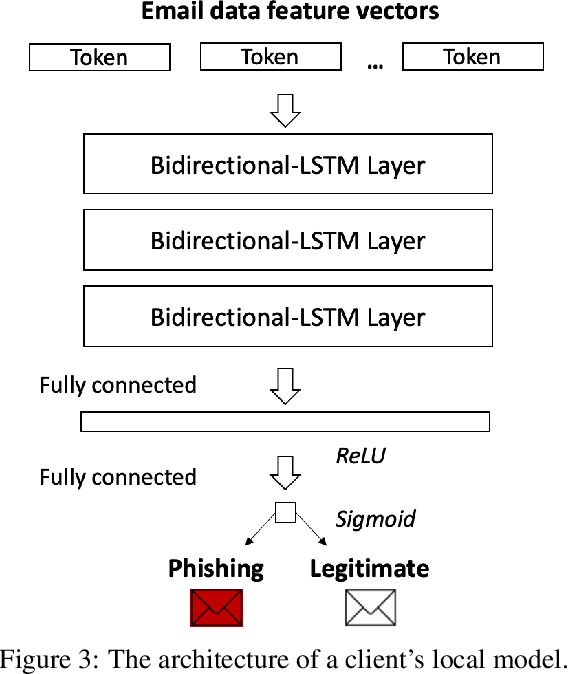
Phishing emails that appear legitimate lure people into clicking on the attached malicious links or documents. Increasingly more sophisticated phishing campaigns in recent years necessitate a more adaptive detection system other than traditional signature-based methods. In this regard, natural language processing (NLP) with deep neural networks (DNNs) is adopted for knowledge acquisition from a large number of emails. However, such sensitive daily communications containing personal information are difficult to collect on a server for centralized learning in real life due to escalating privacy concerns. To this end, we propose a decentralized phishing email detection method called the Federated Phish Bowl (FPB) leveraging federated learning and long short-term memory (LSTM). FPB allows common knowledge representation and sharing among different clients through the aggregation of trained models to safeguard the email security and privacy. A recent phishing email dataset was collected from an intergovernmental organization to train the model. Moreover, we evaluated the model performance based on various assumptions regarding the total client number and the level of data heterogeneity. The comprehensive experimental results suggest that FPB is robust to a continually increasing client number and various data heterogeneity levels, retaining a detection accuracy of 0.83 and protecting the privacy of sensitive email communications.
Homogeneous Learning: Self-Attention Decentralized Deep Learning
Oct 11, 2021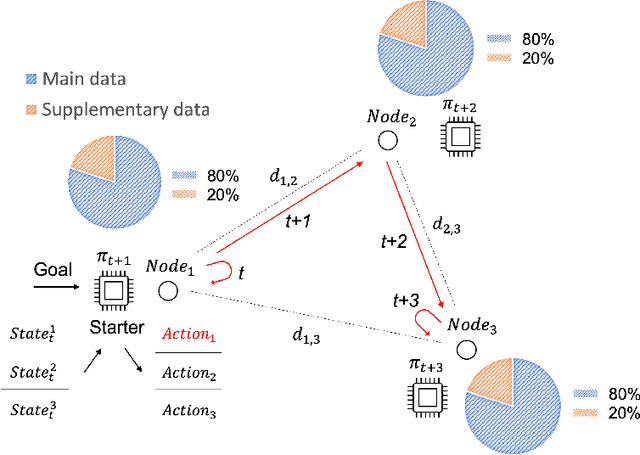


Federated learning (FL) has been facilitating privacy-preserving deep learning in many walks of life such as medical image classification, network intrusion detection, and so forth. Whereas it necessitates a central parameter server for model aggregation, which brings about delayed model communication and vulnerability to adversarial attacks. A fully decentralized architecture like Swarm Learning allows peer-to-peer communication among distributed nodes, without the central server. One of the most challenging issues in decentralized deep learning is that data owned by each node are usually non-independent and identically distributed (non-IID), causing time-consuming convergence of model training. To this end, we propose a decentralized learning model called Homogeneous Learning (HL) for tackling non-IID data with a self-attention mechanism. In HL, training performs on each round's selected node, and the trained model of a node is sent to the next selected node at the end of each round. Notably, for the selection, the self-attention mechanism leverages reinforcement learning to observe a node's inner state and its surrounding environment's state, and find out which node should be selected to optimize the training. We evaluate our method with various scenarios for an image classification task. The result suggests that HL can produce a better performance compared with standalone learning and greatly reduce both the total training rounds by 50.8% and the communication cost by 74.6% compared with random policy-based decentralized learning for training on non-IID data.
Roadside-assisted Cooperative Planning using Future Path Sharing for Autonomous Driving
Aug 10, 2021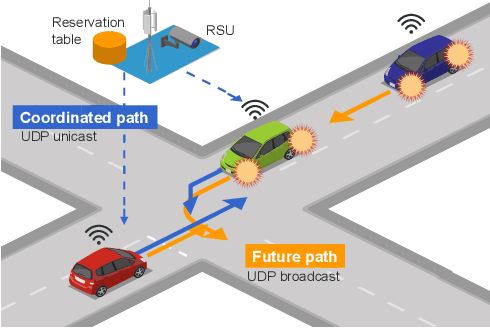

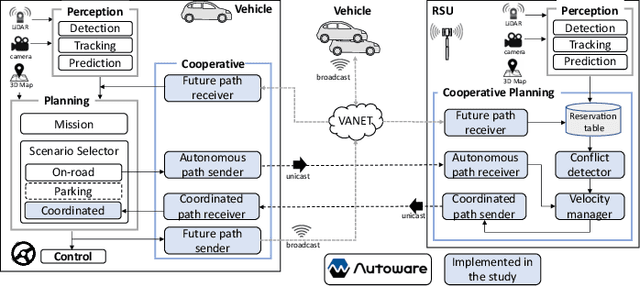
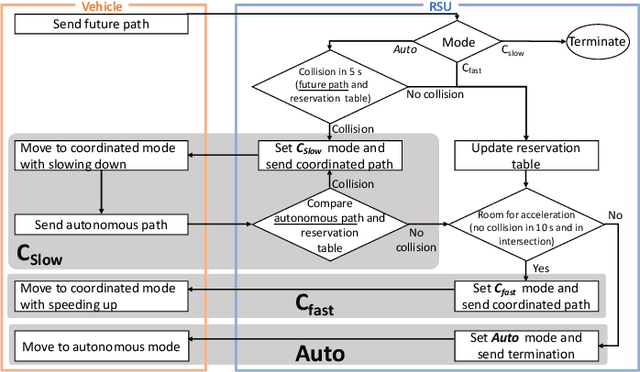
Cooperative intelligent transportation systems (ITS) are used by autonomous vehicles to communicate with surrounding autonomous vehicles and roadside units (RSU). Current C-ITS applications focus primarily on real-time information sharing, such as cooperative perception. In addition to real-time information sharing, self-driving cars need to coordinate their action plans to achieve higher safety and efficiency. For this reason, this study defines a vehicle's future action plan/path and designs a cooperative path-planning model at intersections using future path sharing based on the future path information of multiple vehicles. The notion is that when the RSU detects a potential conflict of vehicle paths or an acceleration opportunity according to the shared future paths, it will generate a coordinated path update that adjusts the speeds of the vehicles. We implemented the proposed method using the open-source Autoware autonomous driving software and evaluated it with the LGSVL autonomous vehicle simulator. We conducted simulation experiments with two vehicles at a blind intersection scenario, finding that each car can travel safely and more efficiently by planning a path that reflects the action plans of all vehicles involved. The time consumed by introducing the RSU is 23.0 % and 28.1 % shorter than that of the stand-alone autonomous driving case at the intersection.