 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProcBench: Benchmark for Multi-Step Reasoning and Following Procedure
Paper and Code



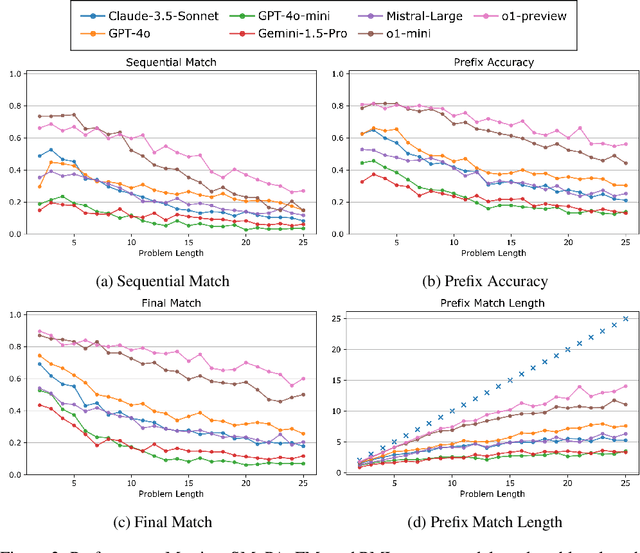
Reasoning is central to a wide range of intellectual activities, and while the capabilities of large language models (LLMs) continue to advance, their performance in reasoning tasks remains limited. The processes and mechanisms underlying reasoning are not yet fully understood, but key elements include path exploration, selection of relevant knowledge, and multi-step inference. Problems are solved through the synthesis of these components. In this paper, we propose a benchmark that focuses on a specific aspect of reasoning ability: the direct evaluation of multi-step inference. To this end, we design a special reasoning task where multi-step inference is specifically focused by largely eliminating path exploration and implicit knowledge utilization. Our dataset comprises pairs of explicit instructions and corresponding questions, where the procedures necessary for solving the questions are entirely detailed within the instructions. This setup allows models to solve problems solely by following the provided directives. By constructing problems that require varying numbers of steps to solve and evaluating responses at each step, we enable a thorough assessment of state-of-the-art LLMs' ability to follow instructions. To ensure the robustness of our evaluation, we include multiple distinct tasks. Furthermore, by comparing accuracy across tasks, utilizing step-aware metrics, and applying separately defined measures of complexity, we conduct experiments that offer insights into the capabilities and limitations of LLMs in reasoning tasks. Our findings have significant implications for the development of LLMs and highlight areas for future research in advancing their reasoning abilities. Our dataset is available at \url{https://huggingface.co/datasets/ifujisawa/procbench} and code at \url{https://github.com/ifujisawa/proc-bench}.