 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Thinking Pixel: Recursive Sparse Reasoning in Multimodal Diffusion Latents
Apr 28, 2026Diffusion models have achieved success in high-fidelity data synthesis, yet their capacity for more complex, structured reasoning like text following tasks remains constrained. While advances in language models have leveraged strategies such as latent reasoning and recursion to enhance text understanding capabilities, extending these to multimodal text-to-image generation tasks is challenging due to the continuous and non-discrete nature of visual tokens. To tackle this problem, we draw inspiration from modular human cognition and propose a recursive, sparse mixture-of-experts framework integrated into conventional diffusion models. Our approach introduces a recursive component within joint attention layers that iteratively refines visual tokens over multiple latent steps while efficiently sharing parameters via sparse selection of neural modules. At each step, a gating network is devised to dynamically select specialized neural modules, conditioned on the current visual tokens, the diffusion timestep, and the conditioning information. Comprehensive evaluation on class-conditioned ImageNet image generation tasks and additional studies on the GenEval and DPG benchmark demonstrate the superiority of the proposed method in enhancing model image generation performance.
Temporal-Aware Heterogeneous Graph Reasoning with Multi-View Fusion for Temporal Question Answering
Feb 23, 2026Question Answering over Temporal Knowledge Graphs (TKGQA) has attracted growing interest for handling time-sensitive queries. However, existing methods still struggle with: 1) weak incorporation of temporal constraints in question representation, causing biased reasoning; 2) limited ability to perform explicit multi-hop reasoning; and 3) suboptimal fusion of language and graph representations. We propose a novel framework with temporal-aware question encoding, multi-hop graph reasoning, and multi-view heterogeneous information fusion. Specifically, our approach introduces: 1) a constraint-aware question representation that combines semantic cues from language models with temporal entity dynamics; 2) a temporal-aware graph neural network for explicit multi-hop reasoning via time-aware message passing; and 3) a multi-view attention mechanism for more effective fusion of question context and temporal graph knowledge. Experiments on multiple TKGQA benchmarks demonstrate consistent improvements over multiple baselines.
Prompt Reinjection: Alleviating Prompt Forgetting in Multimodal Diffusion Transformers
Feb 06, 2026Multimodal Diffusion Transformers (MMDiTs) for text-to-image generation maintain separate text and image branches, with bidirectional information flow between text tokens and visual latents throughout denoising. In this setting, we observe a prompt forgetting phenomenon: the semantics of the prompt representation in the text branch is progressively forgotten as depth increases. We further verify this effect on three representative MMDiTs--SD3, SD3.5, and FLUX.1 by probing linguistic attributes of the representations over the layers in the text branch. Motivated by these findings, we introduce a training-free approach, prompt reinjection, which reinjects prompt representations from early layers into later layers to alleviate this forgetting. Experiments on GenEval, DPG, and T2I-CompBench++ show consistent gains in instruction-following capability, along with improvements on metrics capturing preference, aesthetics, and overall text--image generation quality.
Reinforcement Learning Enhanced Multi-hop Reasoning for Temporal Knowledge Question Answering
Jan 03, 2026Temporal knowledge graph question answering (TKGQA) involves multi-hop reasoning over temporally constrained entity relationships in the knowledge graph to answer a given question. However, at each hop, large language models (LLMs) retrieve subgraphs with numerous temporally similar and semantically complex relations, increasing the risk of suboptimal decisions and error propagation. To address these challenges, we propose the multi-hop reasoning enhanced (MRE) framework, which enhances both forward and backward reasoning to improve the identification of globally optimal reasoning trajectories. Specifically, MRE begins with prompt engineering to guide the LLM in generating diverse reasoning trajectories for a given question. Valid reasoning trajectories are then selected for supervised fine-tuning, serving as a cold-start strategy. Finally, we introduce Tree-Group Relative Policy Optimization (T-GRPO), a recursive, tree-structured learning-by-exploration approach. At each hop, exploration establishes strong causal dependencies on the previous hop, while evaluation is informed by multi-path exploration feedback from subsequent hops. Experimental results on two TKGQA benchmarks indicate that the proposed MRE-based model consistently surpasses state-of-the-art (SOTA) approaches in handling complex multi-hop queries. Further analysis highlights improved interpretability and robustness to noisy temporal annotations.
Detection of Global Anomalies on Distributed IoT Edges with Device-to-Device Communication
Jul 16, 2024



Anomaly detection is an important function in IoT applications for finding outliers caused by abnormal events. Anomaly detection sometimes comes with high-frequency data sampling which should be carried out at Edge devices rather than Cloud. In this paper, we consider the case that multiple IoT devices are installed in a single remote site and that they collaboratively detect anomalies from the observations with device-to-device communications. For this, we propose a fully distributed collaborative scheme for training distributed anomaly detectors with Wireless Ad Hoc Federated Learning, namely "WAFL-Autoencoder". We introduce the concept of Global Anomaly which sample is not only rare to the local device but rare to all the devices in the target domain. We also propose a distributed threshold-finding algorithm for Global Anomaly detection. With our standard benchmark-based evaluation, we have confirmed that our scheme trained anomaly detectors perfectly across the devices. We have also confirmed that the devices collaboratively found thresholds for Global Anomaly detection with low false positive rates while achieving high true positive rates with few exceptions.
Remembering Transformer for Continual Learning
Apr 11, 2024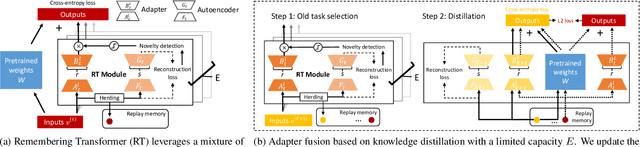
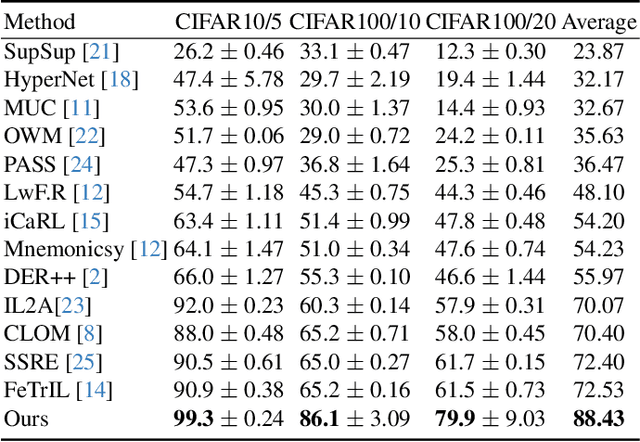
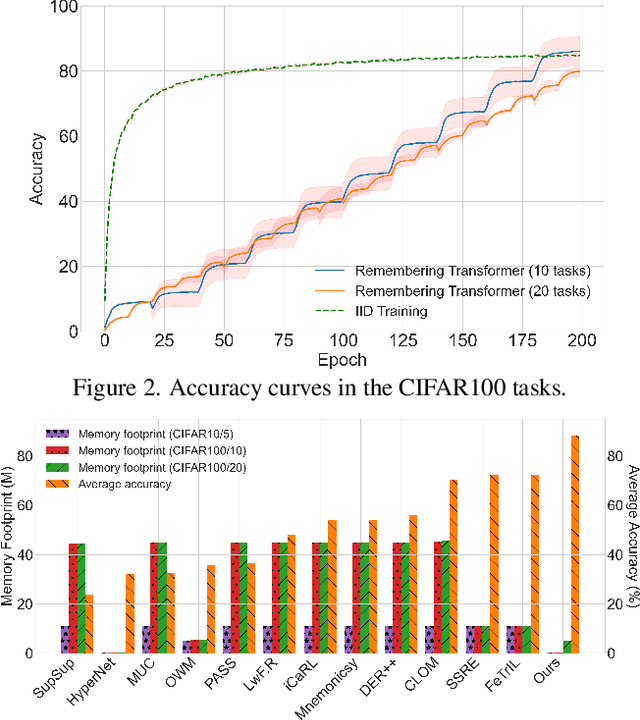

Neural networks encounter the challenge of Catastrophic Forgetting (CF) in continual learning, where new task knowledge interferes with previously learned knowledge. We propose Remembering Transformer, inspired by the brain's Complementary Learning Systems (CLS), to tackle this issue. Remembering Transformer employs a mixture-of-adapters and a generative model-based routing mechanism to alleviate CF by dynamically routing task data to relevant adapters. Our approach demonstrated a new SOTA performance in various vision continual learning tasks and great parameter efficiency.
Associative Transformer Is A Sparse Representation Learner
Sep 22, 2023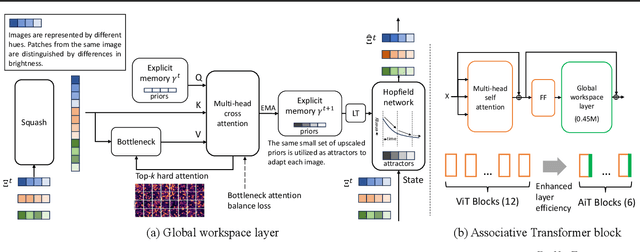
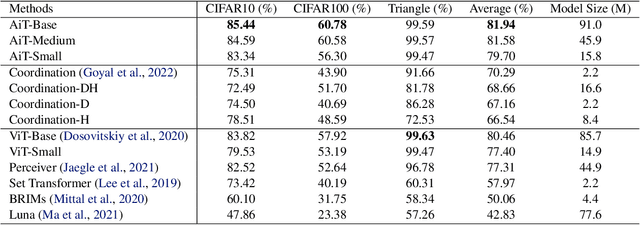
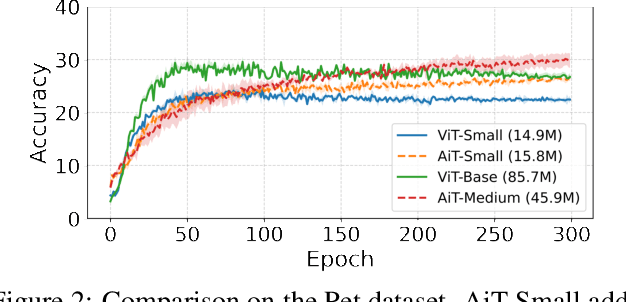
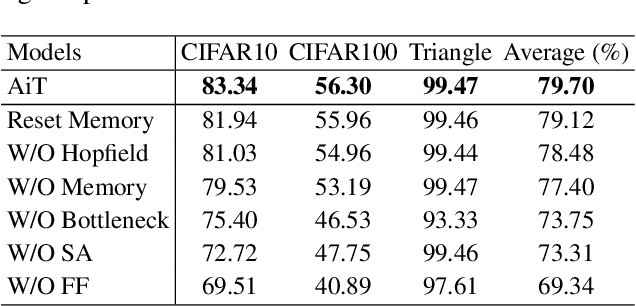
Emerging from the monolithic pairwise attention mechanism in conventional Transformer models, there is a growing interest in leveraging sparse interactions that align more closely with biological principles. Approaches including the Set Transformer and the Perceiver employ cross-attention consolidated with a latent space that forms an attention bottleneck with limited capacity. Building upon recent neuroscience studies of Global Workspace Theory and associative memory, we propose the Associative Transformer (AiT). AiT induces low-rank explicit memory that serves as both priors to guide bottleneck attention in the shared workspace and attractors within associative memory of a Hopfield network. Through joint end-to-end training, these priors naturally develop module specialization, each contributing a distinct inductive bias to form attention bottlenecks. A bottleneck can foster competition among inputs for writing information into the memory. We show that AiT is a sparse representation learner, learning distinct priors through the bottlenecks that are complexity-invariant to input quantities and dimensions. AiT demonstrates its superiority over methods such as the Set Transformer, Vision Transformer, and Coordination in various vision tasks.
Meta Neural Coordination
May 20, 2023Meta-learning aims to develop algorithms that can learn from other learning algorithms to adapt to new and changing environments. This requires a model of how other learning algorithms operate and perform in different contexts, which is similar to representing and reasoning about mental states in the theory of mind. Furthermore, the problem of uncertainty in the predictions of conventional deep neural networks highlights the partial predictability of the world, requiring the representation of multiple predictions simultaneously. This is facilitated by coordination among neural modules, where different modules' beliefs and desires are attributed to others. The neural coordination among modular and decentralized neural networks is a fundamental prerequisite for building autonomous intelligence machines that can interact flexibly and adaptively. In this work, several pieces of evidence demonstrate a new avenue for tackling the problems above, termed Meta Neural Coordination. We discuss the potential advancements required to build biologically-inspired machine intelligence, drawing from both machine learning and cognitive science communities.
Instance-level Trojan Attacks on Visual Question Answering via Adversarial Learning in Neuron Activation Space
Apr 02, 2023Malicious perturbations embedded in input data, known as Trojan attacks, can cause neural networks to misbehave. However, the impact of a Trojan attack is reduced during fine-tuning of the model, which involves transferring knowledge from a pretrained large-scale model like visual question answering (VQA) to the target model. To mitigate the effects of a Trojan attack, replacing and fine-tuning multiple layers of the pretrained model is possible. This research focuses on sample efficiency, stealthiness and variation, and robustness to model fine-tuning. To address these challenges, we propose an instance-level Trojan attack that generates diverse Trojans across input samples and modalities. Adversarial learning establishes a correlation between a specified perturbation layer and the misbehavior of the fine-tuned model. We conducted extensive experiments on the VQA-v2 dataset using a range of metrics. The results show that our proposed method can effectively adapt to a fine-tuned model with minimal samples. Specifically, we found that a model with a single fine-tuning layer can be compromised using a single shot of adversarial samples, while a model with more fine-tuning layers can be compromised using only a few shots.
Meta Learning in Decentralized Neural Networks: Towards More General AI
Feb 02, 2023Meta-learning usually refers to a learning algorithm that learns from other learning algorithms. The problem of uncertainty in the predictions of neural networks shows that the world is only partially predictable and a learned neural network cannot generalize to its ever-changing surrounding environments. Therefore, the question is how a predictive model can represent multiple predictions simultaneously. We aim to provide a fundamental understanding of learning to learn in the contents of Decentralized Neural Networks (Decentralized NNs) and we believe this is one of the most important questions and prerequisites to building an autonomous intelligence machine. To this end, we shall demonstrate several pieces of evidence for tackling the problems above with Meta Learning in Decentralized NNs. In particular, we will present three different approaches to building such a decentralized learning system: (1) learning from many replica neural networks, (2) building the hierarchy of neural networks for different functions, and (3) leveraging different modality experts to learn cross-modal representations.